一次性事务和CTE插入数据的比较
2016-03-14 10:58
267 查看
玩SQL Server的同学,有时可能要构造一些数据来做测试数据,像下面这样:
这里存在一个问题,每运行一次insert相当于commit了一次事务,数据量小的还不会出现问题,如果把要插入100万,200万,1000万
甚至更多的数据呢?既然insert语句是隐式commit的,在这个循环外面加一个显式的事务,即可显著提高插入的性能。另一种方法就是使用CTE也可
以一次把数据插入到表中,从而提高性能。现在就这两种方法插入数据的性能来做一个比较。没有结果之前,猜猜哪种速度更快?或者两者差不多?
首先是加事务,插入100万条记录:
我的机器上测试多次,取平均值,大概使用了22秒即可完成100万条记录的插入,速度还是挺快的。(如果没有加显式事务,要多久才能完成呢?有兴趣的朋友可以试下

)
下面是使用CTE:
也是测试多次取平均值,竟然是5秒左右就完成,大大出乎我的意料!现在改为插入1000万条记录,看结果如何。前者只需把code-2中的1000000修改为10000000,再运行即可。后者由于CTE1的记录数不够,需要UNION ALL两次,代码如下:
code-4
测试结果:加事务的插入大概需要3分多钟,而CTE则不超过1分半钟的时间就完成了。看来还是CTE更高效啊!在测试过程中,发现内存的使用量不多,但CPU的使用有较明显的提高。此外,插入大数据到表中,有无索引和日志恢复模式也会影响插入的性能。
补充一下CTE1中记录数的生成。如果只需要100万的数据量,只需要master.sys.databases表CROSS
JOIN自己一次就可以了,或者找两张表CROSS JOIN后数据更接近的所需就更好了,不够的可以UNIONL
ALL几次。那如果需要1000万或更大的记录数,可以在此基础上再CROSS JOIN一次一张小表,比如:
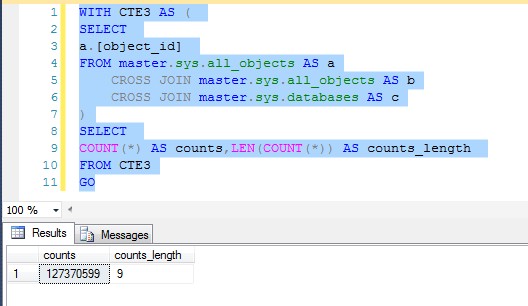
figure-1
我的机器上生成了1亿1多千万条记录。
本文出自 “FishParadise” 博客,请务必保留此出处http://fishparadise.blog.51cto.com/11284420/1750798
IF OBJECT_ID(N'T14') IS NOT NULL BEGIN DROP TABLE T14 END GO CREATE TABLE T14 (t14_id INT) GO DECLARE @i INT = 1 WHILE @i <= 1000 BEGIN INSERT INTO T14 (t14_id) SELECT @i SET @i = @i + 1 END GOcode-1
这里存在一个问题,每运行一次insert相当于commit了一次事务,数据量小的还不会出现问题,如果把要插入100万,200万,1000万
甚至更多的数据呢?既然insert语句是隐式commit的,在这个循环外面加一个显式的事务,即可显著提高插入的性能。另一种方法就是使用CTE也可
以一次把数据插入到表中,从而提高性能。现在就这两种方法插入数据的性能来做一个比较。没有结果之前,猜猜哪种速度更快?或者两者差不多?
首先是加事务,插入100万条记录:
IF OBJECT_ID(N'T14') IS NOT NULL BEGIN DROP TABLE T14 END GO CREATE TABLE T14 (t14_id INT) GO DBCC FREESESSIONCACHE DBCC DROPCLEANBUFFERS GO SET NOCOUNT ON; BEGIN TRAN DECLARE @i INT = 1 WHILE @i <= 1000000 BEGIN INSERT INTO T14 (t14_id) SELECT @i SET @i = @i + 1 END COMMIT TRAN; SET NOCOUNT OFF; GOcode-2
我的机器上测试多次,取平均值,大概使用了22秒即可完成100万条记录的插入,速度还是挺快的。(如果没有加显式事务,要多久才能完成呢?有兴趣的朋友可以试下
)
下面是使用CTE:
CREATE TABLE T15 (t15_id INT) GO DBCC FREESESSIONCACHE DBCC DROPCLEANBUFFERS GO WITH CTE1 AS ( SELECT a.[object_id] FROM master.sys.all_objects AS a CROSS JOIN master.sys.all_objects AS b ) ,CTE2 AS ( SELECT ROW_NUMBER() OVER (ORDER BY [object_id]) as row_no FROM CTE1 ) INSERT INTO T15 (t15_id) SELECT row_no FROM CTE2 WHERE row_no <= 1000000 GOcode-3
也是测试多次取平均值,竟然是5秒左右就完成,大大出乎我的意料!现在改为插入1000万条记录,看结果如何。前者只需把code-2中的1000000修改为10000000,再运行即可。后者由于CTE1的记录数不够,需要UNION ALL两次,代码如下:
CREATE TABLE T15 (t15_id INT) GO DBCC FREESESSIONCACHE DBCC DROPCLEANBUFFERS GO WITH CTE1 AS ( SELECT a.[object_id] FROM master.sys.all_objects AS a CROSS JOIN master.sys.all_objects AS b ) ,CTE2 AS ( SELECT ROW_NUMBER() OVER (ORDER BY [object_id]) as row_no FROM CTE1 ) INSERT INTO T15 (t15_id) SELECT row_no FROM CTE2 WHERE row_no <= 1000000 GO
code-4
测试结果:加事务的插入大概需要3分多钟,而CTE则不超过1分半钟的时间就完成了。看来还是CTE更高效啊!在测试过程中,发现内存的使用量不多,但CPU的使用有较明显的提高。此外,插入大数据到表中,有无索引和日志恢复模式也会影响插入的性能。
补充一下CTE1中记录数的生成。如果只需要100万的数据量,只需要master.sys.databases表CROSS
JOIN自己一次就可以了,或者找两张表CROSS JOIN后数据更接近的所需就更好了,不够的可以UNIONL
ALL几次。那如果需要1000万或更大的记录数,可以在此基础上再CROSS JOIN一次一张小表,比如:
SELECT a.[object_id] FROM master.sys.all_objects AS a CROSS JOIN master.sys.all_objects AS b CROSS JOIN master.sys.databases AS c ) SELECT COUNT(*) AS counts,LEN(COUNT(*)) AS counts_length FROM CTE3 GOcode-5
figure-1
我的机器上生成了1亿1多千万条记录。
本文出自 “FishParadise” 博客,请务必保留此出处http://fishparadise.blog.51cto.com/11284420/1750798

相关文章推荐
- jmeter使用代理录制方法
- java.util.ConcurrentModificationException 解决办法
- KMP算法
- activiti工作流数据库表详细介绍(23张表)
- 用RxJava.Observable取代AsyncTask和AsyncTaskLoader-RxJava Android模版
- iOS使用ASCII码和NSScanner字符扫描来判断关于键盘限制输入
- 工作笔记
- LAMP(1) 在VirtualBox里安装Ubuntu Server
- WebViewJavascriptBridge的简单应用
- 11 Container With Most Water
- JAVA中基本数据类型和封装类的区别Integer和Double为例
- [Chromium中文文档]Chromium如何展示网页
- Linux Shell 重定向
- Kali 安装中国蚁剑(antSword)
- js自定义类和对象
- linux 学习之路(学linux必看)
- SDWebImage ReadMe.md 文档
- localStorage和sessionStorage的使用方法和一些特性介绍
- 手机访问pc网站自动跳转手机端网站html5代码
- IOS中block和代理