HashMap的工作原理
2016-03-22 17:28
246 查看
首页
开源项目
问答
代码
博客
翻译
资讯
移动开发
招聘
城市圈
当前访客身份:游客 [ 登录 | 加入开源中国 ]
当前访客身份: 游客 [ 登录 | 加入开源中国 ]
软件

boxiZen

关注此人
关注(3) 粉丝(3) 积分(15)
记录点滴,记录成长 博客移植至:boxizen.github.io
.发送私信.请教问题
博客分类
算法与数据结构(0)
JavaSE(3)
J2EE(0)
SSH(0)
Web前端(2)
Js(1)
设计模式(1)
数据库(0)
Linux(0)
转贴的文章(2)
读书笔记(0)
阅读排行
1. HashMap的工作原理
2. Java垃圾回收机制浅谈
3. 2014找工作总结-机会往往留给有准备的人
4. 最牛B的编码套路
5. 设计模式--六大设计原则总结
6. HTML5基础知识(1)---认识基本标记
7. jQuery中bind方法与live方法区别
8. Java注解学习总结
最新评论
@boxiZen:引用来自“peterpanzsy”的评论赞!写的很清楚,... 查看»
@peterpanzsy:赞!写的很清楚,比其他文章清楚多了 查看»
@豆粥:lz求职目标很明确啊,很早拿到自己心意的offer。... 查看»
@with_you:引用来自“曾柏羲”的评论 引用来自“with_you”... 查看»
@boxiZen:引用来自“with_you”的评论 这两个方法已经不推... 查看»
@with_you:这两个方法已经不推荐使用,高版本已经废除。liv...查看»
@boxiZen:引用来自“loveOSworld”的评论 编程更在于人,而... 查看»
@loveOSworld:编程更在于人,而不是代码。 查看»
@boxiZen:引用来自“Hero_Fly”的评论 有点乱 嗯,我再好好... 查看»
@boxiZen:引用来自“雅典娜拉”的评论 stack是栈吧?heap是... 查看»
访客统计
今日访问:8
昨日访问:12
本周访问:20
本月访问:222
所有访问:2970
空间 » 博客 »
JavaSE
算法与数据结构
J2EE
SSH
Web前端
Js
设计模式
数据库
Linux
转贴的文章
读书笔记
所有分类
发表于2年前(2013-11-20 16:07) 阅读(1633) | 评论(2) 43人收藏此文章, 我要收藏
赞1

HashMap是近些年来java面试中常问到的知识点,很多人(包括我在内)都知道HashMap的用法,也知道HashMap与HashTable之间的区别,但是却不知其所以然,于是乎,本人开始查阅相关资料,解读HashMap的实现源代码,打算一探究竟。
与HashTable的区别:HashMap可以近似地看成是HashTable,但是它是非线程安全的,并且允许使用null键和null值,而这些都与HashTable恰巧相反。注:HashMap可以使用ConcurrentHashMap代替,ConcurrentHashMap是一个线程安全,更加快速的HashMap,欲了解ConcurrentHashMap,可点击http://www.blogjava.net/wuxufeng8080/articles/152238.html
存储结构:HashMap的存储结构其实就是哈希表的存储结构(由数组与链表结合组成,称为链表的数组)。如下图所示:
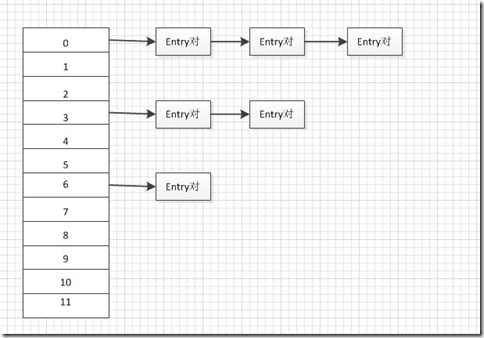
如上图所示,HashMap中元素存储的形式是键-值对(key-value对,即Entry对),所有具有相同hashcode值的键(key)所对应的entry对会被链接起来组成一条链表,而数组的作用则是存储链表中第一个结点的地址值。
桶(buckets):上图中的标有0、1、2、3、….、11所对应的数组空间就是一个个桶。
加载因子(load factor):是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认值是0.75。
根据源代码中所述,影响HashMap性能有两个因素:哈希表中的初始化容量(桶的数量)和加载因子。当哈希表中条目数超过了当前容量与加载因子的乘积时,哈希表将会作出自我调整,将容量扩充为原来的两倍,并且重新将原有的元素重新映射到表中,这一过程成为rehash。看到这里,相必大家会发现rehash操作是会造成时间与空间的开销的,因此为什么初始化容量与加载因子会影响HashMap的性能也就可以理解了。
代码示例1.添加键-值对的java源代码:
expand
source
代码示例2.扩充HashMap实例容量源代码:
expand
source
代码示例3.put方法的java源代码:
expand
source
正如上述代码所示,HashMap通过key值的hashcode获得了对应的bucket存储空间的下标,然后进入bucket空间,通过链表遍历的方式逐个查询,看看链表中是否已经存在了这个key的键-值对,如果已经存在则用新值替换旧值,否则插入新的键-值对。看到这里,相信大家会发现,hashCode值相同的两个值可能是不同的两个对象,而当put进去的是另一个hashCode值相等的对象时,会发生冲突,而在HashMap中解决这种冲突的方法就是将hashCode值相同的key值所对应的key-value对串联成一条链表,请见上面的HashMap数据结构图。
get操作:HashMap在进行get操作的时候,与put方法类似,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值,找到bucket的位置后,再通过key.equals()方法找到对应的键-值对,从而获得对应的value值。java源代码如下:
代码示例4.get方法的java源代码:
expand
source
总结:HashMap是基于hashing原理对key-value对进行存储与获取,当使用put()方法添加key-value对时,它会首先检查hashCode的值,并以此获得对应的bucket位置进行存储,当发生冲突时(hashcode值相同的两个不同key),新的key-value对会以结点的形式添加到链表的末尾。而使用get()方法时,同样地会根据key的hashCode值找到相应的bucket位置,再通过key.equals()方法找到对应的key-value对,最终成功获取value值。
分享到:


1赞
声明:OSCHINA 博客文章版权属于作者,受法律保护。未经作者同意不得转载。
« 上一篇
下一篇 »
开源项目
问答
代码
博客
翻译
资讯
移动开发
招聘
城市圈
当前访客身份:游客 [ 登录 | 加入开源中国 ]
当前访客身份: 游客 [ 登录 | 加入开源中国 ]
软件
boxiZen
关注此人
关注(3) 粉丝(3) 积分(15)
记录点滴,记录成长 博客移植至:boxizen.github.io
.发送私信.请教问题
博客分类
算法与数据结构(0)
JavaSE(3)
J2EE(0)
SSH(0)
Web前端(2)
Js(1)
设计模式(1)
数据库(0)
Linux(0)
转贴的文章(2)
读书笔记(0)
阅读排行
1. HashMap的工作原理
2. Java垃圾回收机制浅谈
3. 2014找工作总结-机会往往留给有准备的人
4. 最牛B的编码套路
5. 设计模式--六大设计原则总结
6. HTML5基础知识(1)---认识基本标记
7. jQuery中bind方法与live方法区别
8. Java注解学习总结
最新评论
@boxiZen:引用来自“peterpanzsy”的评论赞!写的很清楚,... 查看»
@peterpanzsy:赞!写的很清楚,比其他文章清楚多了 查看»
@豆粥:lz求职目标很明确啊,很早拿到自己心意的offer。... 查看»
@with_you:引用来自“曾柏羲”的评论 引用来自“with_you”... 查看»
@boxiZen:引用来自“with_you”的评论 这两个方法已经不推... 查看»
@with_you:这两个方法已经不推荐使用,高版本已经废除。liv...查看»
@boxiZen:引用来自“loveOSworld”的评论 编程更在于人,而... 查看»
@loveOSworld:编程更在于人,而不是代码。 查看»
@boxiZen:引用来自“Hero_Fly”的评论 有点乱 嗯,我再好好... 查看»
@boxiZen:引用来自“雅典娜拉”的评论 stack是栈吧?heap是... 查看»
访客统计
今日访问:8
昨日访问:12
本周访问:20
本月访问:222
所有访问:2970
空间 » 博客 »
JavaSE
算法与数据结构
J2EE
SSH
Web前端
Js
设计模式
数据库
Linux
转贴的文章
读书笔记
所有分类
原 HashMap的工作原理
发表于2年前(2013-11-20 16:07) 阅读(1633) | 评论(2) 43人收藏此文章, 我要收藏赞1
HashMap是近些年来java面试中常问到的知识点,很多人(包括我在内)都知道HashMap的用法,也知道HashMap与HashTable之间的区别,但是却不知其所以然,于是乎,本人开始查阅相关资料,解读HashMap的实现源代码,打算一探究竟。
一、HashMap的基本了解
基本定义:根据源代码的描述可知,HashMap是基于哈希表的Map接口的实现,其包含了Map接口的所有映射操作,并且允许使用null键和null值。与HashTable的区别:HashMap可以近似地看成是HashTable,但是它是非线程安全的,并且允许使用null键和null值,而这些都与HashTable恰巧相反。注:HashMap可以使用ConcurrentHashMap代替,ConcurrentHashMap是一个线程安全,更加快速的HashMap,欲了解ConcurrentHashMap,可点击http://www.blogjava.net/wuxufeng8080/articles/152238.html
存储结构:HashMap的存储结构其实就是哈希表的存储结构(由数组与链表结合组成,称为链表的数组)。如下图所示:
如上图所示,HashMap中元素存储的形式是键-值对(key-value对,即Entry对),所有具有相同hashcode值的键(key)所对应的entry对会被链接起来组成一条链表,而数组的作用则是存储链表中第一个结点的地址值。
二、影响HashMap性能的因素
在HashMap中,还存在着两个概念,桶(buckets)和加载因子(load factor)。桶(buckets):上图中的标有0、1、2、3、….、11所对应的数组空间就是一个个桶。
加载因子(load factor):是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认值是0.75。
根据源代码中所述,影响HashMap性能有两个因素:哈希表中的初始化容量(桶的数量)和加载因子。当哈希表中条目数超过了当前容量与加载因子的乘积时,哈希表将会作出自我调整,将容量扩充为原来的两倍,并且重新将原有的元素重新映射到表中,这一过程成为rehash。看到这里,相必大家会发现rehash操作是会造成时间与空间的开销的,因此为什么初始化容量与加载因子会影响HashMap的性能也就可以理解了。
代码示例1.添加键-值对的java源代码:
expand
source
代码示例2.扩充HashMap实例容量源代码:
expand
source
三、put/get方法实现原理
put操作:HashMap在进行put操作的时候,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值以便存放数据。具体操作可以参照如下的java源代码:代码示例3.put方法的java源代码:
expand
source
正如上述代码所示,HashMap通过key值的hashcode获得了对应的bucket存储空间的下标,然后进入bucket空间,通过链表遍历的方式逐个查询,看看链表中是否已经存在了这个key的键-值对,如果已经存在则用新值替换旧值,否则插入新的键-值对。看到这里,相信大家会发现,hashCode值相同的两个值可能是不同的两个对象,而当put进去的是另一个hashCode值相等的对象时,会发生冲突,而在HashMap中解决这种冲突的方法就是将hashCode值相同的key值所对应的key-value对串联成一条链表,请见上面的HashMap数据结构图。
get操作:HashMap在进行get操作的时候,与put方法类似,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值,找到bucket的位置后,再通过key.equals()方法找到对应的键-值对,从而获得对应的value值。java源代码如下:
代码示例4.get方法的java源代码:
expand
source
总结:HashMap是基于hashing原理对key-value对进行存储与获取,当使用put()方法添加key-value对时,它会首先检查hashCode的值,并以此获得对应的bucket位置进行存储,当发生冲突时(hashcode值相同的两个不同key),新的key-value对会以结点的形式添加到链表的末尾。而使用get()方法时,同样地会根据key的hashCode值找到相应的bucket位置,再通过key.equals()方法找到对应的key-value对,最终成功获取value值。
分享到:
1赞
声明:OSCHINA 博客文章版权属于作者,受法律保护。未经作者同意不得转载。
« 上一篇
下一篇 »

相关文章推荐
- p
- Swift之下标脚本
- Oracle中使用Order By排序时结果顺序不稳定的解决办法
- model中 setData()函数 flag()函数作用
- JVM 问题排查常用工具
- mycncart后台列表筛选、分页怎么做
- 函数授权
- banner广告页
- 简单的锁键盘锁鼠标的C++病毒代码
- CodeMirror sql智能提示功能修改
- Eclipse设置server的编码
- 矩阵的性能指标
- Unity3D UGUI之DoTweenAnimation脚本控制动画方法
- sqlmap
- 博客园搬家到CSDN
- 利用exe4j制作exe文件
- iOS App UI设计、切图规范
- java中成员访问修饰符,接口与抽象类相关知识
- OpenMax
- JavaScript垃圾回收机制