[Java GC]Algorithm For GC
2016-03-14 23:42
591 查看
大二学生党,最近在Java学习有所体会,但广度深度不够,敬请谅解。

首先看一下本文所讲述的几个内存的回收算法。只是算法的理论介绍,很枯燥啦(大部分是从维基百科看的,加上自我理解)
在写Android时,总是报GC的警告而且比较卡,但是不知道哪里错了,所以查阅了资料。研究了一哈GC。
在本文主要说了以下几个算法:
Reference Counting
Mark-and-Copy
Mark-and-Sweep
Mark-and-Compact
In computer science, garbage collection (GC) is a form of automatic
memory management. The garbage collector, or just collector, attempts
to reclaim garbage, or memory occupied by objects that are no longer
in use by the program.
2.什么样的Object可以被GC收集(这里说的是什么是可达的对象 Reachability of an object):
所有调用栈(call stack)上的对象,其中包括:所有的函数中的局部变量,参数;全局变量(包括静态变量);存活的线程,
所有引用上面这些对象的对象都是可达的(这是一个迭代的过程)
对于上面的代码,可以把看成一个树
这些都是可以到达的。但是将代码改下:
就变成了这样:
所以
也就是说,从Root Set出发,直接或间接所能到达的地方都可以成为reachable(或者成为存活的对象lived).这里StackOverFlow和YourKit说的很清楚
3.Strong Refrence,Weak Refrence,Soft Refrence
Strong Refrence:无论如何都不会被JVM回收,JVM宁愿抛出
Soft Reference:在GC时不会被回收,也就是说比Strong Refrence稍微弱一点。但内存耗尽的时候就会先收回SoftReference,软引用非常适合于创建缓存,可以用来存储图片缓存
Weak Reference:在GC时一定会被回收,也就是说比Soft Reference稍微弱一点,WeakHashMap来解决,集合的内存问题(集合只要有一个生命周期长的,所有的都不会回收)
最后一个幽灵引用,我也不是很清楚。。(// Todo)
看看Java代码实现(大家可以Run一下):

Tri-Color是一个原则(准确的说是abstraction),下面几个算法直接或间接的实现这个原则。这里是维基百科的说明
2.2 infant mortality or the generational hypothesis:弱代假设,即大多数对象都在年轻时候死亡
a count of the number of references to it held by other objects. If an
object’s reference count reaches zero, the object has become
inaccessible, and can be destroyed.
When an object is destroyed, any objects referenced by that object
also have their reference counts decreased. Because of this, removing
a single reference can potentially lead to a large number of objects
being freed. A common modification allows reference counting to be
made incremental: instead of destroying an object as soon as its
reference count becomes zero, it is added to a list of unreferenced
objects, and periodically (or as needed) one or more items from this
list are destroyed.
Simple reference counts require frequent updates. Whenever a reference
is destroyed or overwritten, the reference count of the object it
references is decremented, and whenever one is created or copied, the
reference count of the object it references is incremented.
Reference counting is also used in disk operating systems and
distributed systems, where full non-incremental tracing garbage
collection is too time consuming because of the size of the object
graph and slow access speed.
建议先看英文原文,在看我自己的理解。
Reference counting(引用计数法):对每个Object,都记录这个Object被其他Object所引用的次数,可以称为counter。当这个Object的被其他Object所引用的次数为0的时候,这个Object是可以被GC所摧毁的。当这个Object被摧毁时,所有被这个Object引用的这个Object对象的counter都会减一。
这样一旦某个对象的counter == 0,这个对象就会被立即回收,有个解决办法:把counter == 0的对象放在一个list里面,用来存储未被其他Object所引用的对象。
引用计数法可以被用在磁盘操作系统(disk operating systems),和分布式系统(distributed systems),而且在PHP的ZEND引擎用的也是引用计数法(好像把。。。)
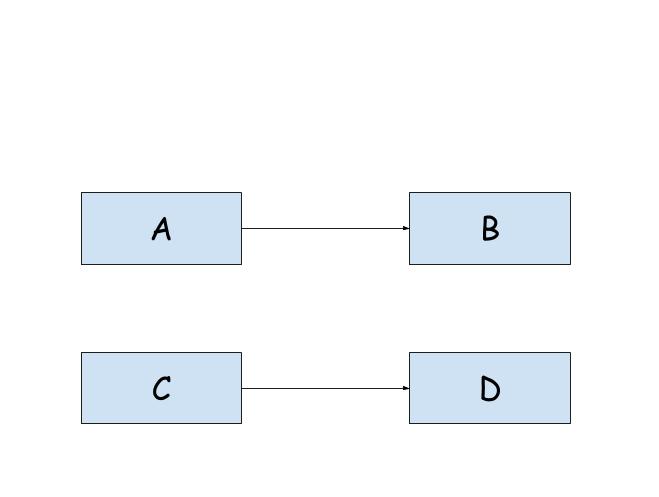
B被A引用,D被C引用。所以 counterB == 1 ,counterD == 1。
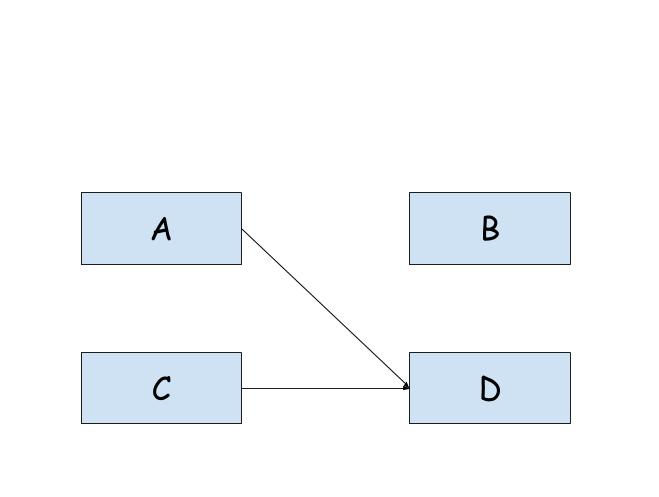
现将A引用指针指向D,counterD == 2,counterB == 0 。所以B可以被GC回收。
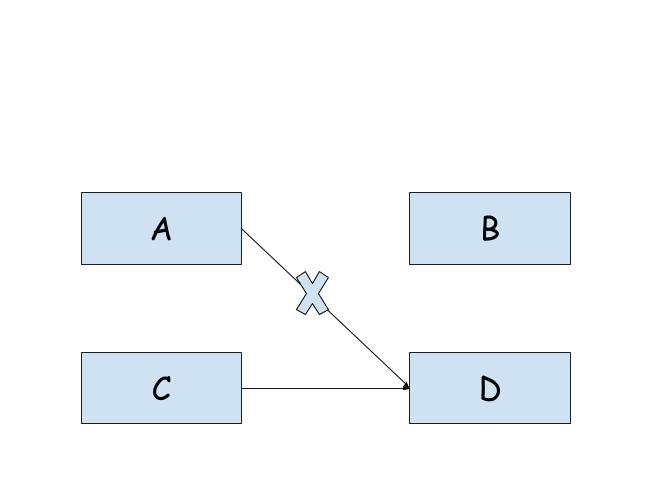
现在将A回收(因为counterA == 0,所以可以被回收)则counterD == 1。(取消了A对D的引用)
引用计数法就是这么一回事
主要代表是Cheney’s algorithm,是semi-space collector的典型代表。
In this moving GC scheme, memory is partitioned into a “from space”
and “to space”. Initially, objects are allocated into “to space” until
they become full and a collection is triggered. At the start of a
collection, the “to space” becomes the “from space”, and vice versa.
The objects reachable from the root set are copied from the “from
space” to the “to space”. These objects are scanned in turn, and all
objects that they point to are copied into “to space”, until all
reachable objects have been copied into “to space”. Once the program
continues execution, new objects are once again allocated in the “to
space” until it is once again full and the process is repeated. This
approach has the advantage of conceptual simplicity (the three object
color sets are implicitly constructed during the copying process), but
the disadvantage that a (possibly) very large contiguous region of
free memory is necessarily required on every collection cycle. This
technique is also known as stop-and-copy.
The algorithm needs no stack and only two pointers outside of the from-space and to-space: a pointer to the beginning of free space in the to-space, and a pointer to the next word in to-space that needs to be examined. For this reason, it’s sometimes called a “two-finger” collector — it only needs “two fingers” pointing into the to-space to keep track of its state. The data between the two fingers represents work remaining for it to do.
维基百科如上说。堆内存被分为2个区(to-space,from-space),新生成的对象被分配在一个区里面(to-space),当这个区里面的内存满了就会触发GC。由于该算法只需要2个指针(一个指向to-space的free首地址,一个指向from-space的free区域的首地址),所以又称之为two-finger算法具体步骤如下:
交换2个区
从root set开始遍历(采用DFS算法遍历),可以到达(reachable)的Object将从一个区被拷贝到另一个区
这个方法在概念上比较简单,实现也并不难;但是有可能需要大量连续的free区域,用来存储对象,也就是浪费了一般的内存,这不划算。
还是比较简单的,有以下几篇文章参考:
半区复制算法,写的不错,有图。
从垃圾回收算法到Object Pool
working set of memory. These garbage collectors perform collection in
cycles. A cycle is started when the collector decides (or is notified)
that it needs to reclaim memory, which happens most often when the
system is low on memory[citation needed]. The original method involves
a naïve mark-and-sweep in which the entire memory set is touched
several times.
In the naive mark-and-sweep method, each object in memory has a flag
(typically a single bit) reserved for garbage collection use only.
This flag is always cleared, except during the collection cycle. The
first stage of collection does a tree traversal of the entire ‘root
set’, marking each object that is pointed to as being ‘in-use’. All
objects that those objects point to, and so on, are marked as well, so
that every object that is ultimately pointed to from the root set is
marked. Finally, all memory is scanned from start to finish, examining
all free or used blocks; those with the in-use flag still cleared are
not reachable by any program or data, and their memory is freed. (For
objects which are marked in-use, the in-use flag is cleared again,
preparing for the next cycle.)
This method has several disadvantages, the most notable being that the
entire system must be suspended during collection; no mutation of the
working set can be allowed. This will cause programs to ‘freeze’
periodically (and generally unpredictably), making real-time and
time-critical applications impossible. In addition, the entire working
memory must be examined, much of it twice, potentially causing
problems in paged memory systems.
这个算法之所以叫Mark-and-Sweep,是因为collector遍历了内存集合。这种算法大部分是在内存低的时候调用。
算法的运行过程如下:
首先,内存中每个object都有一个标志位(flag),并且初始状态是清除所有标记的。
Mark阶段:从rootset开始遍历,对每个可以到达(reachable)的object,都去标记这个object。
所有rootset直接或间接指向的对象,都被标记了。
Sweep阶段:GC对堆内存线性遍历,销毁所有没有被标记的对象(清除所有标记过的对象的标记,以便下次GC)
就是这么简单粗暴,下面看看图(来自这里)

6.1 Table-based compaction
A table-based algorithm was first described by Haddon and Waite in
1967.[1] It preserves the relative placement of the live objects in the heap, and requires only a constant amount of overhead.
Compaction proceeds from the bottom of the heap (low addresses) to the
top (high addresses). As live (that is, marked) objects are
encountered, they are moved to the first available low address, and a
record is appended to a break table of relocation information. For
each live object, a record in the break table consists of the object’s
original address before the compaction and the difference between the
original address and the new address after compaction. The break table
is stored in the heap that is being compacted, but in an area that are
marked as unused. To ensure that compaction will always succeed, the
minimum object size in the heap must be larger than or the same size
as a break table record.
As compaction progresses, relocated objects are copied towards the
bottom of the heap. Eventually an object will need to be copied to the
space occupied by the break table, which now must be relocated
elsewhere. These movements of the break table, (called rolling the
table by the authors) cause the relocation records to become
disordered, requiring the break table to be sorted after the
compaction is complete. The cost of sorting the break table is O(n log
n), where n is the number of live objects that were found in the mark
stage of the algorithm.
Finally, the break table relocation records are used to adjust pointer
fields inside the relocated objects. The live objects are examined for
pointers, which can be looked up in the sorted break table of size n
in O(log n) time if the break table is sorted, for a total running
time of O(n log n). Pointers are then adjusted by the amount specified
in the relocation table.
对于table-based算法的实现如下:
首先有一个指针,从heap的bottom(low addresses)遍历到top(high addresses)
在遍历的过程中,当遇到一个live的对象,把这个对象移到heap的bottom端,并且在这个heap中创建一个break table,这个table存储2个内容,这个对象的长度,这个对象原来的位置和移动过后的位置的差值。
最终所有的对象,都被移动到bottom端。由于移动之后,原来所有stack与heap的指向都是错误的,所以现在要将所有的指向给重行定位,得到最终结果,对于重新定位,当然要遍历整个break-table了。(注意,因为break table存储在heap中,所以 the minimum object size in the heap must be larger than or the same size as a break table record)

最后有一点注意:算法的时间复杂度为O(n log n),where n is the number of live objects that were found in the mark stage of the algorithm.怎么算的呢?遍历break-table,所以得到了算法基础的排序:n个对象排序的时间复杂度咯?这里有连接
6.2 LISP2 Algorithm
In order to avoid O(n log n) complexity, the LISP2 algorithm uses 3
different passes over the heap. In addition, heap objects must have a
separate forwarding pointer slot that is not used outside of garbage
collection.
After standard marking, the algorithm proceeds in the following 3
passes:
Compute the forwarding location for live objects.
Keep track of a free and live pointer and initialize both to the start of heap. If the live
pointer points to a live object, update that object’s forwarding
pointer to the current free pointer and increment the free pointer
according to the object’s size. Move the live pointer to the next
object End when the live pointer reaches the end of heap.
Update all
pointers For each live object, update its pointers according to the
forwarding pointers of the objects they point to.
Move objects For
each live object, move its data to its forwarding location. This
algorithm is O(n) on the size of the heap; it has a better complexity
than the table-based approach, but the table-based approach’s n is the
size of the used space only, not the entire heap space as in the LISP2
algorithm. However, the LISP2 algorithm is simpler to implement.
LISP2算法利用三次遍历Heap来进行GC管理,三个步骤分别如下:
首先初始化2个指针(free,live)并使这2个指针指向heap的首部(start)。然后让live指针开始遍历heap,当live指针遇到一个lived对象的时候,让这个对象的一个指针指向free指针的位置(在构造这个对象的时候就把这个指针分配好的),被指向的地址就是Compact之后的地址。然后free指针向堆尾移动这个Object长度的距离。
更新stack和heap所有Object的指向问题(和Mark-and-Sweep一样一样的)
将所有的Object都移到heap的首部(紧紧的依靠在一起。。)
LISP2的算法时间复杂度为O(n),并且比较简单,用处较多。
第一次遍历如下:

第二次遍历就是更新所有的指向,这个比较简单,可以想象的出来;
第三次就更简单了,把所有的对象全部左移。
Moving vs. non-moving
对于non-moving:实现简单啊,只需要把没用的对象直接擦出就好了。
对于Moving:看起来麻烦,既要计算移动后的位置,又要更新指针的指向,有大的内存对象的时候又很耗时。但是其实也有很多的优点:
减少了内存的碎片化,对于整理后的内存,分配一块新的内存的时候,可以直接在空闲的地方的分配啦,就很快咯;下一次GC的时候,回收的时候将会很方便;同时如果2个对象位置远了,遍历的时候将会很慢。
Stop-the-world vs. concurrent
Stopd-the-world:就是指GC的时候,当前程序会停止运行,
concurrent:就是并发进行处理,但是在GC时,运行的程序中声明一个对象要通知GC。
首先看一下本文所讲述的几个内存的回收算法。只是算法的理论介绍,很枯燥啦(大部分是从维基百科看的,加上自我理解)
动机
Java内存管理:包括分配内存与回收内存,即对于着ClassLoader与GC,这里介绍GC。
在写Android时,总是报GC的警告而且比较卡,但是不知道哪里错了,所以查阅了资料。研究了一哈GC。
在本文主要说了以下几个算法:
Reference Counting
Mark-and-Copy
Mark-and-Sweep
Mark-and-Compact
基本知识
1.什么是GC:简单的说说In computer science, garbage collection (GC) is a form of automatic
memory management. The garbage collector, or just collector, attempts
to reclaim garbage, or memory occupied by objects that are no longer
in use by the program.
2.什么样的Object可以被GC收集(这里说的是什么是可达的对象 Reachability of an object):
所有调用栈(call stack)上的对象,其中包括:所有的函数中的局部变量,参数;全局变量(包括静态变量);存活的线程,
所有引用上面这些对象的对象都是可达的(这是一个迭代的过程)
Person p = new Person(); p.car = new Car(RED); p.car.engine = new Engine(); p.car.horn = new AnnoyingHorn();
对于上面的代码,可以把看成一个树
Person [p] | Car (red) / \ Engine AnnoyingHorn
这些都是可以到达的。但是将代码改下:
p.car = new Car(BLUE);
就变成了这样:
Person [p] | Car (blue) Car (red) / \ Engine AnnoyingHorn
所以
Car(red)就可以被回收了(p才是被Root Set所引用的对象,但p不是Root Set。因为Root Set只有上面描述的几类哦)
也就是说,从Root Set出发,直接或间接所能到达的地方都可以成为reachable(或者成为存活的对象lived).这里StackOverFlow和YourKit说的很清楚
3.Strong Refrence,Weak Refrence,Soft Refrence
Strong Refrence:无论如何都不会被JVM回收,JVM宁愿抛出
OutOfMeroryError,也不去回收。
Soft Reference:在GC时不会被回收,也就是说比Strong Refrence稍微弱一点。但内存耗尽的时候就会先收回SoftReference,软引用非常适合于创建缓存,可以用来存储图片缓存
Weak Reference:在GC时一定会被回收,也就是说比Soft Reference稍微弱一点,WeakHashMap来解决,集合的内存问题(集合只要有一个生命周期长的,所有的都不会回收)
最后一个幽灵引用,我也不是很清楚。。(// Todo)
看看Java代码实现(大家可以Run一下):
/**
* Created on 2016/3/17.
*
* @author 王启航
* @version 1.0
*/
public class Reference {
public static void main(String args[]) {
WeakReferenceTest();
SoftReferenceTest();
}
//WeakReference在GC时一定会被回收
//WeakHashMap来解决,集合的内存问题(集合只要有一个生命周期长的,所有的都不会回收)
static void WeakReferenceTest() {
String s = new String("WQH");
WeakReference<String> wr = new WeakReference<>(s);
s = null;
while (wr.get() != null) {
System.out.println("WeakReference get :" + wr.get());
System.gc();
System.out.println("System.gc() " + wr.get());
}
}
//SoftReference在GC时不会被回收,但内存耗尽的时候就会先收回SoftReference
//软引用非常适合于创建缓存,可以用来存储图片缓存
static void SoftReferenceTest() {
String s = new String("WQH"); //必须是new String(),String s = "WQH"是错误的
SoftReference<String> wr = new SoftReference<>(s);
s = null;
while (wr.get() != null) {
System.out.println("SoftReference get :" + wr.get());
System.gc();
System.out.println("System.gc()" + wr.get());
}
}
}原则与假设
2.1Tri-ColorWhite:not-alive 或者 没有被collector访问过
Black:alive且自己被collector访问过,但是children not-alive 或者 没有被collector访问过
Black:自己和children都alive且被collector访问过
Tri-Color是一个原则(准确的说是abstraction),下面几个算法直接或间接的实现这个原则。这里是维基百科的说明
2.2 infant mortality or the generational hypothesis:弱代假设,即大多数对象都在年轻时候死亡
Reference Counting
As a collection algorithm, reference counting tracks, for each object,a count of the number of references to it held by other objects. If an
object’s reference count reaches zero, the object has become
inaccessible, and can be destroyed.
When an object is destroyed, any objects referenced by that object
also have their reference counts decreased. Because of this, removing
a single reference can potentially lead to a large number of objects
being freed. A common modification allows reference counting to be
made incremental: instead of destroying an object as soon as its
reference count becomes zero, it is added to a list of unreferenced
objects, and periodically (or as needed) one or more items from this
list are destroyed.
Simple reference counts require frequent updates. Whenever a reference
is destroyed or overwritten, the reference count of the object it
references is decremented, and whenever one is created or copied, the
reference count of the object it references is incremented.
Reference counting is also used in disk operating systems and
distributed systems, where full non-incremental tracing garbage
collection is too time consuming because of the size of the object
graph and slow access speed.
建议先看英文原文,在看我自己的理解。
Reference counting(引用计数法):对每个Object,都记录这个Object被其他Object所引用的次数,可以称为counter。当这个Object的被其他Object所引用的次数为0的时候,这个Object是可以被GC所摧毁的。当这个Object被摧毁时,所有被这个Object引用的这个Object对象的counter都会减一。
这样一旦某个对象的counter == 0,这个对象就会被立即回收,有个解决办法:把counter == 0的对象放在一个list里面,用来存储未被其他Object所引用的对象。
引用计数法可以被用在磁盘操作系统(disk operating systems),和分布式系统(distributed systems),而且在PHP的ZEND引擎用的也是引用计数法(好像把。。。)
B被A引用,D被C引用。所以 counterB == 1 ,counterD == 1。
现将A引用指针指向D,counterD == 2,counterB == 0 。所以B可以被GC回收。
现在将A回收(因为counterA == 0,所以可以被回收)则counterD == 1。(取消了A对D的引用)
引用计数法就是这么一回事
Mark-and-Copy
Mark-and-Copy首先停止当前正在进行的程序(stop-the-world),进行垃圾收集。在垃圾收集的过程中,把可用的内存copy到另一块内存中,这样就可以把没用的内存回收。主要代表是Cheney’s algorithm,是semi-space collector的典型代表。
In this moving GC scheme, memory is partitioned into a “from space”
and “to space”. Initially, objects are allocated into “to space” until
they become full and a collection is triggered. At the start of a
collection, the “to space” becomes the “from space”, and vice versa.
The objects reachable from the root set are copied from the “from
space” to the “to space”. These objects are scanned in turn, and all
objects that they point to are copied into “to space”, until all
reachable objects have been copied into “to space”. Once the program
continues execution, new objects are once again allocated in the “to
space” until it is once again full and the process is repeated. This
approach has the advantage of conceptual simplicity (the three object
color sets are implicitly constructed during the copying process), but
the disadvantage that a (possibly) very large contiguous region of
free memory is necessarily required on every collection cycle. This
technique is also known as stop-and-copy.
The algorithm needs no stack and only two pointers outside of the from-space and to-space: a pointer to the beginning of free space in the to-space, and a pointer to the next word in to-space that needs to be examined. For this reason, it’s sometimes called a “two-finger” collector — it only needs “two fingers” pointing into the to-space to keep track of its state. The data between the two fingers represents work remaining for it to do.
维基百科如上说。堆内存被分为2个区(to-space,from-space),新生成的对象被分配在一个区里面(to-space),当这个区里面的内存满了就会触发GC。由于该算法只需要2个指针(一个指向to-space的free首地址,一个指向from-space的free区域的首地址),所以又称之为two-finger算法具体步骤如下:
交换2个区
从root set开始遍历(采用DFS算法遍历),可以到达(reachable)的Object将从一个区被拷贝到另一个区
这个方法在概念上比较简单,实现也并不难;但是有可能需要大量连续的free区域,用来存储对象,也就是浪费了一般的内存,这不划算。
还是比较简单的,有以下几篇文章参考:
半区复制算法,写的不错,有图。
从垃圾回收算法到Object Pool
Mark-and-Sweep
Tracing collectors are so called because they trace through theworking set of memory. These garbage collectors perform collection in
cycles. A cycle is started when the collector decides (or is notified)
that it needs to reclaim memory, which happens most often when the
system is low on memory[citation needed]. The original method involves
a naïve mark-and-sweep in which the entire memory set is touched
several times.
In the naive mark-and-sweep method, each object in memory has a flag
(typically a single bit) reserved for garbage collection use only.
This flag is always cleared, except during the collection cycle. The
first stage of collection does a tree traversal of the entire ‘root
set’, marking each object that is pointed to as being ‘in-use’. All
objects that those objects point to, and so on, are marked as well, so
that every object that is ultimately pointed to from the root set is
marked. Finally, all memory is scanned from start to finish, examining
all free or used blocks; those with the in-use flag still cleared are
not reachable by any program or data, and their memory is freed. (For
objects which are marked in-use, the in-use flag is cleared again,
preparing for the next cycle.)
This method has several disadvantages, the most notable being that the
entire system must be suspended during collection; no mutation of the
working set can be allowed. This will cause programs to ‘freeze’
periodically (and generally unpredictably), making real-time and
time-critical applications impossible. In addition, the entire working
memory must be examined, much of it twice, potentially causing
problems in paged memory systems.
这个算法之所以叫Mark-and-Sweep,是因为collector遍历了内存集合。这种算法大部分是在内存低的时候调用。
算法的运行过程如下:
首先,内存中每个object都有一个标志位(flag),并且初始状态是清除所有标记的。
Mark阶段:从rootset开始遍历,对每个可以到达(reachable)的object,都去标记这个object。
所有rootset直接或间接指向的对象,都被标记了。
Sweep阶段:GC对堆内存线性遍历,销毁所有没有被标记的对象(清除所有标记过的对象的标记,以便下次GC)
就是这么简单粗暴,下面看看图(来自这里)
Mark-and-Compact
Mark-and-sweep算法有如下的缺点:会产生许多的内存的碎片。为了解决这个问题,又有了一个新的算法,Mark阶段和前面的算法是一样的。其主要思想如下:对Heap的所有的reachable对象进行标记,然后清理所有的unraechable对象;但是在清除内存的之后,把reachable的内存都移到一起,最后要更新所有对象的指向。这样就会把内存集中,减少了内存的碎片的产生。6.1 Table-based compaction
A table-based algorithm was first described by Haddon and Waite in
1967.[1] It preserves the relative placement of the live objects in the heap, and requires only a constant amount of overhead.
Compaction proceeds from the bottom of the heap (low addresses) to the
top (high addresses). As live (that is, marked) objects are
encountered, they are moved to the first available low address, and a
record is appended to a break table of relocation information. For
each live object, a record in the break table consists of the object’s
original address before the compaction and the difference between the
original address and the new address after compaction. The break table
is stored in the heap that is being compacted, but in an area that are
marked as unused. To ensure that compaction will always succeed, the
minimum object size in the heap must be larger than or the same size
as a break table record.
As compaction progresses, relocated objects are copied towards the
bottom of the heap. Eventually an object will need to be copied to the
space occupied by the break table, which now must be relocated
elsewhere. These movements of the break table, (called rolling the
table by the authors) cause the relocation records to become
disordered, requiring the break table to be sorted after the
compaction is complete. The cost of sorting the break table is O(n log
n), where n is the number of live objects that were found in the mark
stage of the algorithm.
Finally, the break table relocation records are used to adjust pointer
fields inside the relocated objects. The live objects are examined for
pointers, which can be looked up in the sorted break table of size n
in O(log n) time if the break table is sorted, for a total running
time of O(n log n). Pointers are then adjusted by the amount specified
in the relocation table.
对于table-based算法的实现如下:
首先有一个指针,从heap的bottom(low addresses)遍历到top(high addresses)
在遍历的过程中,当遇到一个live的对象,把这个对象移到heap的bottom端,并且在这个heap中创建一个break table,这个table存储2个内容,这个对象的长度,这个对象原来的位置和移动过后的位置的差值。
最终所有的对象,都被移动到bottom端。由于移动之后,原来所有stack与heap的指向都是错误的,所以现在要将所有的指向给重行定位,得到最终结果,对于重新定位,当然要遍历整个break-table了。(注意,因为break table存储在heap中,所以 the minimum object size in the heap must be larger than or the same size as a break table record)
最后有一点注意:算法的时间复杂度为O(n log n),where n is the number of live objects that were found in the mark stage of the algorithm.怎么算的呢?遍历break-table,所以得到了算法基础的排序:n个对象排序的时间复杂度咯?这里有连接
6.2 LISP2 Algorithm
In order to avoid O(n log n) complexity, the LISP2 algorithm uses 3
different passes over the heap. In addition, heap objects must have a
separate forwarding pointer slot that is not used outside of garbage
collection.
After standard marking, the algorithm proceeds in the following 3
passes:
Compute the forwarding location for live objects.
Keep track of a free and live pointer and initialize both to the start of heap. If the live
pointer points to a live object, update that object’s forwarding
pointer to the current free pointer and increment the free pointer
according to the object’s size. Move the live pointer to the next
object End when the live pointer reaches the end of heap.
Update all
pointers For each live object, update its pointers according to the
forwarding pointers of the objects they point to.
Move objects For
each live object, move its data to its forwarding location. This
algorithm is O(n) on the size of the heap; it has a better complexity
than the table-based approach, but the table-based approach’s n is the
size of the used space only, not the entire heap space as in the LISP2
algorithm. However, the LISP2 algorithm is simpler to implement.
LISP2算法利用三次遍历Heap来进行GC管理,三个步骤分别如下:
首先初始化2个指针(free,live)并使这2个指针指向heap的首部(start)。然后让live指针开始遍历heap,当live指针遇到一个lived对象的时候,让这个对象的一个指针指向free指针的位置(在构造这个对象的时候就把这个指针分配好的),被指向的地址就是Compact之后的地址。然后free指针向堆尾移动这个Object长度的距离。
更新stack和heap所有Object的指向问题(和Mark-and-Sweep一样一样的)
将所有的Object都移到heap的首部(紧紧的依靠在一起。。)
LISP2的算法时间复杂度为O(n),并且比较简单,用处较多。
第一次遍历如下:
第二次遍历就是更新所有的指向,这个比较简单,可以想象的出来;
第三次就更简单了,把所有的对象全部左移。
比较与总结
更多资源MoreMoving vs. non-moving
对于non-moving:实现简单啊,只需要把没用的对象直接擦出就好了。
对于Moving:看起来麻烦,既要计算移动后的位置,又要更新指针的指向,有大的内存对象的时候又很耗时。但是其实也有很多的优点:
减少了内存的碎片化,对于整理后的内存,分配一块新的内存的时候,可以直接在空闲的地方的分配啦,就很快咯;下一次GC的时候,回收的时候将会很方便;同时如果2个对象位置远了,遍历的时候将会很慢。
Stop-the-world vs. concurrent
Stopd-the-world:就是指GC的时候,当前程序会停止运行,
concurrent:就是并发进行处理,但是在GC时,运行的程序中声明一个对象要通知GC。

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树