数据结构与算法学习(六)(续)
2016-03-23 00:00
337 查看
摘要: 通过《数据结构与算法分析-C++描述》(第三版),学习数据结构与算法

我们暂时假设所有元素互异,后面着重考虑出现重复元素的情况。
在分割阶段要做的就是把所有小元素移到数组的左边而大元素移到数组的右边。
当i在j的左边时,我们将i右移,移过那些小于枢纽元的元素,并将j左移,移过那些大于枢纽元的元素。当i和j停止时,i指向大元素而j指向小元素。如果i在j的左边,那么将两个元素互换。情况如下:
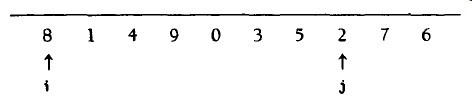
然后交换i和j指向的元素,重复该过程直到i和j彼此交错为止。

此时,i和j已经交错,故不再交换,分割的最后一步将是将枢纽元与i所指向的元素交换。

我们必须考虑的一个重要的细节是如何处理那些等于枢纽元的元素。解决办法是当i或j遇到等于枢纽元的元素时,停止。
下面是执行三数中值分割方法的程序。
下面是快速排序的主程序。
下面对快速排序的小改动,它将中断该算法。
颇具诱惑力的是将第16行到25行换成上面代码,不过这是不能运行的,因为若a[i]=a[j]=pivot,则会产生一个无线循环。
T(N)=T(i)+T(N-i-1)+cN
其中,i=|S1|是S1中的元素个数。我们将考察三种情况。
T(N)=T(N-1)+cN,N>1
结果为T(N)=Ο(N^2)
T(N)=2T(N/2)+cN
由此得到T(N)=cNlogN+N=Ο(NlogN)。

移项合并得到:
NT(N)=(N+1)T(N-1)+2cN
结果得到T(N)=Ο(NlogN)。
如果|S|=1,那么k=1并将S中的元素作为结果返回。如果正在使用小数组的截止方法且|S|≤CUTOFF,则将S排序并返回第k个最小元。
选取枢纽元v∈S。
将集合S-{v}分割成S1和S2,就像快速排序中所做的那样。
如果k≤|S1|,那么第k个最小元必然在S1中。这种情况下,返回quickselect(S1,k)。如果k=1+|S1|,那么枢纽元就是第k个最小元,将它作为结果返回。否则,第k个最小元就在S2中,它是S2中第(k-|S1|-1)个最小元。我们进行一次递归调用并返回quickselect(S2,k-|S1|-1)。
快速选择的最坏情形和快速排序一样,都是Ο(N^2)。程序实现如下:
算法第一步生成一个指针数组。如下图所示:
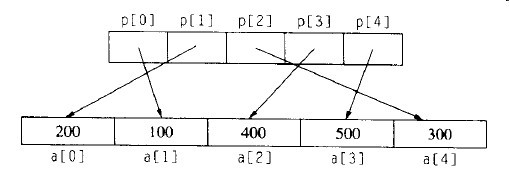
图6-6 使用指针数组排序
我们还需要重排数组a。最简单的方法是定义第二个Comparable数组,称之为copy。然后就可以按正确的顺序将对象写入copy,然后再将copy写回a。这么做的代价是使用一个额外的数组进行2N次Comparable对象的复制。另一个问题是copy导致了双倍的空间需求。而解决办法是建立tmp的滑动算法。下面是存储指向Comparable的指针的类。
下面是对大对象进行排序的算法。
图6-7中的决策树表示将三个元素a、b和c排序的算法。初始状态在根处。

图6-7 三元素排序的决策树
通过只使用比较排序的每一种算法都可以用决策树表示。当然,只有输入数据很少的情况下画决策树才是可行的。
引理6.1 令T是深度为d的二叉树,则T最多有2^d片树叶。
引理6.2 具有L片树叶的二叉树的深度至少是[logL]。
定理6.6 只使用元素间比较的任何排序算法在最坏情形下至少需要[log(N!)]次比较。
定理6.7 只使用元素间比较的任何排序算法需要Ω(NlogN)次比较。
这种类型的下界论断,当用于证明最坏情形结果时,有时叫做信息理论(information-theoretic)。
尽管桶排序看似太一般用处不大,但是实际上却存在许多其输入只是一些小的整数的情况,使用像快速排序这样的排序方法就是小题大作了。

如果M=3,那么在这些顺串构造以后,磁带将包含下图所指出的数据。

我们将每个磁带的第一顺串取出并将两者合并,把结果写到Ta1上。该结果是一个二倍长的顺串。该算法需要[log(N/M)]趟工作,外加一趟初始的顺串构造。


两个顺串合并操作通过将每一个输入磁盘转到每个顺串的开头进行。将输入数据分配到三盘磁带上。

然后,还需要两趟3路合并以完成该排序。

k路合并所需的趟数为[logk(N/M)]。

顺串最初的分配造成了很大的不同。事实上我们给出的最初分配是最优的。
利用这种想法,可以给出一个产生顺串的算法,称为替换选择(replacement selection)。开始,M个记录被读入内存并放到一个优先队列中。我们执行一次deleteMin,把最小值的记录写到输出磁带上,再从输入磁带读入下一个记录。如果它比刚刚写出的记录大,那么可以把它加到优先队列中,否则,不能把它放入当前顺串。由于优先队列少于一个元素,因此,可以把这个新元素存入优先队列的死区(dead space)。
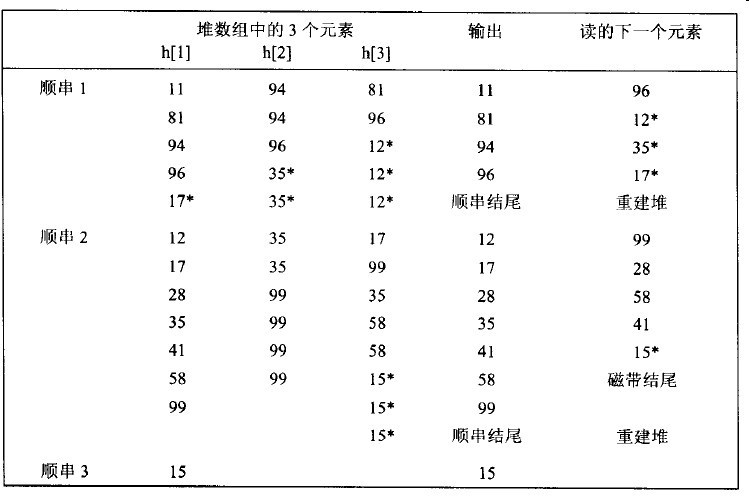
图6-8 顺串构建的例子
6.7.2 分割策略
有几种分割策略,但已知此处描述的分割策略能够给出好的结果。该方法第一步是通过将枢纽元与最后的元素交换使得枢纽元离开要被分割的数据段。i从第一个元素开始从而j从倒数第二个元素开始。下面表示当前的状态。我们暂时假设所有元素互异,后面着重考虑出现重复元素的情况。
在分割阶段要做的就是把所有小元素移到数组的左边而大元素移到数组的右边。
当i在j的左边时,我们将i右移,移过那些小于枢纽元的元素,并将j左移,移过那些大于枢纽元的元素。当i和j停止时,i指向大元素而j指向小元素。如果i在j的左边,那么将两个元素互换。情况如下:
然后交换i和j指向的元素,重复该过程直到i和j彼此交错为止。
此时,i和j已经交错,故不再交换,分割的最后一步将是将枢纽元与i所指向的元素交换。
我们必须考虑的一个重要的细节是如何处理那些等于枢纽元的元素。解决办法是当i或j遇到等于枢纽元的元素时,停止。
6.7.3 小数组
对于很小的数组(N≤20),快速排序不如插入排序好。通常的解决办法是,对于小的数组不递归使用快速排序,而代之以诸如插入排序这样的对小数组有效的排序算法。一个好的截至范围(cutoff range)是N=10。这种做法也避免了一些有害的退化情况,如取三个元素的中值而实际上却只有一个或两个元素的情况。6.7.4 实际的快速排序方法
快速排序的驱动程序如下:[code=plain]/**
* Quicksort algorithm (driver)
*/
template <typename Comparable>
void quicksort( vector<Comparable> & a )
{
quicksort( a, 0, a.size() - 1 );
}下面是执行三数中值分割方法的程序。
[code=plain]/**
* Return median of left, center, and right
* Order these and hide the pivot.
*/
template <typename Comparable>
const Comparable & median3( vector<Comparable> & a, int left, int right )
{
int center = ( left + right ) / 2;
if( a[ center ] < a[ left ] );
swap( a[ left ], a[ center ] );
if( a[ right ] < a[ left ] );
swap( a[ left ], a[ right ] );
if( a[ right ] < a[ center ] );
swap( a[ center ], a[ right ] );
// Place pivot at position right - 1
swap( a[ center ], a[ right - 1 ] );
return a[ right - 1 ];
}下面是快速排序的主程序。
[code=plain]/**
* Internal quicksort method that makes recursive calls.
* Uses median-of-three partitioning and a cutoff of 10.
* a is an array of Comparable items.
* left is the left-most index of the subarray.
* right is the right-root index of the subarray.
*/ s
template <typename Comparable>
void quicksort( vector<Comparable> &a, int left, int right )
{
if( left + 10 <= right )
{
Comparable pivot = median3( a, left, right );
// Begin partitioning
for( ; ; )
{
while( a[ i++ ] < pivot ) { }
while( pivot < a[ --j ] ) { }
if( i < j )
swap( a[ i ], a[ j ] );
else
break;
}
swap( a[ i ], a[ right - 1 ] ); // Restore pivot.
quicksort( a, left, i - 1 ); // Sort small elements
quicksort( a, i + 1, right ); // Sort large elements
}
else // Do an insertion sort on the subarray
insertionSort( a, left, right );
}下面对快速排序的小改动,它将中断该算法。
[code=plain]int i = left + 1, j = right - 2;
for( ; ; )
{
while( a[ i ] < pivot ) i++;
while( pivot < a[ j ] ) j--;
if( i < j )
swap( a[ i ], a[ j ] );
else
break;
}颇具诱惑力的是将第16行到25行换成上面代码,不过这是不能运行的,因为若a[i]=a[j]=pivot,则会产生一个无线循环。
6.7.5 快速排序的分析
正如归并排序那样,快速排序是递归的,因此,分析它需要求解一个递推公式。假设有一个随机的枢纽元(不用三数中值分割法)并对一些小的文件不设截至范围。取T(0)=T(1)=1,快速排序的运行时间等于两个递归调用的运行时间加上花费在分割上的线性时间(枢纽元的选取仅花费常数时间)。我们得到基本的快速排序关系:T(N)=T(i)+T(N-i-1)+cN
其中,i=|S1|是S1中的元素个数。我们将考察三种情况。
6.7.5.1 最坏情形的分析
枢纽元始终是最小元素。此时i=0,忽略T(0)=1,那么递推关系为:T(N)=T(N-1)+cN,N>1
结果为T(N)=Ο(N^2)
6.7.5.2 最佳情形的分析
最佳情形下,枢纽元正好位于中间:T(N)=2T(N/2)+cN
由此得到T(N)=cNlogN+N=Ο(NlogN)。
6.7.5.3 平均情形的分析
这是最困难的部分。我们这里假设对于S1,每个文件的大小都是等可能的,因此每个大小均有概率1/N。移项合并得到:
NT(N)=(N+1)T(N-1)+2cN
结果得到T(N)=Ο(NlogN)。
6.7.6 选择问题的线性期望时间算法
可以修改快速排序以解决选择问题(selection problem)。令|Si|为Si中元素的个数,快速选择的步骤如下:如果|S|=1,那么k=1并将S中的元素作为结果返回。如果正在使用小数组的截止方法且|S|≤CUTOFF,则将S排序并返回第k个最小元。
选取枢纽元v∈S。
将集合S-{v}分割成S1和S2,就像快速排序中所做的那样。
如果k≤|S1|,那么第k个最小元必然在S1中。这种情况下,返回quickselect(S1,k)。如果k=1+|S1|,那么枢纽元就是第k个最小元,将它作为结果返回。否则,第k个最小元就在S2中,它是S2中第(k-|S1|-1)个最小元。我们进行一次递归调用并返回quickselect(S2,k-|S1|-1)。
快速选择的最坏情形和快速排序一样,都是Ο(N^2)。程序实现如下:
[code=plain]/**
* Internal selection method that makes recursive calls.
* Uses median-of-three partitioning and a cutoff of 10.
* a is an array of Comparable items.
* left is the left-most index of the subarray.
* right is the right-most index of the subarray.
* k is the desired rank (1 is minimum) in the entire array.
*/
template <typename Comparable>
void quickSelect( vector<Comparable> & a, int left, int right, int k )
{
if( left + 10 <= right )
{
Comparable pivot = median3( a, left, right );
// Begin partitioning
int i = left, j = right - 1;
for( ; ; )
{
while( a[ ++i ] < pivot ) { }
while( pivot < a[ --j ] ) { }
if( i < j )
swap( a[ i ], a[ j ] );
else
break;
}
swap( a[ i ], a[ right - 1] ); // Restore pivot
// Recurse; only this part changes
if( k <= 1 )
quickSelect( a, left, i - 1, k );
else if( k > i - 1 )
quickSelect( a, i + 1, right, k );
}
else // Do an innertion sort on the subarray
insertionSort( a, left, right );
}6.8 间接排序
一般排序复制Comparable对象的代价很大。解决方案很简单:生成一个指向Comparable的指针数组,然后排列这些指针。一旦确定了元素应该在的位置,就可以直接将该元素放在相应的位置上,而不必进行过多的中间复制操作。这需要使用称为中间置换(in-situ permutation)的算法。算法第一步生成一个指针数组。如下图所示:
图6-6 使用指针数组排序
我们还需要重排数组a。最简单的方法是定义第二个Comparable数组,称之为copy。然后就可以按正确的顺序将对象写入copy,然后再将copy写回a。这么做的代价是使用一个额外的数组进行2N次Comparable对象的复制。另一个问题是copy导致了双倍的空间需求。而解决办法是建立tmp的滑动算法。下面是存储指向Comparable的指针的类。
[code=plain]template <typename Comparable>
{
pubilc:
Pointer( Comparable *rhs = NULL ) : pointee( rhs ) { }
bool operator< ( const Pointer & rhs ) const
{ return *pointee < *rhs.pointee; }
operator Comparable * () const
{ return pointee; }
private:
Comparable *pointee;
}下面是对大对象进行排序的算法。
[code=plain]template <typename Comparable>
void largeObj
7fe8
ectSort( vector<Comparable> & a )
{
vector<Pointer<Comparable> > p( a.size() );
int i, j, nextj;
for( i = 0; i < a.size(); i++ )
p[ i ] = &a[ i ];
quicksort( p );
// Shuffle items in place
for( i = 0; i < a.size(); i++ )
if( p[ i ] != &a[ i ] )
{
Comparable tmp = a[ i ];
for( j = i; p[ j ] != &a[ i ]; j = nextj )
{
nextj = p[ j ] - &a[ 0 ];
a[ j ] = *p[ j ];
p[ j ] = &a[ j ];
}
a[ j ] = tmp;
p[ j ] = &a[ j ];
}
}6.8.1 vector<Comparable*>不运行
基本的思想就是声明指针数组p为vector<Comparable*>,然后调用quicksort(p)来重新排列指针。但这不能运行,问题是需要能够比较两个Comparable*类型的"<"操作符。这样的操作符是存在的,但对所指向的Comparable所存储的值却是什么都不做。6.8.2 智能指针类
这个问题的解决方案是声明一个新的类模板,Pointer。这个类模板将一个指向Comparable的指针作为数据成员来存储,然后可以为Pointer类型添加一个比较操作符。这种类有时候也称为智能指针(smart pointer classes)。6.8.3 重载operator<
实现operator<在概念上来说是简单的。我们仅仅需要将<操作符应用在所指向的Comparable对象就可以了。6.8.4 使用"*"解引用指针
这是C++中的解引用运算符。如果ptr是一个指向对象的指针,那么*ptr就是所指向对象的同义词。6.8.5 重载类型转换操作符
这是类型转换操作符。特别地,这种方法定义了一个从Point<Comparable>到Comparable*的类型转换。6.8.6 随处可见的隐式类型转换
我们可以提供类型转换操作符来禁止隐式类型转换,同时没有对Pointer构造函数使用expicit。6.8.7 双向隐式类型转换会导致歧义
这些类型转换很强大,但会引起很多意想不到的问题。会引发歧义。6.8.8 指针减法是合法的
p1-p2是它们分开的距离。该距离为int类型。6.9 排序算法的一般下界
现在我们证明,任何只用到比较的排序算法在最坏情形下需要Ω(NlogN)次比较,因此归并排序和堆排序在一个常数因子范围内是最优的。这意味着,快速排序在相差一个常数因子的范围内平均是最优的。决策树
决策树(decision tree)是用于证明下界的抽象过程。在这里,决策树是一棵二叉树。每个节点表示元素之间一组可能的排序,它与已经进行的比较相一致。比较的结果是树的边。图6-7中的决策树表示将三个元素a、b和c排序的算法。初始状态在根处。
图6-7 三元素排序的决策树
通过只使用比较排序的每一种算法都可以用决策树表示。当然,只有输入数据很少的情况下画决策树才是可行的。
引理6.1 令T是深度为d的二叉树,则T最多有2^d片树叶。
引理6.2 具有L片树叶的二叉树的深度至少是[logL]。
定理6.6 只使用元素间比较的任何排序算法在最坏情形下至少需要[log(N!)]次比较。
定理6.7 只使用元素间比较的任何排序算法需要Ω(NlogN)次比较。
这种类型的下界论断,当用于证明最坏情形结果时,有时叫做信息理论(information-theoretic)。
6.10 桶排序
在某些情况下以线性时间排序仍然是可能的。桶排序(bucket sort)是其中之一。需附加一些信息。输入数据A1、A2、…、AN,必须只由小于M的正整数组成(显然还可以对其进行扩充)。那么算法是:使用一个大小为M的称为count的数组,它被初始化为全0。于是,count有M个单元(或称桶),这些桶初始化为空。当读Ai时,count[Ai]增1。在所有的输入数据读入后,扫描妙数组count,打印出排序后的表。尽管桶排序看似太一般用处不大,但是实际上却存在许多其输入只是一些小的整数的情况,使用像快速排序这样的排序方法就是小题大作了。
6.11 外部排序
迄今为止,已经考察过的所有算法都需要将输入数据装入主存。而有的应用数据太大装不进内存。因此需要一些外部排序(external sorting)算法。6.11.1 为什么需要新算法
大部分内部排序算法都用到内存可直接寻址的事实。但当输入在磁带上,那么所有这些操作就失去了它们的效率。即使在磁盘上仍有效率的损失。6.11.2 外部排序模型
各种各样的海量存储装置使得外部排序比内部排序对设备的依赖性要严重得多。我们将考虑一些算法在磁带上工作,而磁带可能是最受限制的存储介质。假设至少有三个磁带驱动器进行工作,其中两个驱动器执行有效的排序,而第三个驱动器进行简化工作。如果只有一个驱动器可用,那么任何算法都将要Ω(N^2)次磁带访问。6.11.3 简单算法
基本的外部排序算法使用归并排序中的合并算法。设有4盘磁带Ta1、Ta2、Tb1和Tb2,它们是两盘输入磁带和两盘输出磁带。设数据最初在Ta1上,并设内存可以一次容纳(和排序)M个记录。一种自然的做法是首先从输入磁带一次读入M个记录,在内部将这些记录排序,然后再把排过序的记录交替地写到Tb1或Tb2上。我们把每组排过序的记录叫作一个顺串(run)。如果M=3,那么在这些顺串构造以后,磁带将包含下图所指出的数据。
我们将每个磁带的第一顺串取出并将两者合并,把结果写到Ta1上。该结果是一个二倍长的顺串。该算法需要[log(N/M)]趟工作,外加一趟初始的顺串构造。
6.11.4 多路合并
如果有额外的磁带,那么可以减少将输入数据排序所需要的趟数,通过将基本的(2路)合并扩充为k路合并就能做到这一点。两个顺串合并操作通过将每一个输入磁盘转到每个顺串的开头进行。将输入数据分配到三盘磁带上。
然后,还需要两趟3路合并以完成该排序。
k路合并所需的趟数为[logk(N/M)]。
6.11.5 多相合并
上面讨论的k路合并方法需要使用2k盘磁带,这对某些应用极其不便。只使用k+1盘磁带也可能完成排序工作。下面是三盘磁带如何完成2路合并。顺串最初的分配造成了很大的不同。事实上我们给出的最初分配是最优的。
6.11.6 替换选择
最后我们将要考虑顺串的构造。现在我们用到的策略是所谓的最简可能:读入尽可能多的记录并将他们排序,再把结果写到某个磁带上。而我们认识到:只要第一个记录被写到输出磁带上,它所使用的内存就可以被另外的记录使用。利用这种想法,可以给出一个产生顺串的算法,称为替换选择(replacement selection)。开始,M个记录被读入内存并放到一个优先队列中。我们执行一次deleteMin,把最小值的记录写到输出磁带上,再从输入磁带读入下一个记录。如果它比刚刚写出的记录大,那么可以把它加到优先队列中,否则,不能把它放入当前顺串。由于优先队列少于一个元素,因此,可以把这个新元素存入优先队列的死区(dead space)。
图6-8 顺串构建的例子

相关文章推荐
- C语言 数据结构与算法 线性表
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
- 链表,折磨人的数据结构
- 数据结构课设 家谱处理 (map)
- poj 2777(线段树+区间染色)
- 数据结构 串匹配 好难懂
- 每周数据结构【5】:在二叉树中递归查找为data值的点
- 数据结构顺序表
- HDU 4763 数据结构之KMP+二分
- Python 数据结构与算法——deque(双端队列)
- 重学数据结构系列之——二叉树基础
- 算法与数据结构学习笔记系列——递归(1)
- HDU 4081 次小生成树变形记
- Python 数据结构与算法——拓扑排序
- 数据结构学习笔记02堆栈
- 数据结构——单链表的初操作
- 数据结构第一题线性表的各种操作SqList
- 大话数据结构--第四章 栈与队列
- 经典算法与数据结构的c++实现——快速排序
- 数据结构学习路线+笔记