Spark运行模式及原理(一)
2016-03-19 19:47
369 查看
Spark的运行模式多种多样,灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布式模式运行;而当以分布式集群的方式部署时,也有众多的运行模式可供选择,这取决于集群的实际情况,底层的资源调度既可以依赖于外部的资源调度框架,也可以使用Spark内建的Standalone模式。对于外部资源调度框架的支持,目前的实现包括相对稳定的Mesos模式,以及还在持续开发更新中的Hadoop YARN模式。
1.Spark运行模式概述
Spark运行模式列表
在实际应用中,Spark应用程序的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要依赖辅助的程序接口来配合使用,目前所支持的MASTER环境变量由特定的字符串或URL所组成,如下所示。
Local
:本地模式,使用N个线程。
Local cluster[worker, core, Memory]:伪分布式模式,可以配置所需要启动的虚拟工作节点的数量,以及每个工作节点所管理的CPU数量和内存尺寸。
Spark://hostname:port:Standalone模式,需要部署Spark到相关节点,URL为Spark Master主机地址和端口。
Mesos://hostname:port:Mesos模式,需要部署Spark和Mesos到相关节点,URL为Mesos主机地址和端口。
YARN standalone/Yarn cluster:YARN模式一,主程序逻辑和任务都运行在YARN集群中。
YARN client:YARN模式二,主程序逻辑运行在本地,具体任务运行在YARN集群中。
此外还有一些用于调试的URL,因为和应用无关,我们在这里就不列举了。
Spark基本工作流程
看到这么多的部署和运行模式,读者大概会想,其内部的逻辑是否也同样会是错综复杂的呢?其实这些运行模式尽管表面上看起来差异很大,但总体上来说,都基于一个相似的工作流程。它们从根本上都是将Spark的应用分为任务调度和任务执行两个部分,如图1所示的是在分布式模式下,Spark的各个调度和执行模块的大致框架图。对于本地模式来说,其内部程序逻辑结构也是类似的,只是其中部分模块有所简化,例如集群管理模块简化为进程内部的线程池。
从图1中可以看到,所有的Spark应用程序都离不开SparkContext和Executor两部分,Executor负责执行任务,运行Executor的机器称为Worker节点,SparkContext由用户程序启动,通过资源调度模块和Executor通信。SparkContext和Executor这两部分的核心代码实现在各种运行模式中都是公用的,在它们之上,根据运行部署模式的不同,包装了不同调度模块以及相关的适配代码。
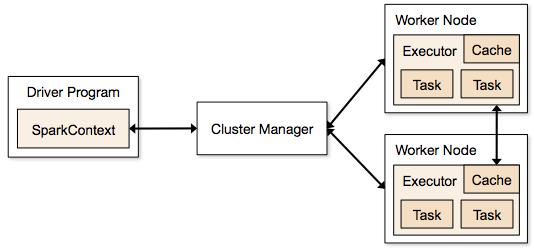
图1 基本框架
具体来说,以SparkContext为程序运行的总入口,在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业调度和TaskScheduler任务调度两级调度模块。
其中作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
作业调度模块和具体的部署运行模式无关,在各种运行模式下逻辑相同,因此在这不做过多介绍。
不同运行模式的区别主要体现在任务调度模块。不同的部署和运行模式,根据底层资源调度方式的不同,各自实现了自己特定的任务调度模块,用来将任务实际调度给对应的计算资源。
相关基本类
TaskScheduler / SchedulerBackend
为了抽象出一个公共的接口供DAGScheduler作业调度模块使用,所有的这些运行模式实现的任务调度模块都是基于这两个接口(Trait)的:TaskScheduler(见程序1)及SchedulerBackend(见程序2)。
程序1
private[spark] trait TaskScheduler {
def rootPool: Pool
def schedulingMode: SchedulingMode
def start(): Unit
def postStartHook() { }
def stop(): Unit
// 提交待运行的任务集
def submitTasks(taskSet: TaskSet): Unit
// 取消一个调度阶段的所有任务
def cancelTasks(stageId: Int, interruptThread: Boolean)
// 设置DAG scheduler 用来回调相关函数
def setDAGScheduler(dagScheduler: DAGScheduler): Unit
// 默认的并行度,作为决定作业并行度的一个参考
def defaultParallelism(): Int
}
TaskScheduler的实现主要用于与DAGScheduler交互,负责任务的具体调度和运行,其核心接口是submitTasks和cancelTasks。
程序2
private[spark] trait SchedulerBackend {
def start(): Unit
def stop(): Unit
def reviveOffers(): Unit
def defaultParallelism(): Int
def killTask(taskId: Long, executorId: String, interruptThread: Boolean): Unit =
throw new UnsupportedOperationException
}
SchedulerBackend的实现是与底层资源调度系统交互(如Mesos/YARN),配合TaskScheduler实现具体任务执行所需的资源分配,核心接口是receiveOffers。
这两者之间的实际交互过程取决于具体调度模式,理论上这两者的实现是成对匹配工作的,之所以拆分成两部分,是有利于相似的调度模式共享代码功能模块。
TaskSchedulerImpl
TaskSchedulerImpl实现了TaskScheduler接口,提供了大多数本地和分布式运行调度模式的任务调度接口。
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging
此外它还实现了resourceOffers和statusUpdate这两个接口供Backend调用,用于提供调度资源和更新任务状态。
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]]
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer)
另外,在提交任务和更新状态等阶段,TaskSchedulerImpl都会调用Backend的receiveOffers函数,用于发起一次任务资源调度请求 。
Executor
实际任务的运行,最终都由Executor类来执行,Executor对每一个任务创建一个TaskRunner类,交给线程池运行,如程序3所示。
程序3
// 启动线程池
val threadPool = Utils.newDaemonCachedThreadPool("Executor task launch worker")
// 运行任务列表
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner]
def launchTask(context: ExecutorBackend, taskId: Long, serializedTask: ByteBuffer) {
val tr = new TaskRunner(context, taskId, serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
运行的结果通过ExecutorBackend接口返回。
private[spark] trait ExecutorBackend {
def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer)
}
图2列出了各种运行模式下相关类的关系图,在接下来的内容中我们将对各种运行模式进行详细的介绍。
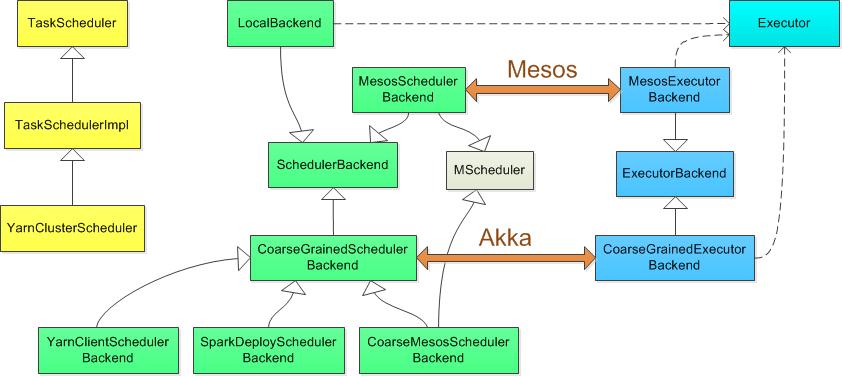
图2各种运行模式相关类图
2.Local模式
部署及程序运行
Local模式,顾名思义就是在本地运行,如果不加任何配置,Spark默认设置为Local模式。以SparkPi为例,Local模式下的应用程序的启动命令如下:
./bin/run-example org.apache.spark.examples.SparkPi local
在SparkPi代码的具体实现中,是根据用户传入的参数来选择运行模式的(如上例的Local),如果需要自己在代码中指定运行模式,可以通过在代码中配置Master为Local来实现,如程序4所示。
程序4
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf()
.setMaster("local")
.setAppName("My application")
.set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
当然,为了使应用程序能够更灵活地在各种部署环境下使用,不建议把与运行环境相关的设置直接在代码中写死。
内部实现原理
Local本地模式使用LocalBackend配合TaskSchedulerImpl,内部逻辑结构如图3所示。
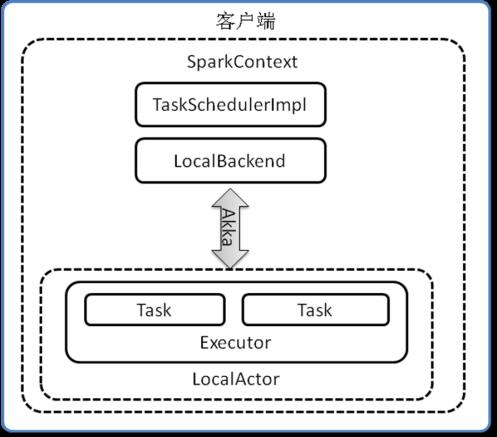
图3 Local模式逻辑结构框图
LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值
直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现。
因为Local模式无须配置,同时所有的代码都在本地进程中执行,所以常常可以作为快速验证代码和跟踪调试的手段。
本文摘自《Spark大数据处理技术》
1.Spark运行模式概述
Spark运行模式列表
在实际应用中,Spark应用程序的运行模式取决于传递给SparkContext的MASTER环境变量的值,个别模式还需要依赖辅助的程序接口来配合使用,目前所支持的MASTER环境变量由特定的字符串或URL所组成,如下所示。
Local
:本地模式,使用N个线程。
Local cluster[worker, core, Memory]:伪分布式模式,可以配置所需要启动的虚拟工作节点的数量,以及每个工作节点所管理的CPU数量和内存尺寸。
Spark://hostname:port:Standalone模式,需要部署Spark到相关节点,URL为Spark Master主机地址和端口。
Mesos://hostname:port:Mesos模式,需要部署Spark和Mesos到相关节点,URL为Mesos主机地址和端口。
YARN standalone/Yarn cluster:YARN模式一,主程序逻辑和任务都运行在YARN集群中。
YARN client:YARN模式二,主程序逻辑运行在本地,具体任务运行在YARN集群中。
此外还有一些用于调试的URL,因为和应用无关,我们在这里就不列举了。
Spark基本工作流程
看到这么多的部署和运行模式,读者大概会想,其内部的逻辑是否也同样会是错综复杂的呢?其实这些运行模式尽管表面上看起来差异很大,但总体上来说,都基于一个相似的工作流程。它们从根本上都是将Spark的应用分为任务调度和任务执行两个部分,如图1所示的是在分布式模式下,Spark的各个调度和执行模块的大致框架图。对于本地模式来说,其内部程序逻辑结构也是类似的,只是其中部分模块有所简化,例如集群管理模块简化为进程内部的线程池。
从图1中可以看到,所有的Spark应用程序都离不开SparkContext和Executor两部分,Executor负责执行任务,运行Executor的机器称为Worker节点,SparkContext由用户程序启动,通过资源调度模块和Executor通信。SparkContext和Executor这两部分的核心代码实现在各种运行模式中都是公用的,在它们之上,根据运行部署模式的不同,包装了不同调度模块以及相关的适配代码。
图1 基本框架
具体来说,以SparkContext为程序运行的总入口,在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业调度和TaskScheduler任务调度两级调度模块。
其中作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。而任务调度模块则负责具体启动任务、监控和汇报任务运行情况。
作业调度模块和具体的部署运行模式无关,在各种运行模式下逻辑相同,因此在这不做过多介绍。
不同运行模式的区别主要体现在任务调度模块。不同的部署和运行模式,根据底层资源调度方式的不同,各自实现了自己特定的任务调度模块,用来将任务实际调度给对应的计算资源。
相关基本类
TaskScheduler / SchedulerBackend
为了抽象出一个公共的接口供DAGScheduler作业调度模块使用,所有的这些运行模式实现的任务调度模块都是基于这两个接口(Trait)的:TaskScheduler(见程序1)及SchedulerBackend(见程序2)。
程序1
private[spark] trait TaskScheduler {
def rootPool: Pool
def schedulingMode: SchedulingMode
def start(): Unit
def postStartHook() { }
def stop(): Unit
// 提交待运行的任务集
def submitTasks(taskSet: TaskSet): Unit
// 取消一个调度阶段的所有任务
def cancelTasks(stageId: Int, interruptThread: Boolean)
// 设置DAG scheduler 用来回调相关函数
def setDAGScheduler(dagScheduler: DAGScheduler): Unit
// 默认的并行度,作为决定作业并行度的一个参考
def defaultParallelism(): Int
}
TaskScheduler的实现主要用于与DAGScheduler交互,负责任务的具体调度和运行,其核心接口是submitTasks和cancelTasks。
程序2
private[spark] trait SchedulerBackend {
def start(): Unit
def stop(): Unit
def reviveOffers(): Unit
def defaultParallelism(): Int
def killTask(taskId: Long, executorId: String, interruptThread: Boolean): Unit =
throw new UnsupportedOperationException
}
SchedulerBackend的实现是与底层资源调度系统交互(如Mesos/YARN),配合TaskScheduler实现具体任务执行所需的资源分配,核心接口是receiveOffers。
这两者之间的实际交互过程取决于具体调度模式,理论上这两者的实现是成对匹配工作的,之所以拆分成两部分,是有利于相似的调度模式共享代码功能模块。
TaskSchedulerImpl
TaskSchedulerImpl实现了TaskScheduler接口,提供了大多数本地和分布式运行调度模式的任务调度接口。
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging
此外它还实现了resourceOffers和statusUpdate这两个接口供Backend调用,用于提供调度资源和更新任务状态。
def resourceOffers(offers: Seq[WorkerOffer]): Seq[Seq[TaskDescription]]
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer)
另外,在提交任务和更新状态等阶段,TaskSchedulerImpl都会调用Backend的receiveOffers函数,用于发起一次任务资源调度请求 。
Executor
实际任务的运行,最终都由Executor类来执行,Executor对每一个任务创建一个TaskRunner类,交给线程池运行,如程序3所示。
程序3
// 启动线程池
val threadPool = Utils.newDaemonCachedThreadPool("Executor task launch worker")
// 运行任务列表
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner]
def launchTask(context: ExecutorBackend, taskId: Long, serializedTask: ByteBuffer) {
val tr = new TaskRunner(context, taskId, serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
运行的结果通过ExecutorBackend接口返回。
private[spark] trait ExecutorBackend {
def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer)
}
图2列出了各种运行模式下相关类的关系图,在接下来的内容中我们将对各种运行模式进行详细的介绍。
图2各种运行模式相关类图
2.Local模式
部署及程序运行
Local模式,顾名思义就是在本地运行,如果不加任何配置,Spark默认设置为Local模式。以SparkPi为例,Local模式下的应用程序的启动命令如下:
./bin/run-example org.apache.spark.examples.SparkPi local
在SparkPi代码的具体实现中,是根据用户传入的参数来选择运行模式的(如上例的Local),如果需要自己在代码中指定运行模式,可以通过在代码中配置Master为Local来实现,如程序4所示。
程序4
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf()
.setMaster("local")
.setAppName("My application")
.set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
当然,为了使应用程序能够更灵活地在各种部署环境下使用,不建议把与运行环境相关的设置直接在代码中写死。
内部实现原理
Local本地模式使用LocalBackend配合TaskSchedulerImpl,内部逻辑结构如图3所示。
图3 Local模式逻辑结构框图
LocalBackend响应Scheduler的receiveOffers请求,根据可用的CPU核的设定值
直接生成CPU资源返回给Scheduler,并通过Executor类在线程池中依次启动和运行Scheduler返回的任务列表,其核心事件循环由内部类LocalActor以Akka Actor的消息处理形式来实现。
因为Local模式无须配置,同时所有的代码都在本地进程中执行,所以常常可以作为快速验证代码和跟踪调试的手段。
本文摘自《Spark大数据处理技术》

相关文章推荐
- 实现自动生成30道四则运算题目(4)
- 四则运算二项目计划总结
- modbus学习
- 第三周作业(一)单元测试
- 第四周上机实践项目——项目2-太乐了
- Android SwipeRefreshLayout 谷歌官方下拉刷新空间 最好的没之一
- 用Python写出LSTM-RNN的代码!
- Xshell的安装与使用,向云服务器上传文件
- pycaffe对于图片的加载与训练
- pycaffe API的使用
- 杂记-大佬尚技术讲堂
- caffe学习入门:pycaffe的使用
- 学习进度
- [网络流24题][BZOJ1475]方格取数(最小割)
- 来自bit.ly的1.usa.gov数据
- Ubuntu14.04 使用virtualbox 安装win7
- 软件工程-构建之法 理解C#一小段程序
- Hibernate逍遥游记-第1章-JDBC访问数据库
- 关于使用eclipse的事
- JavaScript组件设计思想