偷懒专用平衡树——Treap
2016-03-18 15:41
691 查看
日常开始前胡扯一通
如我上一篇文章所说,先拣软柿子捏,找一些熟悉的东西试试手,权当复习。当我思考究竟该怎么写这第一篇时,突然意识到Treap可能是一个没什么用的东西,尤其是在实际的工程开发中。在竞赛中,Treap可能是一个好的选择,因为它写起来快,易调试,相比那些复杂的平衡树来说效率并没有太多的下降。然而在实际开发中,要么直接会去使用标准模板库里的map、set这样的现成平衡树,要么索性做的精致一点,直接写一个AVL或者RBTree封装好。Treap就处在了一个比较尴尬的位置。
当然无论如何,这并不影响本文的内容。
特别提醒:本人现在LaTeX基本不会用,目测本文要出现大量的图片……
从二叉查找树说起
为了凑点字数,还是从普通的二叉查找树说起吧。一个简单的问题
一个长度为n的有序序列,从中查找一个指定的值,要花多少时间?一个最简单的做法就是一个个去试。如果你运气好,第一个就碰上了;如果你运气不好,最后一个才是你要查的值,那就需要把n个值都检查一遍。时间复杂度O(n)。
当然你可能注意到了有序这个有用的性质,所以可以采用二分查找的方式,具体就不赘述了。时间复杂度O(log(n))。
但是如果要添加一个数据怎么办?要保证序列的有序性,你必须要插入到适当的位置。这个位置同样可以通过二分查找在O(log(n))的时间中找出。
可是插入的过程呢?我们必须把后面的数据一个个顺次往后挪一格,而这需要O(n)的时间。
太慢了!我们需要快一点的方法。
二叉查找树
这种时候,一个可能的解决方法就是使用二叉查找树。那个说树状数组的给我出来,我保证不打死你
二叉查找树是这样的一种数据结构,保证在任意一个节点上,左儿子的值小于自己的值小于右儿子的值(这里暂且不考虑等于的情况),从而满足中序遍历的结果是有序的。
如图所示:
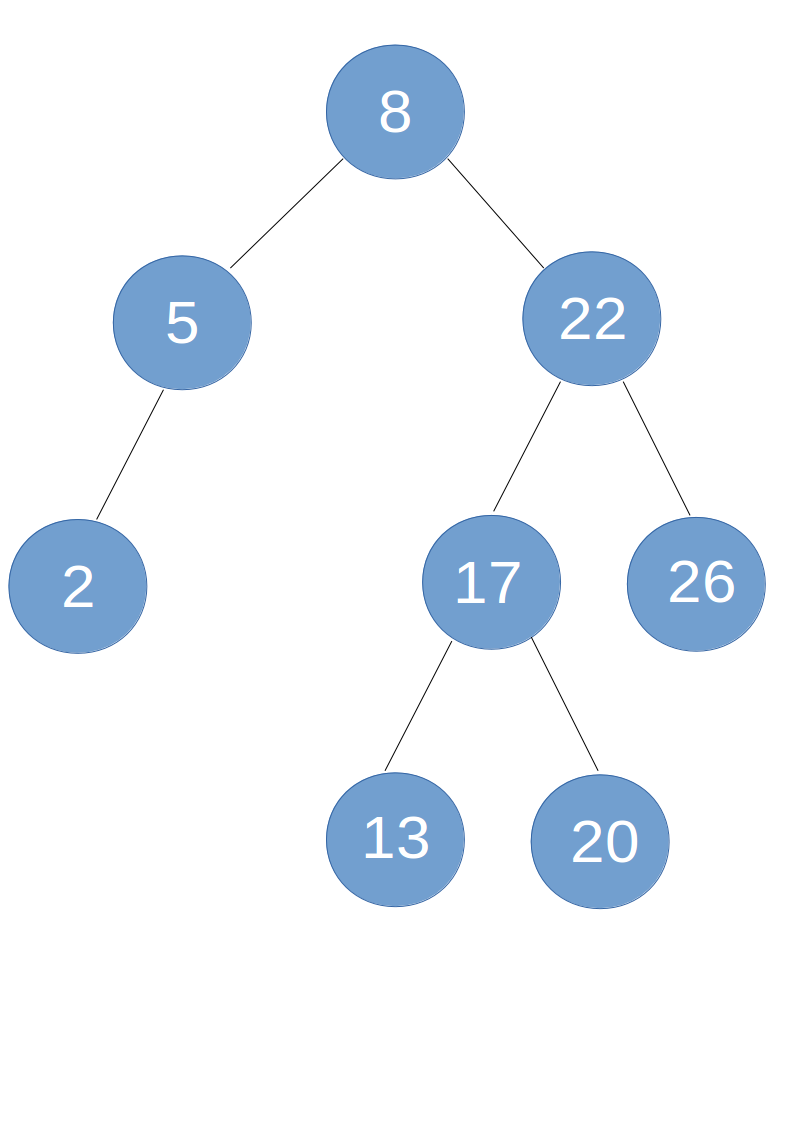
原谅我弄出这么个lowB的图(掩面)
这一棵二叉查找树的中序遍历就是2-5-8-13-17-20-22-26。
使用二叉查找树有什么好处呢?
假如你插入时的数据基本随机,那么你建立的二叉查找树应该是基本平衡的。所谓平衡,就是这棵树的每个叶子节点的深度都基本相同。如果一棵二叉查找树基本平衡,那么它将会有以下好的性质:
查找一个值的时间约为O(log(n))
插入一个值的时间约为O(log(n))
而且它的代码也非常容易完成,每个操作只需要一个小的递归函数就可以了,目测没几行。
二叉查找树的问题
这么好的东西基本没人用自然是有原因的。上文提到,“如果二叉查找树是基本平衡的”。
这是个不错的flag,很多时候你都没法保证它是基本平衡的。尤其在竞赛中,这种卡你的数据是必然会出现的。
举个例子,假如你在建树的时候,给你的数据是有序的,那么建出来的树可能就是这样的:
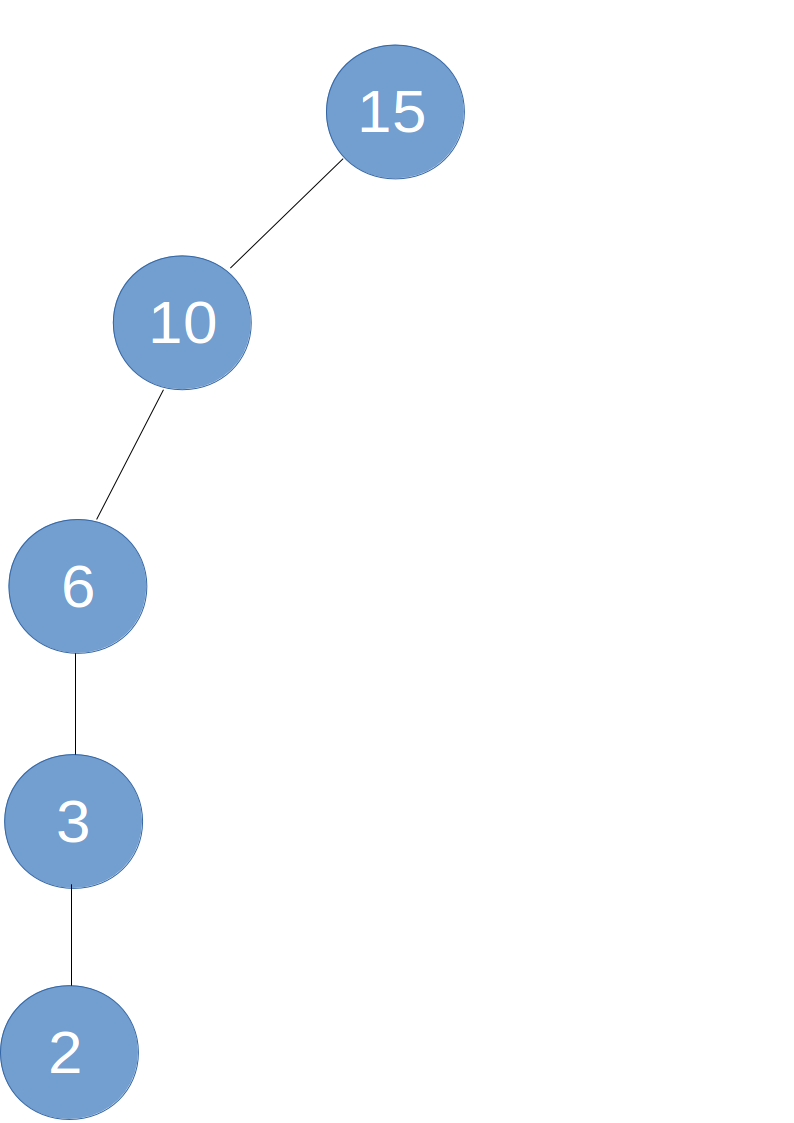
这样一棵二叉查找树就退化成了一个链表。此时,查找操作的时间复杂度就变成了O(n)。
那我还不如写个链表呢
当然,你也可以采用其他的一些方法,比如全读进来再随机插入到树里。但这些方法终归都是有局限性的。
从平衡树到Treap
平衡树
那么,有没有使一棵二叉查找树墙柱保持平衡的方法呢?答案当然是肯定的,这样的二叉查找树就被成为平衡二叉查找树,简称平衡树。当然这意味着你要写更多的代码
平衡树有很多种,比如说AVL,红黑树,SBT,Splay等等。我们今天要介绍的Treap就是平衡树中相对比较好写的一种。
代价就是慢,当然比起线性表来说还是强多了
Treap
废话扯了这么多终于进入正题了……Treap,顾名思义就是Tree+Heap。这么命名的原因就是它使用了二叉堆的性质来保持二叉树的平衡。
我们知道,一个二叉(大根)堆满足这样的性质:一个节点的两个儿子的值都小于节点本身的值。如果一个二叉查找树满足这样的性质,那么它就被称作Treap。
但是等等,这样的设定似乎和二叉查找树矛盾啊。一个要求节点值小于右儿子的值,一个要求节点值大于右儿子的值,这显然是不可能做到的。
只有一种方法能够解决,就是让每个节点有2个值,其中一个满足二叉查找树的性质,一个满足大根堆的性质。为方便起见,下面把满足二叉查找树性质的值称作key,把满足大根堆性质的值称作prio(priority的简称)。
每个节点的key我们是无法改变了,为了保证Treap的平衡性,我们需要在prio上做一点文章。其实也没有什么复杂的,就是让每个节点的prio都取一个随机值,这样我们就可以保证这棵树“基本平衡”。
Treap的实现
约定
为了方便叙述,我们做出以下的约定:struct node{ //节点数据的结构
int key,prio,size; //size是指以这个节点为根的子树中节点的数量
node* ch[2]; //ch[0]指左儿子,ch[1]指右儿子
};
typedef node* tree;
node base[MAXN],nil;
tree top,null,root;
void init(){
top=base;
root=null=&nil;
null->ch[0]=null->ch[1]=null;
null->key=null->prio=2147483647;
null->size=0;
}
inline tree newnode(int k){ //注意这种分配内存的方法也就比赛的时候用用,仅仅是为了提高效率
top->key=k;
top->size=1;
top->prio=random();
top->ch[0]=top->ch[1]=null;
return top++;
}旋转
事实上,想要一棵树恰巧满足以上的条件并不容易。绝大多数情况下,我们都需要通过旋转的方法来调整树的形态,使得它满足以上的条件。旋转分左旋和右旋两种,他们都不破坏二叉查找树的性质。如图所示:
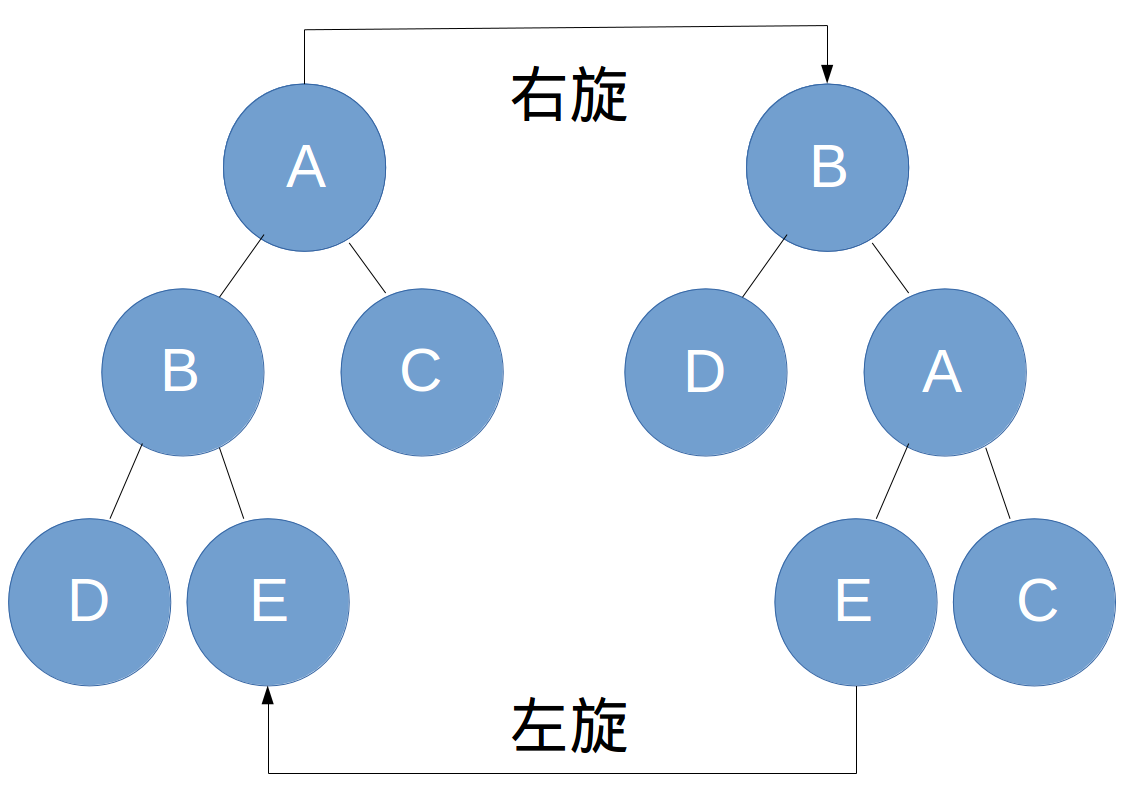
代码如下:
void rotate(tree &x,bool d){ //d指旋转的方向,0为左旋,1为右旋
4000
tree y=x->ch[!d];
x->ch[!d]=y->ch[d];
y->ch[d]=x;
x->size=x->ch[0]->size+1+x->ch[1]->size;
y->size=y->ch[0]->size+1+y->ch[1]->size;
x=y;
}随机数的生成
不知你有没有想过,如果我们采用系统函数生成的随机数,会有出现重复的可能性。如果prio取到了重复的值,则必然会造成堆结构的混乱。当然,我们有生成不重复的随机数的办法,代码如下:
inline int random(){
static int seed=703; //seed可以随便取
return seed=int(seed*48271LL%2147483647);
}说实话我也不知道48271这个数字是哪里来的,不过百度告诉我这样可以取遍1-2147483647中的所有数字。
插入、删除和选择第k小项
插入和普通的二叉查找树差不多。但是要注意,插入有可能会破坏Treap的堆性质,所以要通过旋转来维护堆性质。下图就是一个例子: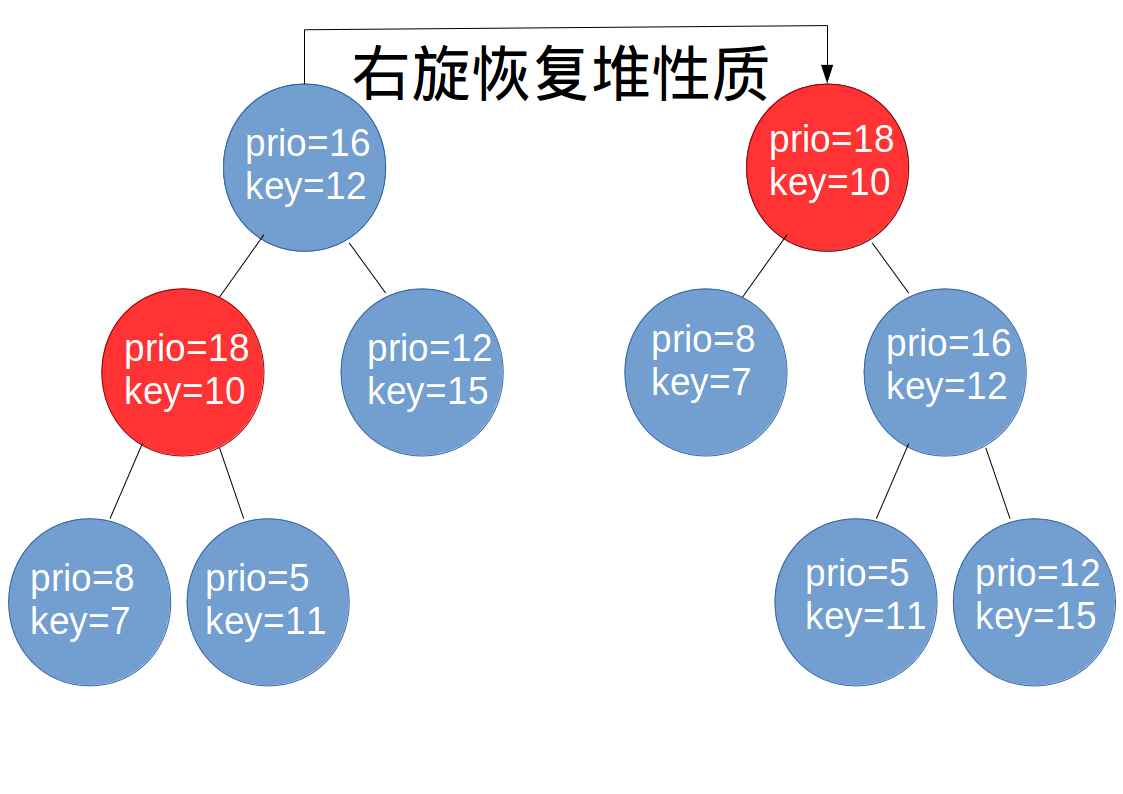
删除就相对容易很多了,由于Treap满足堆性质,只需要将待删除的节点旋转到叶子节点再删除就可以了。
具体代码如下:
void insert(tree &t,int key){ //插入一个节点
if (t==null) t=newnode(key);
else{
bool d=key>t->key;
insert(t->ch[d],key);
t->size++;
if (t->prio<t->ch[d]->prio) rotate(t,!d);
}
}
void erase(tree &t,int key){ //删除一个节点
if (t->key!=key){
erase(t->ch[key>t->key],key);
t->size--;
}
else if (t->ch[0]==null) t=t->ch[1];
else if (t->ch[1]==null) t=t->ch[0];
else{
bool d=t->ch[0]->prio<t->ch[1]->prio;
rotate(t,d);
erase(t->ch[d],key);
}
}
tree select(int k){ //选择第k小节点
tree t=root;
for (int tmp;;){
tmp=t->ch[0]->size+1;
if (k==tmp) return t;
if (k>tmp){
k-=tmp;
t=t->ch[1];
}
else t=t->ch[0];
}
}后记
代码来自某大牛学长,本人只做了一点点修改;其实这篇文章只是个半成品,算了有时间再补充吧;
刚开始写,编辑器不熟练,所以有的地方可能排版会乱;
似乎有点罗嗦了,而且虎头蛇尾,希望以后写能好一点吧;
写起来真累……

相关文章推荐
- C#数据结构之顺序表(SeqList)实例详解
- Lua教程(七):数据结构详解
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构之队列(Quene)实例详解
- C#数据结构揭秘一
- C#数据结构之单链表(LinkList)实例详解
- 数据结构之Treap详解
- 用C语言举例讲解数据结构中的算法复杂度结与顺序表
- C#数据结构之堆栈(Stack)实例详解
- C#数据结构之双向链表(DbLinkList)实例详解
- JavaScript数据结构和算法之图和图算法
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi
- 【数据结构与算法】数组应用4:多项式计算Java版