详解二叉查找树算法的实现
2016-03-20 21:49
309 查看
详解二叉查找树算法的实现
http://blog.csdn.net/npy_lp/article/details/7426431
2012-04-06 13:32 22486人阅读 评论(14) 收藏 举报
分类:
基本算法(10)
版权声明:本文为博主原创文章,未经博主允许不得转载。
参考文献: 《数据结构(C语言版)》 严蔚敏 吴伟民 编著
开发平台:Ubuntu11.04
编译器:gcc version4.5.2 (Ubuntu/Linaro 4.5.2-8ubuntu4)
树(Tree)是n(n≥0)个结点的有限集。在任意一棵非空树中:(1)有且仅有一个特定的被称为根(Root)的结点;(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
结点拥有的子树数称为结点的度(Degree)。度为0的结点称为叶子(Leaf)或终端结点。度不为0的结点称为非终端结点或分支结点。
树的度是树内各结点的度的最大值。
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)。
结点的层次(Level)是从根结点开始计算起,根为第一层,根的孩子为第二层,依次类推。树中结点的最大层次称为树的深度(Depth)或高度。
如果将树中结点的各子树看成从左至右是有次序的(即不能互换),则称该树为有序树,否则称为无序树。
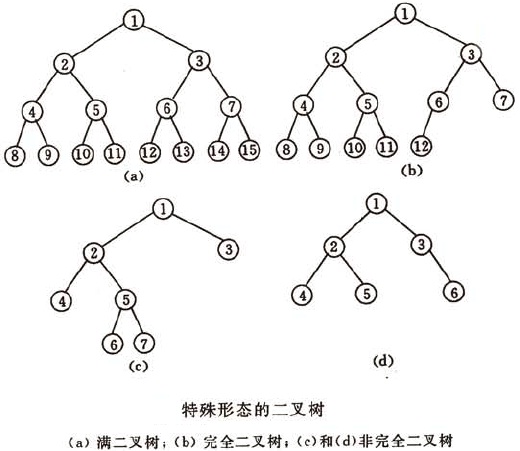
1、二叉树
二叉树(Binary Tree)的特点是每个结点至多具有两棵子树(即在二叉树中不存在度大于2的结点),并且子树之间有左右之分。
二叉树的性质:
(1)、在二叉树的第i层上至多有2i-1个结点(i≥1)。
(2)、深度为k的二叉树至多有2k-1个结点(k≥1)。
(3)、对任何一棵二叉树,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。
一棵深度为k且有2k-1个结点的二叉树称为满二叉树。
可以对满二叉树的结点进行连续编号,约定编号从根结点起,自上而下,自左至右,则由此可引出完全二叉树的定义。深度为k且有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1到n的结点一一对应时,称之为完全二叉树。
(4)、具有n个结点的完全二叉树的深度为不大于log2n的最大整数加1。
(5)、如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到最后一层,每层从左到右),则对任一结点i(1≤i≤n),有
a、如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲是结点x(其中x是不大于i/2的最大整数)。
b、如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2i。
c、如果2i+1>n,则结点i无右孩子;否则其右孩子是结点2i+1。
二叉树的链式存储:
链式二叉树中的每个结点至少需要包含三个域,数据域和左、右指针域。

二叉树的遍历:
假如以L、D、R分别表示遍历左子树、访问根结点和遍历右子树,则可有DLR、DRL、LRD、LDR、RLD、RDL这六种遍历二叉树的方案。若限定先左后右,则只有三种方案,分别称之为先(根)序遍历、中(根)序遍历和后(根)序遍历,它们以访问根结点的次序来区分。
2、二叉查找树
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
(1)、若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值;
(2)、若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值;
(3)、它的左、右子树也分别为二叉查找树。
3、二叉查找树的基本运算
[cpp] view
plain copy
/* bst - binary search/sort tree
* by Richard Tang <tanglinux@gmail.com>
*/
#include <stdio.h>
#include <stdlib.h>
typedef int data_type;
typedef struct bst_node {
data_type data;
struct bst_node *lchild, *rchild;
}bst_t, *bst_p;
(1)、插入
在二叉查找树中插入新结点,要保证插入新结点后仍能满足二叉查找树的性质。例子中的插入过程如下:
a、若二叉查找树root为空,则使新结点为根;
b、若二叉查找树root不为空,则通过search_bst_for_insert函数寻找插入点并返回它的地址(若新结点中的关键字已经存在,则返回空指针);
c、若新结点的关键字小于插入点的关键字,则将新结点插入到插入点的左子树中,大于则插入到插入点的右子树中。
[cpp] view
plain copy
static bst_p search_bst_for_insert(bst_p *root, data_type key)
{
bst_p s, p = *root;
while (p) {
s = p;
if (p->data == key)
return NULL;
p = (key < p->data) ? p->lchild : p->rchild;
}
return s;
}
void insert_bst_node(bst_p *root, data_type data)
{
bst_p s, p;
s = malloc(sizeof(struct bst_node));
if (!s)
perror("Allocate dynamic memory");
s -> data = data;
s -> lchild = s -> rchild = NULL;
if (*root == NULL)
*root = s;
else {
p = search_bst_for_insert(root, data);
if (p == NULL) {
fprintf(stderr, "The %d already exists.\n", data);
free(s);
return;
}
if (data < p->data)
p->lchild = s;
else
p->rchild = s;
}
}
(2)、遍历
[cpp] view
plain copy
static int print(data_type data)
{
printf("%d ", data);
return 1;
}
int pre_order_traverse(bst_p root, int (*visit)(data_type data))
{
if (root) {
if (visit(root->data))
if (pre_order_traverse(root->lchild, visit))
if (pre_order_traverse(root->rchild, visit))
return 1;
return 0;
}
else
return 1;
}
int post_order_traverse(bst_p root, int (*visit)(data_type data))
{
if (root) {
if (post_order_traverse(root->lchild, visit))
if (visit(root->data))
if (post_order_traverse(root->rchild, visit))
return 1;
return 0;
}
else
return 1;
}
中序遍历二叉查找树可得到一个关键字的有序序列。
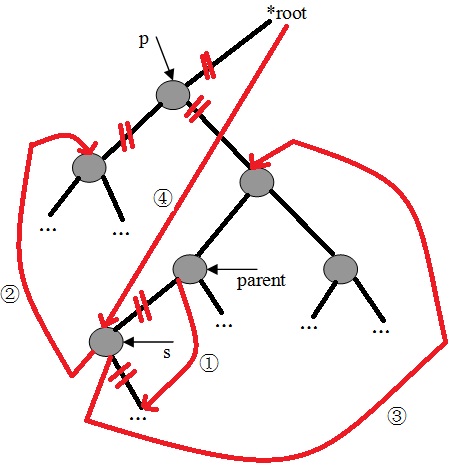
(3)、删除
删除某个结点后依然要保持二叉查找树的特性。例子中的删除过程如下:
a、若删除点是叶子结点,则设置其双亲结点的指针为空。
b、若删除点只有左子树,或只有右子树,则设置其双亲结点的指针指向左子树或右子树。
c、若删除点的左右子树均不为空,则:
1)、查询删除点的右子树的左子树是否为空,若为空,则把删除点的左子树设为删除点的右子树的左子树。
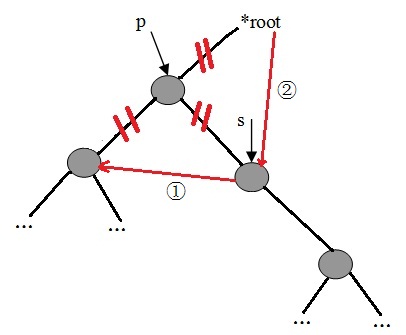
2)、若不为空,则继续查询左子树,直到找到最底层的左子树为止。
[cpp] view
plain copy
void delete_bst_node(bst_p *root, data_type data)
{
bst_p p = *root, parent, s;
if (!p) {
fprintf(stderr, "Not found %d.\n", data);
return;
}
if (p->data == data) {
/* It's a leaf node */
if (!p->rchild && !p->lchild) {
*root = NULL;
free(p);
}
/* the right child is NULL */
else if (!p->rchild) {
*root = p->lchild;
free(p);
}
/* the left child is NULL */
else if (!p->lchild) {
*root = p->rchild;
free(p);
}
/* the node has both children */
else {
s = p->rchild;
/* the s without left child */
if (!s->lchild)
s->lchild = p->lchild;
/* the s have left child */
else {
/* find the smallest node in the left subtree of s */
while (s->lchild) {
/* record the parent node of s */
parent = s;
s = s->lchild;
}
parent->lchild = s->rchild;
s->lchild = p->lchild;
s->rchild = p->rchild;
}
*root = s;
free(p);
}
}
else if (data > p->data) {
delete_bst_node(&(p->rchild), data);
}
else if (data < p->data) {
delete_bst_node(&(p->lchild), data);
}
}
4、二叉查找树的查找分析
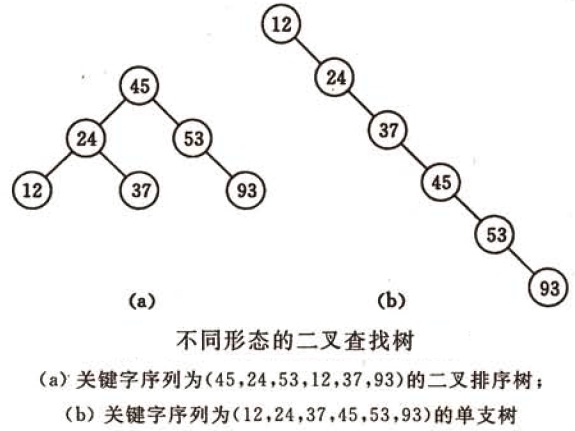
同样的关键字,以不同的插入顺序,会产生不同形态的二叉查找树。
[cpp] view
plain copy
int main(int argc, char *argv[])
{
int i, num;
bst_p root = NULL;
if (argc < 2) {
fprintf(stderr, "Usage: %s num\n", argv[0]);
exit(-1);
}
num = atoi(argv[1]);
data_type arr[num];
printf("Please enter %d integers:\n", num);
for (i = 0; i < num; i++) {
scanf("%d", &arr[i]);
insert_bst_node(&root, arr[i]);
}
printf("\npre order traverse: ");
pre_order_traverse(root, print);
printf("\npost order traverse: ");
post_order_traverse(root, print);
printf("\n");
delete_bst_node(&root, 45);
printf("\npre order traverse: ");
pre_order_traverse(root, print);
printf("\npost order traverse: ");
post_order_traverse(root, print);
printf("\n");
return 0;
}
运行两次,以不同的顺序输入相同的六个关键字:
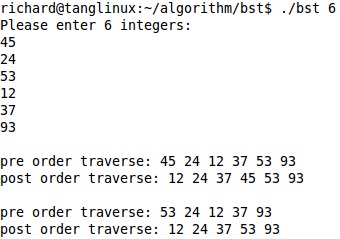

根据前序遍历的结果可得到两次运行所产生的二叉查找树的形态并不相同,如下图:
顶
4
踩
0
上一篇Linux进程管理之进程的终止
下一篇算法库之二:libredblack的交叉编译
我的同类文章
基本算法(10)•算法库之三:libcprops的交叉编译2012-04-08阅读1820
•详解Linux内核红黑树算法的实现2012-04-11阅读15342
•算法库之一:libhashish的交叉编译2012-03-23阅读1396
•详解Linux内核双向循环链表算法的实现(下)2012-02-27阅读3202
•例解单链表的基本运算(下)2012-02-25阅读880
•算法库之二:libredblack的交叉编译2012-04-07阅读1311
•散列表的基本概念及其运算2012-03-26阅读6624
•Linux内核中的PID散列表实例2012-03-27阅读4034
•详解Linux内核双向循环链表算法的实现(上)2012-02-27阅读2312
猜你在找
《C语言/C++学习指南》加密解密篇(安全相关算法)
C语言系列之 快速排序与全排列算法
Ceph—分布式存储系统的另一个选择
4.7.存储类&作用域&生命周期&链接属性-C语言高级专题第7部分
Cocos2d-x 3.x高级视频教程:ObjC、Swift、C++、Java交互
查看评论
8楼 云峦雾绕 2016-01-26 09:59发表 [回复]

int (*visit)(data_type data)
可能是我太鶸了这种定义形参的方法没有用过,可以给点资料看看么。。。这样的形参定义是什么意思。。。
Re: tanglinux 2016-02-23 15:56发表 [回复]

回复bochuan007:就是一个指针,函数指针。
7楼 jielidu 2016-01-22 15:51发表 [回复]

http://www.algolist.net/Data_structures/Binary_search_tree/Removal
这个里面讲解删除部分,挺好理解的。
6楼 倔强的攻城狮 2015-11-05 16:11发表 [回复]

楼主的节点操作图是用什么工具画的呀?
Re: tanglinux 2015-11-06 09:13发表 [回复]
回复Quyuan2009:开始菜单“附件”里的“画图”工具。
Re: 倔强的攻城狮 2015-11-07 22:33发表 [回复]
回复npy_lp:厉害,完全专业画工的节奏
5楼 dijkstral 2015-07-11 09:41发表 [回复]

博主你的删除节点的方法比较精妙,但是和算法导论中的不一样啊。
4楼 baidu_28619017 2015-06-01 16:44发表 [回复]

经过调试,在我依次插入 1 2 3后,用pre_dst_traverse函数打印时候,出现仅打印一个数的错误,深度没有错
这里我经思考理解,LZ的思路是,可以实现自己编写的对数据的处理程序,在遍历时候,若不符合某些条件即刻弹出遍历
修改如下:
int pre_dst_traverse(bst_p s,void(*fun)(type_data data){
if(!s) return 1; //仅仅弹出当次栈,不影响遍历继续
if(fun(s->data)){
if(pre_dst_traverse(s->lchild,fun){
if(pre_dst_traverse(s->rchild,fun){
return 1; //依旧不影响
}
}
return 0;
}
else return 0; //重点在这,当fun返回0后,往之前的栈返回0,接着按照传递性,立即弹出所有栈,终止递归
}
3楼 h1031565585 2015-05-11 21:46发表 [回复]

好复杂啊,看不懂
2楼 TeddyBear777 2015-05-09 05:30发表 [回复]

int post_order_traverse(bst_p root, int (*visit)(data_type data))
写错了吧,你实现的是in_order_traverse.
Re: tanglinux 2015-05-17 17:30发表 [回复]
回复a714833738:你说的没错,是中序遍历。
1楼 sicoso 2014-03-08 22:41发表 [回复]

b、若删除点只有左子树,或只有右子树,则设置其双亲结点的指针指向左子树或右子树。
这里没看懂,请问:若被删除节点只有右子树,他的双亲节点同时有左子树(被删除节点)和右子树,那怎么设置其双亲节点指向右子树?
我是菜鸟,,,所以可能问的很笨。。
Re: tanglinux 2014-03-08 23:18发表 [回复]
回复sicoso:双亲节点的右子树保持不变。
这句话更准确地描述为“b、若删除点只有左子树,或只有右子树,则让其双亲结点原指向该删除点的指针指向这个删除点的左子树或右子树。”。
Re: sicoso 2014-03-09 09:40发表 [回复]
回复npy_lp:噢,谢谢,刚刚理解错了。
发表评论
用 户 名:
zkl99999
叉查找树--插入、删除、查找
二叉查找树是满足以下条件的二叉树:1.左子树上的所有节点值均小于根节点值,2右子树上的所有节点值均不小于根节点值,3,左右子树也满足上述两个条件。二叉查找树的插入过程如下:1.若当前的二叉查找树为空,则插入的元素为根节点,2.若插入的元素值小于根节点值,则将元素插入到左子树中,3.若插入的元素值不小于根节点值,则将元素插入到右子树中。
二叉查找树的删除,分三种情况进行处理:
1.p为叶子节点,直接删除该节点,再修改其父节点的指针(注意分是根节点和不是根节点),如图a。
2.p为单支节点(即只有左子树或右子树)。让p的子树与p的父亲节点相连,删除p即可;(注意分是根节点和不是根节点);如图b。
3.p的左子树和右子树均不空。找到p的后继y,因为y一定没有左子树,所以可以删除y,并让y的父亲节点成为y的右子树的父亲节点,并用y的值代替p的值;或者方法二是找到p的前驱x,x一定没有右子树,所以可以删除x,并让x的父亲节点成为y的左子树的父亲节点。如图c。



插入节点的代码:

struct node
{
int val;
pnode lchild;
pnode rchild;
};
pnode BT = NULL;
//递归方法插入节点
pnode insert(pnode root, int x)
{
pnode p = (pnode)malloc(LEN);
p->val = x;
p->lchild = NULL;
p->rchild = NULL;
if(root == NULL){
root = p;
}
else if(x < root->val){
root->lchild = insert(root->lchild, x);
}
else{
root->rchild = insert(root->rchild, x);
}
return root;
}
//非递归方法插入节点
void insert_BST(pnode q, int x)
{
pnode p = (pnode)malloc(LEN);
p->val = x;
p->lchild = NULL;
p->rchild = NULL;
if(q == NULL){
BT = p;
return ;
}
while(q->lchild != p && q->rchild != p){
if(x < q->val){
if(q->lchild){
q = q->lchild;
}
else{
q->lchild = p;
}
}
else{
if(q->rchild){
q = q->rchild;
}
else{
q->rchild = p;
}
}
}
return;
}查找节点的代码:
pnode search_BST(pnode p, int x)
{
bool solve = false;
while(p && !solve){
if(x == p->val){
solve = true;
}
else if(x < p->val){
p = p->lchild;
}
else{
p = p->rchild;
}
}
if(p == NULL){
cout << "没有找到" << x << endl;
}
return p;
}删除节点的代码
bool delete_BST(pnode p, int x) //返回一个标志,表示是否找到被删元素
{
bool find = false;
pnode q;
p = BT;
while(p && !find){ //寻找被删元素
if(x == p->val){ //找到被删元素
find = true;
}
else if(x < p->val){ //沿左子树找
q = p;
p = p->lchild;
}
else{ //沿右子树找
q = p;
p = p->rchild;
}
}
if(p == NULL){ //没找到
cout << "没有找到" << x << endl;
}
if(p->lchild == NULL && p->rchild == NULL){ //p为叶子节点
if(p == BT){ //p为根节点
BT = NULL;
}
else if(q->lchild == p){
q->lchild = NULL;
}
else{
q->rchild = NULL;
}
free(p); //释放节点p
}
else if(p->lchild == NULL || p->rchild == NULL){ //p为单支子树
if(p == BT){ //p为根节点
if(p->lchild == NULL){
BT = p->rchild;
}
else{
BT = p->lchild;
}
}
else{
if(q->lchild == p && p->lchild){ //p是q的左子树且p有左子树
q->lchild = p->lchild; //将p的左子树链接到q的左指针上
}
else if(q->lchild == p && p->rchild){
q->lchild = p->rchild;
}
else if(q->rchild == p && p->lchild){
q->rchild = p->lchild;
}
else{
q->rchild = p->rchild;
}
}
free(p);
}
else{ //p的左右子树均不为空
pnode t = p;
pnode s = p->lchild; //从p的左子节点开始
while(s->rchild){ //找到p的前驱,即p左子树中值最大的节点
t = s;
s = s->rchild;
}
p->val = s->val; //把节点s的值赋给p
if(t == p){
p->lchild = s->lchild;
}
else{
t->rchild = s->lchild;
}
free(s);
}
return find;
}标签: 数据结构
好文要顶 关注我 收藏该文


爱也玲珑
关注 - 0
粉丝 - 20
+加关注
2
0
(请您对文章做出评价)
« 上一篇:最小生成树(prime算法、kruskal算法)
和 最短路径算法(floyd、dijkstra)
» 下一篇:二分查找小技巧
posted @ 2012-03-27 18:00 爱也玲珑 阅读(13488)
评论(5) 编辑 收藏
评论
#1楼 2013-08-28
15:20 | 北天帝君
if(root == NULL){
}
中
支持(0)反对(0)
#2楼 2014-04-11
16:12 | ┌LiHoo┐
支持(0)反对(0)
#3楼 2014-08-12
15:33 | 洪荒大侠
演示节点删除的例子说的感觉有点儿不清楚,究竟是删除哪个节点?
支持(0)反对(0)
#4楼 2014-08-12
15:35 | 洪荒大侠
感觉删除节点的程序有些模糊
支持(0)反对(0)
#5楼 2015-11-20
22:10 | sjtuzcc
pnode是什么意思?怎么直接用它来创建指向node的指针?

相关文章推荐
- Servlet生命周期与工作原理
- BZOJ3993 星际战争(最大流)
- javaweb学习之Http协议
- Http协议
- Hibernate逍遥游记-第13章 映射实体关联关系-003单向多对多
- 利息的后续要求
- 主要几个浏览器的内核是什么
- UVA 10895——Matrix Transpose
- 选择排序
- Java开发流程自动化(svn+maven+nexus+jenkins) --自动编译,持续集成,测试,打包,发布/部署
- [Chromium中文文档]多进程资源加载
- android中Martix中的数学原理
- Java客户端C++服务端Socket交互通信
- Hibernate Tools for Eclipse的使用
- 从头到尾彻底解析Hash表算法
- SQL SERVER-identity | @@identity | scope_identity
- 博客园环境测试
- 利用Spring AOP 更新memcached 缓存策略的实现(一)
- Lucene 加权的值
- Spark读取数据库(Mysql)的四种方式讲解