手写字体识别 --MNIST数据集
2016-03-22 18:03
609 查看
Matlab 手写字体识别
忙过这段时间后,对于上次读取的Matlab内部数据实现的识别,我回味了一番,觉得那个实在太小。所以打算把数据换成[MNIST数据集][1]。基础思想还是相同的,使用TreeBagger(随机森林)的算法来训练样本,从而实现学习并且识别。这一次不会和上次那么草率了….同时分享一些关于TreeBagger的理解。
思想
和我上一个识别花是一样的。使用算法训练训练样本,得到一个模型model,从而使用predict函数根据模型对测试样本进行识别。从而达到手写字体识别的效果。这里我使用了Google实验室的Corinna Cortes和纽约大学柯朗研究所的Yann LeCun的建有一个手写数字数据库,训练库有60,000张手写数字图像,测试库有10,000张。
这是->Mnist数据集官网<-上面有说明。
但是因为这个网站上的四个文件资源似乎不多,导致下载速度很慢,所以我把他们放在我的云盘里,给大家下载。云盘链接 密码:7awp
因为里面的内容全部是用二进制存的,所以我在的文件里也顺便把解压的.m的文件放进去了,也省得大家到处找。
代码实现
因为要导入的图片太多,一开始我使用imread时我发现,imread似乎是按照一个特定的文件名顺序读取文件的,所以对于我这些有顺序的图片,他不能按照顺序读。所以我自己想了个方法来读取60000张训练样本。
for i=1:60000
str = strcat('C:\Users\StevenT\Desktop\mnist数据集\train-images-idx3-ubyte\TrainImage_',num2str(i));
name = strcat(str,'.bmp');
name = char(name);
current_img = imread(name); %将当前图片赋值给一个变量
current_img = reshape(current_img,1,[]); %将矩阵变形
train_image(i,:) = current_img;
end之后用同样的方法获得10000个测试样本。
对于测试标签和训练标签的读取,直接用textread来读取就可以了。
lable_test = textread('C:\Users\StevenT\Desktop\mnist数据集\t10k-labels-idx1-ubyte\test_lable.txt');读取到样本和标签之后,对样本和标签进行训练。
model = TreeBagger(500,train_image,lable_train); %使用TreeBagger来对训练样本进行训练,获得一个model result = predict(model,test_image); %之后使用model来对测试样本进行预测,将结果存在result内 result = cell2mat(result); %因为result是cell类的,使用cell2mat转换成字符串
最后输出识别率
sc=double(result) - lable_test; count=sum(sc(:)==48)/100.0; %sc用来保存相减的结果,当其等于0(ASCII里是48)的时候就是识别正确的结果,最终得出识别率
整体代码
clear all;
clc;
%导入训练样本
for i=1:60000
str = strcat('C:\Users\StevenT\Desktop\mnist数据集\train-images-idx3-ubyte\TrainImage_',num2str(i));
name = strcat(str,'.bmp');
name = char(name);
current_img = imread(name);
current_img = reshape(current_img,1,[]); %将矩阵变形
train_image(i,:) = current_img;
end
train_image=double(train_image);
%导入测试样本
for i=1:10000
str = strcat('C:\Users\StevenT\Desktop\mnist数据集\t10k-images-idx3-ubyte\TestImage_',num2str(i));
name = strcat(str,'.bmp');
name = char(name);
current_img = imread(name);
current_img = reshape(current_img,1,[]); %将矩阵变形
test_image(i,:) = current_img;
end
test_image=double(test_image);
lable_test = textread('C:\Users\StevenT\Desktop\mnist数据集\t10k-labels-idx1-ubyte\test_lable.txt');
lable_train = textread('C:\Users\StevenT\Desktop\mnist数据集\train-labels-idx1-ubyte\train_lable.txt');
% lable_train = lable_train(1:100);
% lable_test = lable_test(1:100);
model = TreeBagger(500,train_image,lable_train); %使用TreeBagger来对训练样本进行训练,获得一个model result = predict(model,test_image); %之后使用model来对测试样本进行预测,将结果存在result内 result = cell2mat(result); %因为result是cell类的,使用cell2mat转换成字符串
sc=double(result) - lable_test; count=sum(sc(:)==48)/100.0; %sc用来保存相减的结果,当其等于0(ASCII里是48)的时候就是识别正确的结果,最终得出识别率
这里请大家把地址改成自己的地址。
这是运行后的工作区
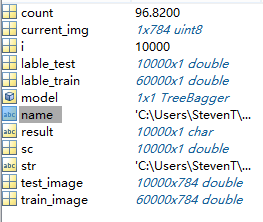
count是识别的准确率,已经达到96.82%了
我的在TreeBagger里用了50棵决策树,同时我也尝试过500棵,讲真跑的很久,但是准确率却只提高了1%,所以我认识到这个决策树的个数是没很大影响的…(我的电脑跑的心好累)
这个例子中最重要的莫过于随机森林TreeBagger这个函数所以我在这里发一份博客,我觉得挺好懂的一份(好吧其实是因为有图)
http://www.36dsj.com/archives/21036
关于算法的问题吧,我觉得如果不是想搞算法开发的,还是会用就好:)
以上就是我做的一个小小的手写识别,后面我会把我的用GUI把自己手写的数字识别出来的小补充发出来。同时呢,正在学习SVM ,过段时间学的好的话,我会这个也发出来~~
大家共勉:)

相关文章推荐
- flash 系统字体显示问题
- C#及WPF获取本机所有字体和颜色的方法
- 谈谈网页设计中的字体应用Font Set
- PDF里的文字显示模糊的解决方法
- 保证可下载的漂亮动作2008奥运比赛项目字体
- C#实现字体旋转的方法
- 网页设计中的 serif 和 sans-serif字体应用
- 优化WordPress的Google字体以加速国内服务器上的运行
- C#实现缩放字体的方法
- 解析在main函数之前调用函数以及对设计的作用详解
- ExtJs默认的字体大小改变的几种方法(自己整理)
- 一个实现字体大中小方法的JavaScript代码
- jquery实现实时改变网页字体大小、字体背景色和颜色的方法
- 详解Matlab中 sort 函数用法
- php修改NetBeans默认字体的大小
- java和matlab画多边形闭合折线图示例讲解
- 如何解决修改StaticText的字体
- asp.net调用系统设置字体文本框的方法
- C#调用Matlab生成的dll方法的详细说明
- C#读取系统字体颜色与大小的方法