HDFS体系结构和操作(第六讲)
2016-03-14 20:45
344 查看
HDFS由两个核心部分组成,一个是NameNode,一个是DataNode
1.NameNode:是整个文件系统的管理节点
a.维护整个文件系统的目录树(目录结构),文件或目录的元信息(文件或目录的详细描述信息),
每个文件对于的数据块列表;(文件是以文件块的形式存在的,这儿的文件与文件块的关系也是存放在NameNode中的)
b.接收用户的操作请求(对文件系统中文件或文件夹的一系列操作);
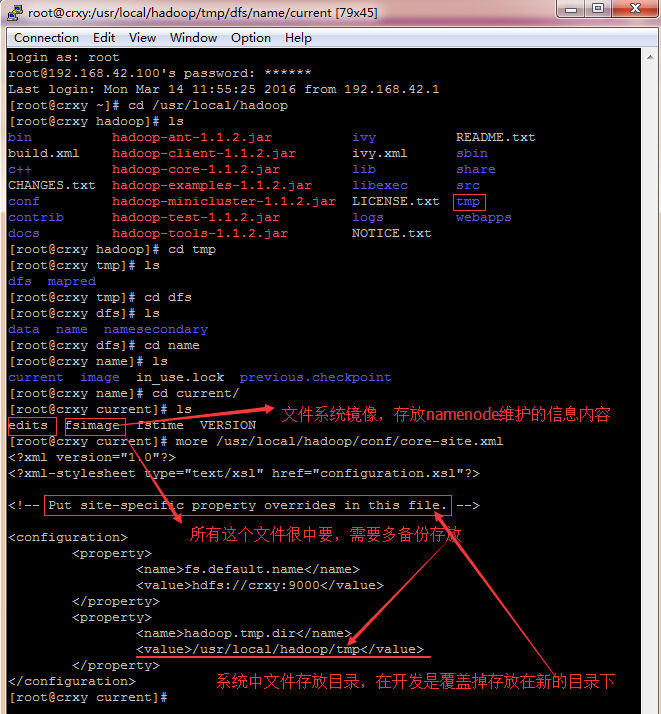
查看源码:
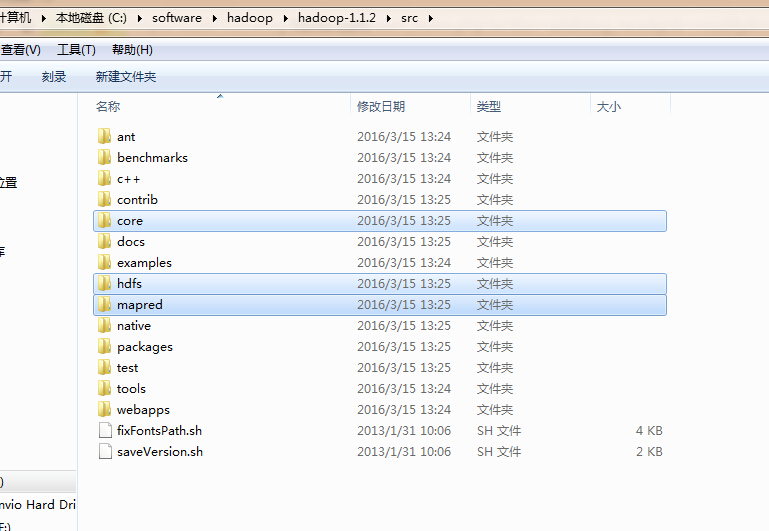
将之前传输到linux下的hadoop文件在windows下解压找到src目录文件,从中找到hdfs,core,mapred文件夹,选中它们,在eclipse中新建项目,将其粘贴到src目录下
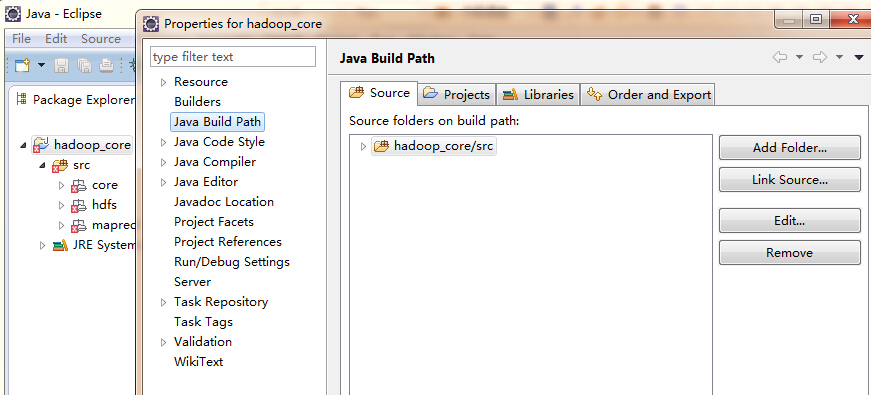
然后选中项目名称hadoop_core,右键属性(properties)-》java build path-》source,选中里面的文件,点击remove,然后点击add file,将src下的core,hdfs和mapred文件夹添加进去
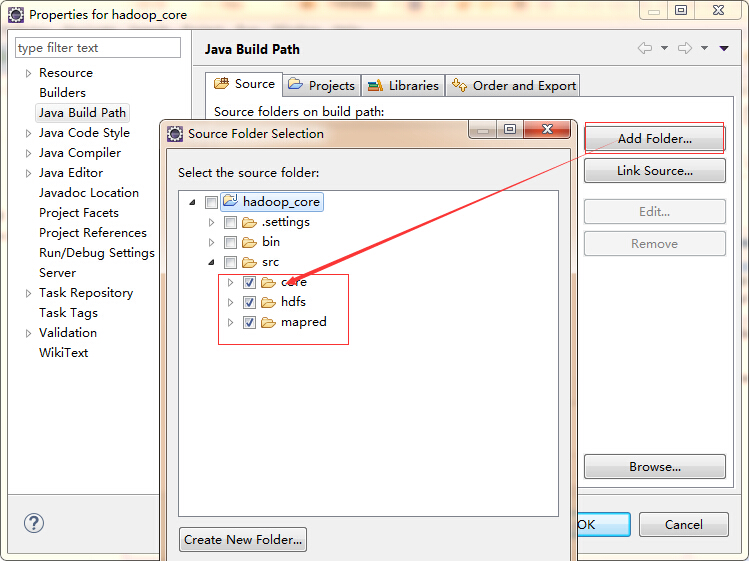
然后点击library,点击右边的add externaml jars,
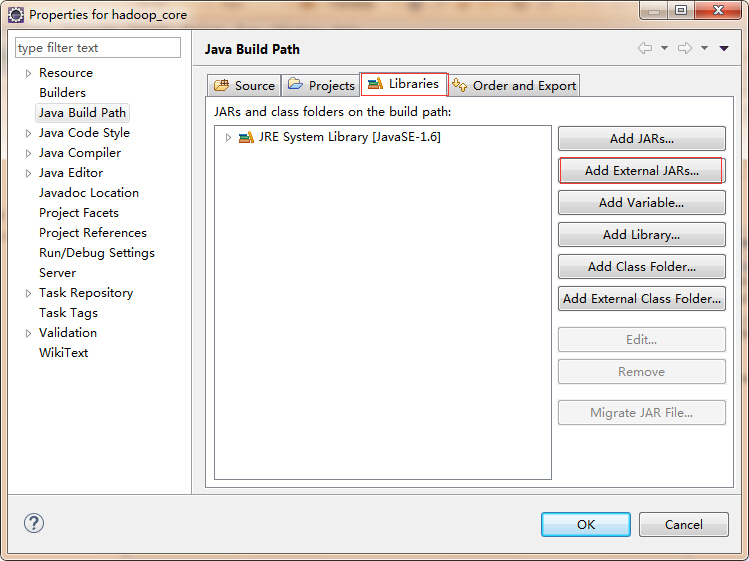
找到之间解压后的hadoop文件夹下的lib文件夹,选中下面的所有jar包,点击打开,再次点击add external jars,找到lib文件夹下的jsp2.1下的两个jar包选中,点击打开
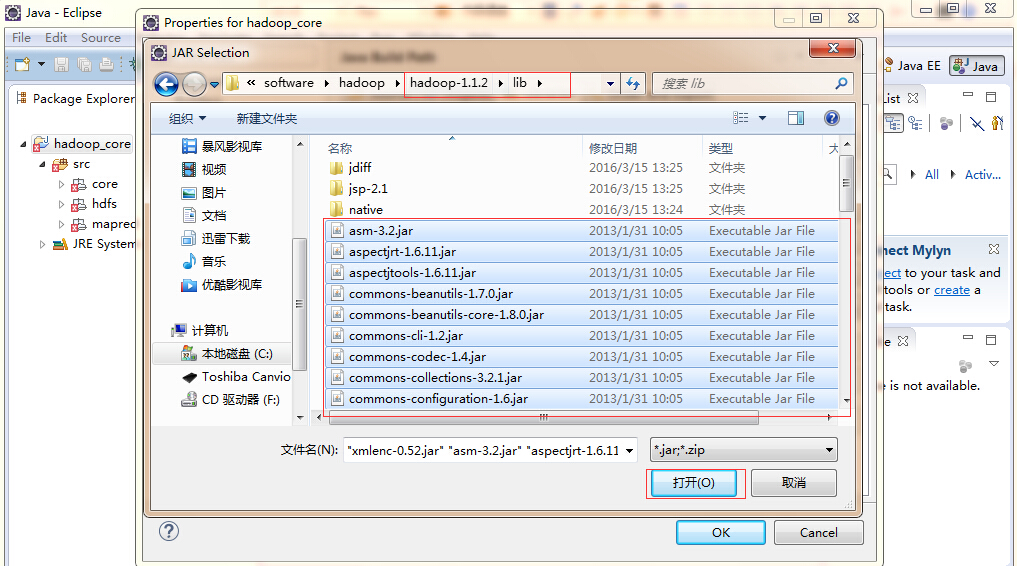
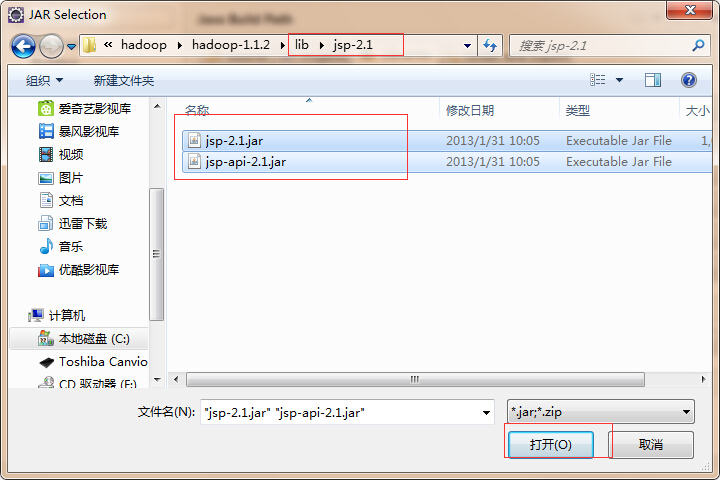
r
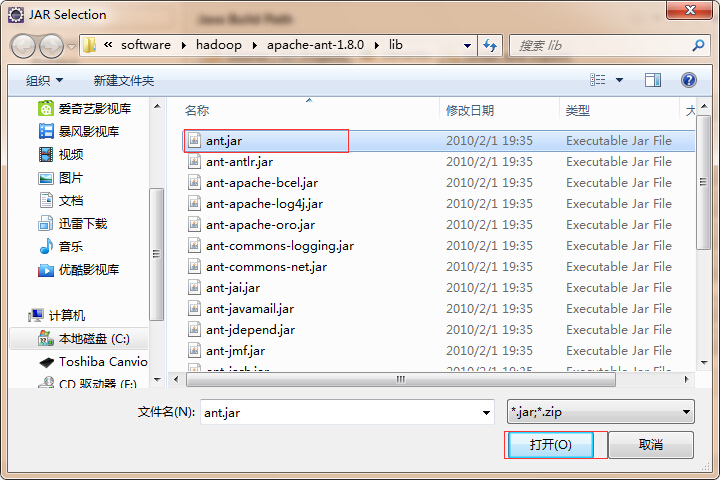
然后还需要一个ant的jar包,需要自己下载(百度搜索)apache-ant-1.8.0-bin.zip,然后解压到英文目录下,同样如上面,找到ant目录下的lib下的ant.jar,点击打开
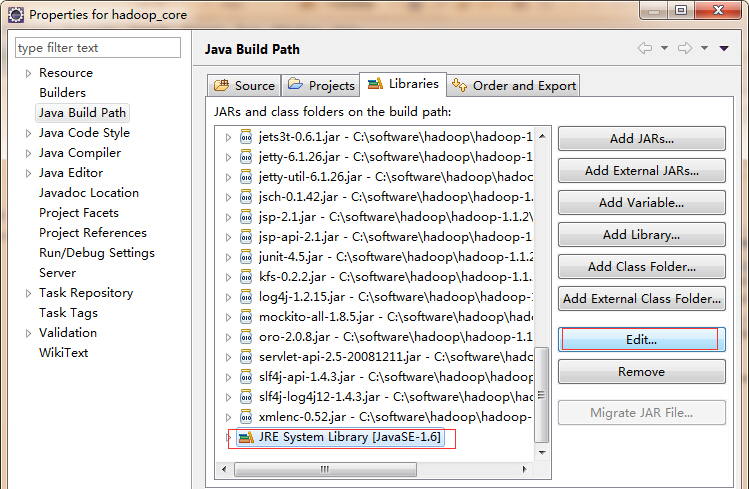
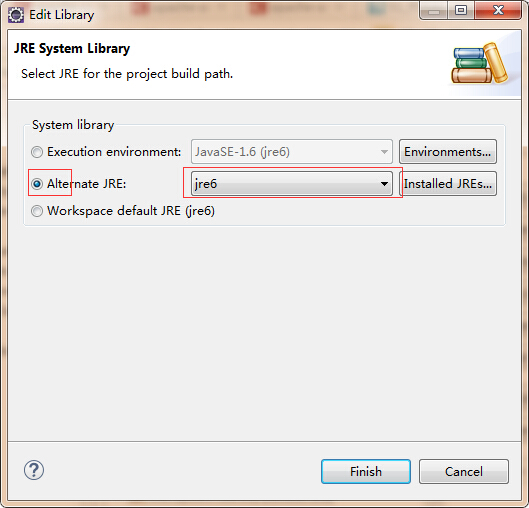
然后在library下找到jre,点击右边的编辑(选择可替换的jre)
以上这样只是方便查看源码,不要直接在这里面进行修改操作
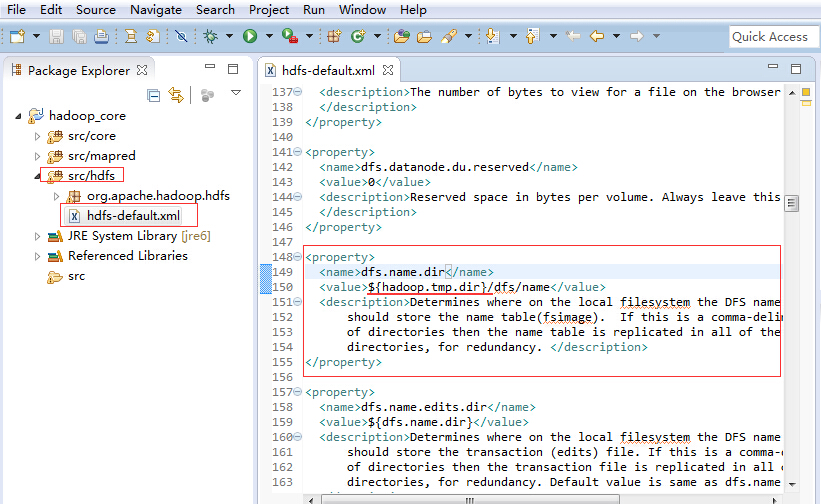
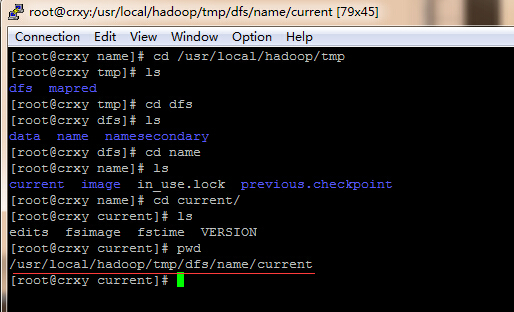
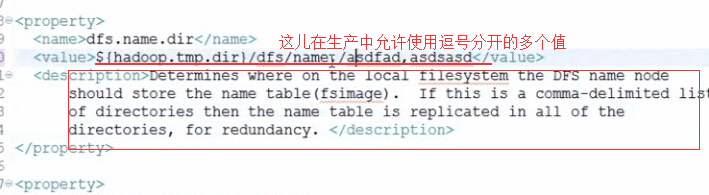
其中的逗号必须是英文下的逗号,逗号前后不能有任何的空格,并且这几个目录应该指向不同的硬盘,以便防止硬盘损坏的情况

edits保存着用户操作的事务动作(操作成功,操作失败)
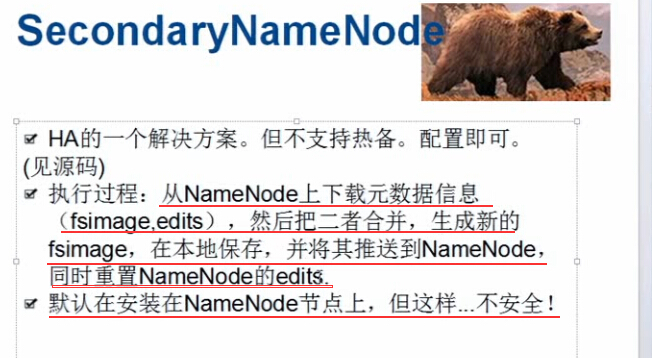
edits的内容是定期的合并到fsimage中,定期合并是有两个触发时机的:checkpoint
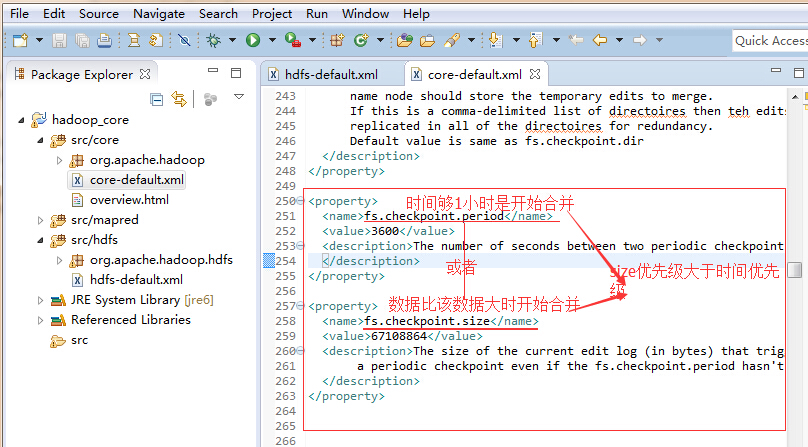
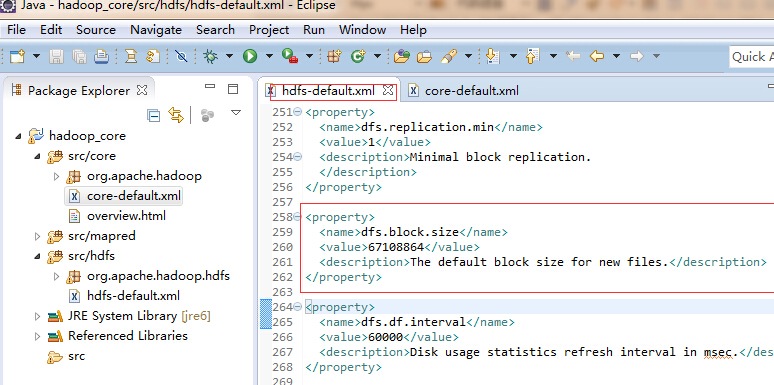
size的单位是字节,大小是64M

为什么划分块?
文件是很大的,读写速度慢;大文件独占资源,并发率特别低;划分后损失内容不全部损失
划分多大?
默认是64兆,可修改
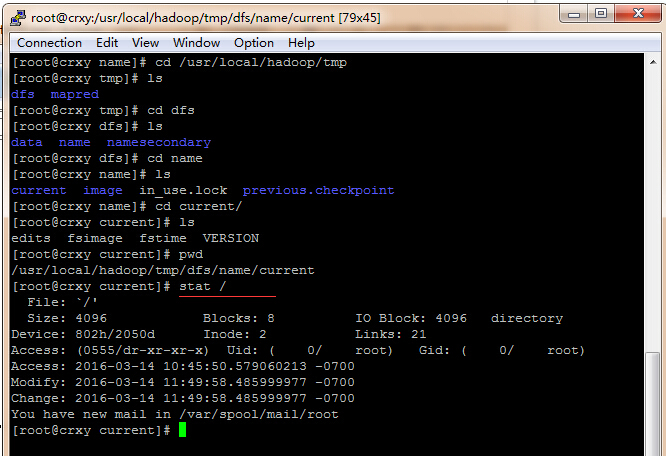
linux中的块存放数据是实际大小,而windows中的块是存放固定大学
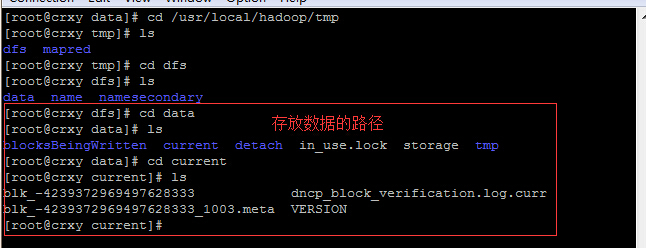
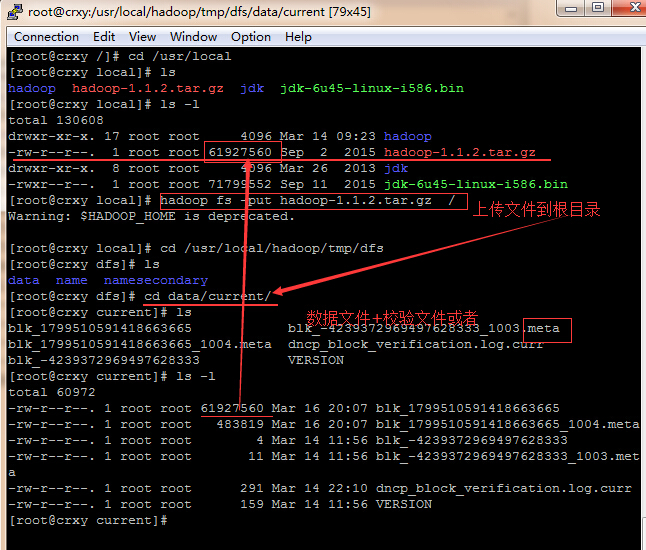
校验文件也可叫做数据指纹
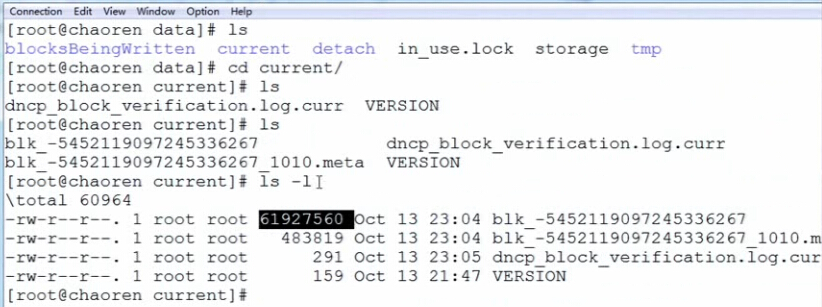

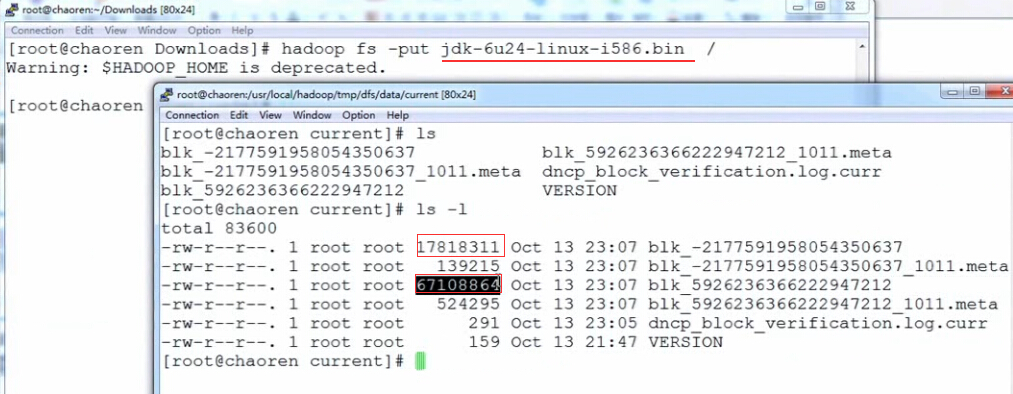
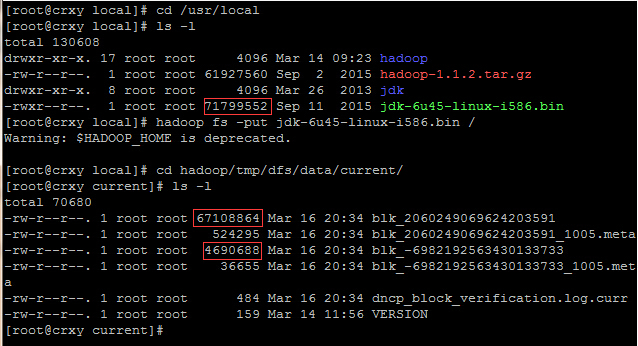
hdfs在对数据存储进行block划分时,如果文件大小超过block,那么按照block大小进行划分;不足block size的,划分为一个块,是实际数据大小。
副本数默认是3
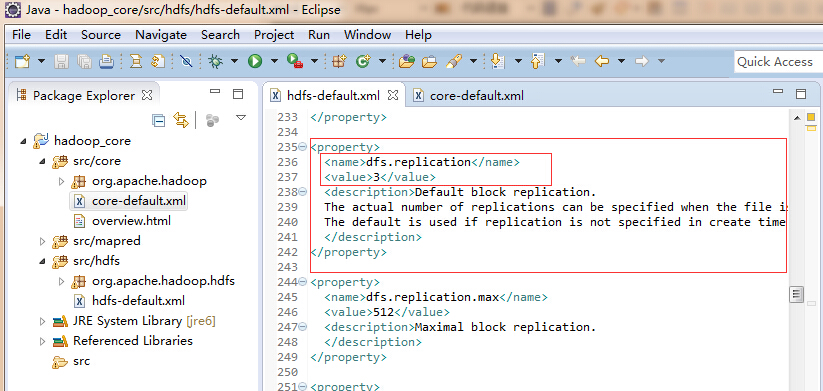
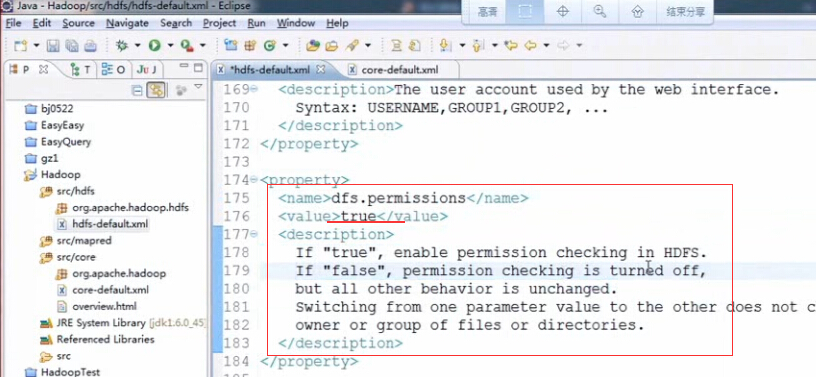
如果在不同用户下进行操作是遇到PermissionDenyException(权限不足)的问题,就是上面图中的权限设置没有改为true
1.NameNode:是整个文件系统的管理节点
a.维护整个文件系统的目录树(目录结构),文件或目录的元信息(文件或目录的详细描述信息),
每个文件对于的数据块列表;(文件是以文件块的形式存在的,这儿的文件与文件块的关系也是存放在NameNode中的)
b.接收用户的操作请求(对文件系统中文件或文件夹的一系列操作);
查看源码:
将之前传输到linux下的hadoop文件在windows下解压找到src目录文件,从中找到hdfs,core,mapred文件夹,选中它们,在eclipse中新建项目,将其粘贴到src目录下
然后选中项目名称hadoop_core,右键属性(properties)-》java build path-》source,选中里面的文件,点击remove,然后点击add file,将src下的core,hdfs和mapred文件夹添加进去
然后点击library,点击右边的add externaml jars,
找到之间解压后的hadoop文件夹下的lib文件夹,选中下面的所有jar包,点击打开,再次点击add external jars,找到lib文件夹下的jsp2.1下的两个jar包选中,点击打开
r
然后还需要一个ant的jar包,需要自己下载(百度搜索)apache-ant-1.8.0-bin.zip,然后解压到英文目录下,同样如上面,找到ant目录下的lib下的ant.jar,点击打开
然后在library下找到jre,点击右边的编辑(选择可替换的jre)
以上这样只是方便查看源码,不要直接在这里面进行修改操作
其中的逗号必须是英文下的逗号,逗号前后不能有任何的空格,并且这几个目录应该指向不同的硬盘,以便防止硬盘损坏的情况
edits保存着用户操作的事务动作(操作成功,操作失败)
edits的内容是定期的合并到fsimage中,定期合并是有两个触发时机的:checkpoint
size的单位是字节,大小是64M
为什么划分块?
文件是很大的,读写速度慢;大文件独占资源,并发率特别低;划分后损失内容不全部损失
划分多大?
默认是64兆,可修改
linux中的块存放数据是实际大小,而windows中的块是存放固定大学
校验文件也可叫做数据指纹
hdfs在对数据存储进行block划分时,如果文件大小超过block,那么按照block大小进行划分;不足block size的,划分为一个块,是实际数据大小。
副本数默认是3
如果在不同用户下进行操作是遇到PermissionDenyException(权限不足)的问题,就是上面图中的权限设置没有改为true

相关文章推荐
- HDFS分布式文件系统(伪分布式环境搭建)(第五讲)
- HDFS源码分析心跳汇报之整体结构
- hadoop环境搭建及修改配置文件(第四讲)
- Hadoop:适合大数据的分布式存储与计算平台(第三讲)
- 上传--下载HDFS文件并指定文件物理块的大小
- HDFS缓存机制
- elasticsearch之hadoop插件使用
- 运行mrunit报错问题解决
- HDFS源码分析DataXceiver之读数据块
- hadoop之VMware下centos的系统安装及虚拟机网络配置(第一讲笔记)
- HDFS均衡操作分析
- hdfs数据误删分析与恢复
- scala 删除hdfs文件demo
- HDFS+MapReduce+Hive+HBase十分钟快速入门
- HDFS工作原理
- hdfs常用的端口配置
- HDFS缓存集中管理特性:Centralized Cache Management
- HDFS下载文件报错!
- HDFS源码分析之DataXceiver
- HDFS源码分析之DataXceiverServer