Jedis源码解析(ShardedJedis)
2016-03-22 20:26
225 查看
1 Sharding机制
sharding机制:即通常所说的“分片”,允许数据存放在不同的物理机器上, 以适应数据量过大的场景,克服单台机器内存或者磁盘空间的限制。Redis并不支持服务器端分片(redis3.0开始支持了),不过我们可以使用Jedis提供的API来实现客户端的分片,通过“一致性hash”算法,使得数据离散地存放在不同的服务器上面。2 ShardedJedis类的结构
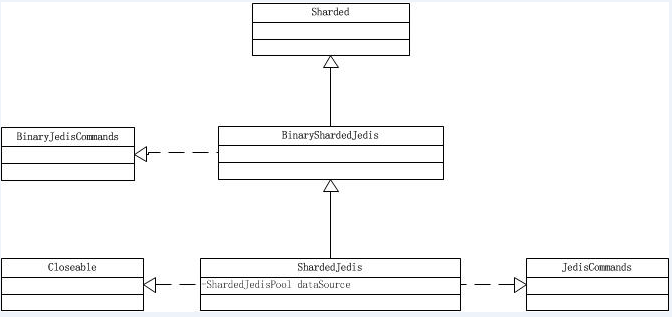
3 ShardedJedis类解析
先上代码: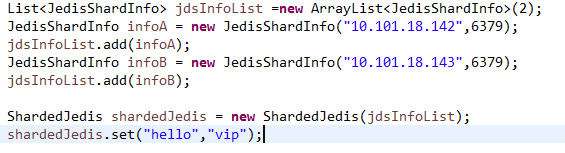
(1)初始化ShardedJedis
目前在jedis 2.2.1中提供4个初始化方法,其Hashing参数可以指定hash算法,SharderJedis默认采用64位的MurmurHash算法(了炸天的算法),但是也提供了MD5算法
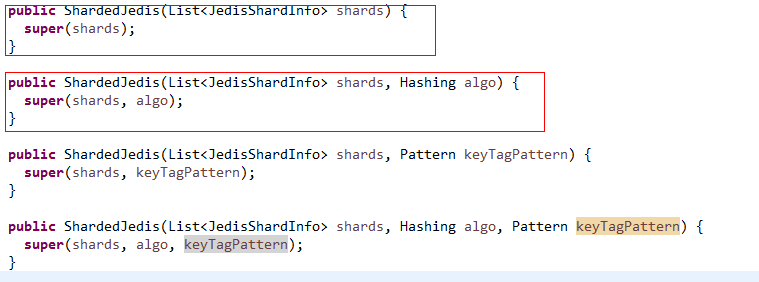
继续深入SharderJedis的构造方法调用了Sharded类的构造方法,在Sharded方法中:
1 定义了一个TreeMap ,TreeMap 用于存储虚拟节点(在初始化方法中,将每台服务器节点采用hash算法划分为160个(默认的,DEFAULT_WEIGHT)虚拟节点(当然也可以配置划分权重)
2 定义一个LinkedHashMap,用于存储每一个Redis服务器的物理连接
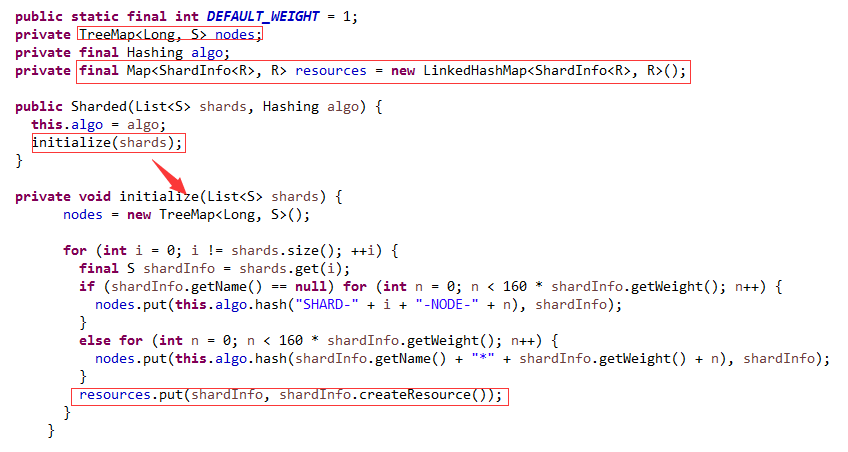
其中shardInfo的createResource就是物理连接信息
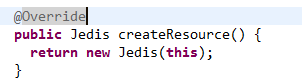
(2)使用ShardedJedis操作数据的过程
怎么进行数据的操作呢?其一般过程就是根据key获取key对应的Jedis信息,然后再进行数据的操作!
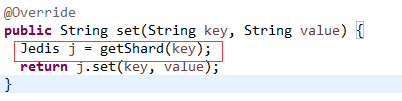
那么是如何根据key确定对应的Jedis信息的呢?
在上面我们知道resources(LinkedHashMap)用于存储每一个Redis服务器的物理连接,其key为shardedInfo对象,value为Jedis实例,因此只需要根据shardedInfo对象就可以找到jedis实例。那么怎么获取对应key的shardedInfo对象呢?
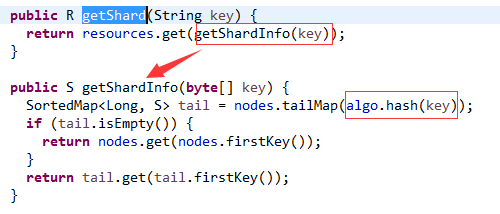
做法是这样的:
1)对于key采用与初始化时同样的hash(MurmurHash或者MD5)算法,然后从TreeMap获取大于等于键hash值得节点,取最邻近节点;
2)当key的hash值大于虚拟节点hash值得最大值时(也就是tail为空),取第一个虚拟节点。

相关文章推荐
- HDU 2123 An easy problem
- CF IndiaHack B 深度优先搜索
- 用shell简单处理文本的例子
- 安卓中onBackPressed ()方法的使用
- LightOj 1231 Coin Change (I)(部分背包)
- Raspberry PI3(树莓派)第一课:Tomcat+pi4j远程控制led
- 夜课后的明月
- 第四周项目3-随机数应用于游戏
- 贪心算法1之1016
- 安卓开发常见错误原因及解决方法
- iOS开发模式之单例模式
- kafka源码解析之一kafka诞生的背景
- hdu5125(LIS)
- poj3624 Charm Bracelet(01背包)
- c#多维数组
- <fieldset>和<legend>标签的使用
- Only the original thread that created a view hierarchy can touch its views.
- Linux apache安装
- “结对编程”心得体会
- 多个控件跑马灯效果