CRC查找表法推导及代码实现比较
2016-03-13 23:36
573 查看
2018/02/08 再次更新
———————————————————————————————————————————
本次更新的目的是主要进行一次再排版,顺畅文章的思路。
同时鉴于一些网友私信问我的一些问题进行解答。我自己最近再次琢磨了下CRC也发现了一些问题,会在相应章节进行细节补充,也进行勘误。
——————————————————————————————————————————
以下内容是参考网上一些大神的博客整理写出的总结,加上代码参考,仅供参考。如有疑问,欢迎大家提出一起学习交流。
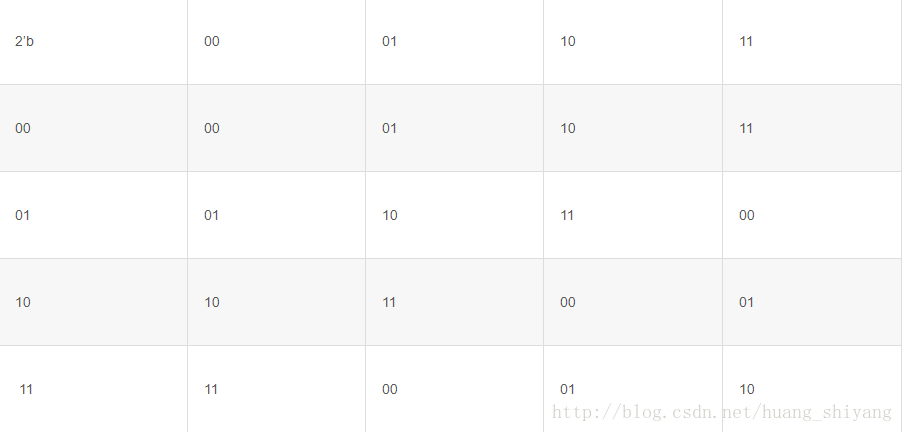
上面的结果表明,假设我传的数据 是 00 ,00那么校验和应该是00,但是实际上还有3种组合相加校验和也是00,怎么确定 原来的数据就是00,00呢,所以有3/16的概率会校验出错的,近似取1/4。(当然错一位的概率要比错两位的概率高,这点我 们不深究) 如果是N个2位数据呢,因为所有的数据结果都是均匀分配的,2位有4种结果,那么就有1/4的概率检测错误数据传输。
同理,对于字节校验有1/256的概率无法检测错误数据传输,数据的位宽越大,校验出错概率越低。
因此,CRC还算不上是好的算法, 好的算法要求数据的数据能散列的分布在检测码,CRC便应运而生。
CRC校验的原理是将数据追加结尾的nbits的0当作一个很大阶的多项式, 用它去除于另一个双方约定的多项式,得到的余 数,作为校验码,其中w为约定多项式的最大阶数, 最后传输原始数据追加检测码,其中任何一位发生变化,都导致最后得到 的结果差别很大。CRC因为容易简单实现以及容错性强, 而被广泛使用。
参考上述链接,然后跳到代码实现部分,以下是从上述算法原理的摘抄总结。
假设数据传输过程中需要发送15位的二进制信息g=101001110100001,这串二进制码可表示为代数多项式g(x) = x^14 + x^12 + x^9 + x^8 + x^7 + x^5 + 1,其中g中第k位的值,对应g(x)中x^k的系数。将g(x)乘以x^m,既将g后加m个0, 然后除以m阶多项式h(x),得到的(m-1)阶余项r(x)对应的二进制码r就是CRC编码。
h(x)可以自由选择或者使用国际通行标准,一般按照h(x)的阶数m,将CRC算法称为CRC-m,比如CRC-32、CRC-64等。国际通行标准可以参看http://en.wikipedia.org/wiki/Cyclic_redundancy_check
定义g(x) 与 h(x)的除运算是m 次循环移位异或运算,如上例g(x) 与 h(x)的除运算如下

经过迭代运算后,最终得到的r是10001100,这就是CRC效验码。
1. 每次迭代,根据gk的首位决定b,b是与gk进行运算的二进制码。若gk的首位是1,则b=h;若gk的首位是0,则b=0, 或者跳过此次迭代,上面的例子中就是碰到0后直接跳到后面的非零位。

2. 每次迭代,gk的首位将会被移出,所以只需考虑第2位后计算即可。这样就可以舍弃h的首位,将b取h的后m位。比如 CRC-8的h是111010101,b只需是11010101。
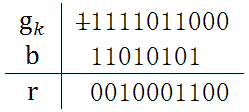
3. 每次迭代,受到影响的是gk的前m位,所以构建一个m位的寄存器S,此寄存器储存gk的前m位。每次迭代计算前先将S 的首位抛弃,将寄存器左移一位,同时将g的后一位加入寄存器。若使用此种方法,计算步骤如下:
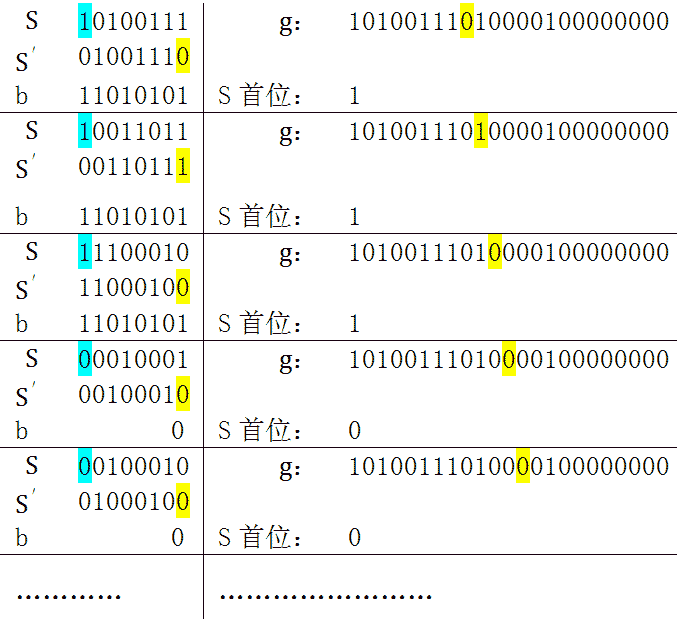
※蓝色表示寄存器S的首位,是需要移出的,b根据S的首位选择0或者h。黄色是需要移入寄存器的位。S'是经过位移后的 S。通过上述算法实现CRC运算即为直接移位的CRC算法。
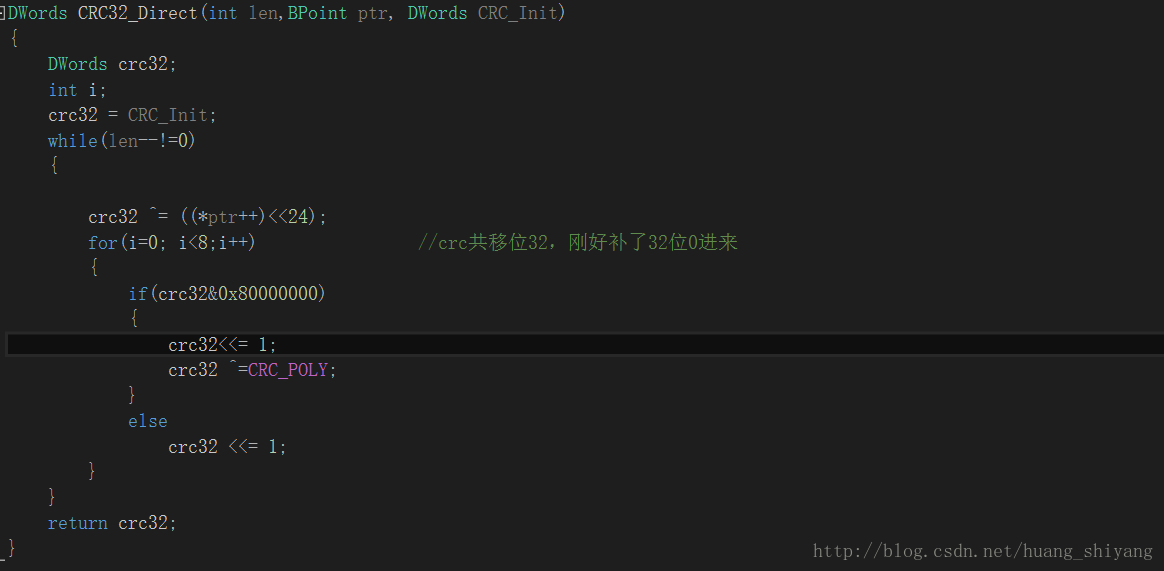
如上原理图解,直接的CRC-32校验代码如下:
————————————————————————————————————————————— 在最开始的时侯,本文特地从CRC直接运算到直接查找表法,再到改进的查找表法,后来再次接触到CRC时发现其实从直接移位运算其实就可以推到CRC 改进查找表法且并没有CRC_Init = 0 的限制,因此对本节进行更新。同时为保留原文结构,还是再次介绍直接查表法。
—————————————————————————————————————————————
移位运算的方法在大数据运算时每次一位一位的异或实际上运行效率并不高。于是便有了查找表法,最直接的查找表方式如下:以最初上面的那个例子,将数据按每4位组成1个block,这样g就被分成6个block。

下面的表展示了4次迭代计算步骤,灰色背景的位是保存在寄存器中的。
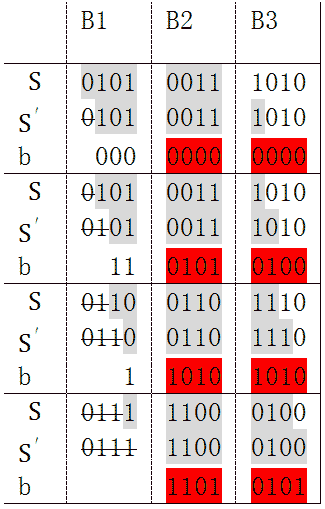
经4次迭代,B1被移出寄存器。被移出的部分我们不关心。我们关心的是这4次迭代对B2和B3产生了什么影响。注意表中红色的部分,先作如下定义:
B23 =00111010
b1 = 00000000
b2 =01010100
b3 =10101010
b4 =11010101
b' = b1 xorb2 xor b3 xor b4
4次迭代对B2和B3来说,实际上就是让它们与b1,b2,b3,b4做了xor计算,既:
B23xor b1 xor b2 xor b3 xor b4
可以证明xor运算满足交换律和结合律,于是:
B23 xor b1 xor b2 xor b3 xor b4 = B23 xor (b1 xor b2 xor b3 xor b4) = B23 xor b'
因此CRC运算满足结合率与交换率(请大家时刻记住这两条定律,后面的推导太有用了)
b1是由B1的第1位决定的,b2是由B1迭代1次后的第2位决定(既是由B1的第1和第2位决定),同理,b3和b4都是由B1决定。通过B1就可以计算出b'。另外,B1由4位组成,其一共2^4有种可能值。于是我们就可以想到一种更快捷的算法,事先将b'所有可能的值,16个值可以看成一个表;这样就可以不必进行那4次迭代,而是用B1查表得到b'值,将B1移出,B3移入,与b'计算,然后是下一次迭代。

可以看到每次迭代,寄存器中的数据以4位为单位移入和移出,关键是通过寄存器前4位查表获得,这样的算法可以大大提高运算速度。
算法过程如下:
由上图CRC32的直接查找表法实现如下:
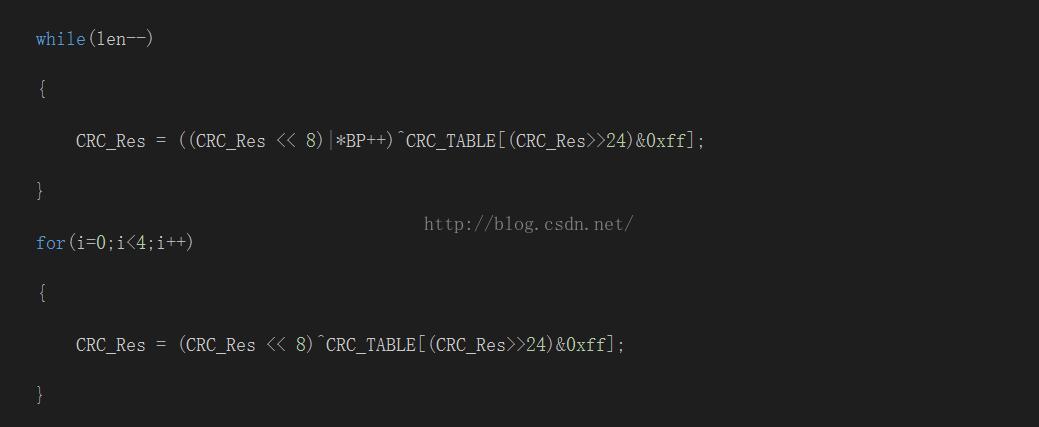
代码中最后还进行了4次CRC运算,其实参照CRC32直接移位运算,不难理解,其最后左移了4个字节0进来。上述的整个过程就是直接的CRC查找表运算。关于查找表的推导,按一位一位移位运算去理解就知道原理了, 可以发现与CRC直接移位运算代码基本差不多, 这里不再作过多描述。代码实现如下:
好了, 上面已经介绍完了CRC的直接查找表算法。聪明的你会发现,这与官方提供的CRC查找表算法有出入。是的上述的直接查找表是有问题的,其只有在CRC_Init = 0 时, 结果才正确。但是如果将CRC_Init初始为其他值时就不对了,为什么呢?
再看下直接移位运算CRC代码解析,如下:
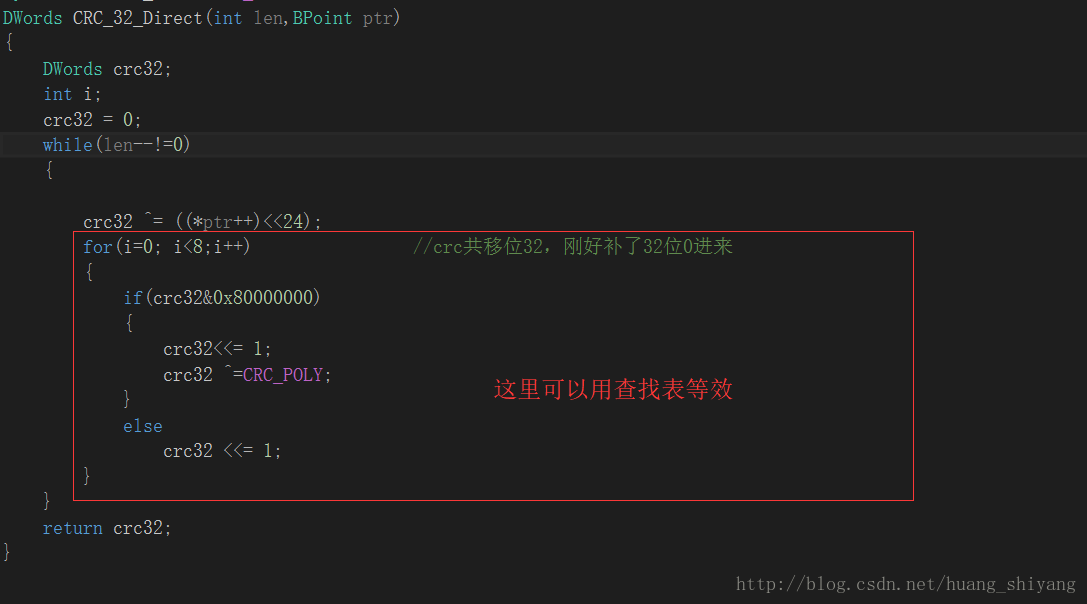
假设CRC32 初始时为(A11, A12, A13, A14)(Ai为一个字节,初始寄存器CRC_32是4个字节)
进来的字节是B1B2...Bn那么最开始作的运算是
CRC_RES = ( CRC_TABLE[A11^B1] ^(A12,A13,A14,0) = (A21,A22,A23,A24)
第二次运算是: CRC_RES = ( CRC_TABLE[A21^B2] ^(A22,A23,A24,0) = (A31,A32,A33,A34) ..... n 次迭代
CRC_RES = ( CRC_TABLE[An1^Bn] ^(An2,An3,An4,0)
因此查找表的正确写法应该如下:
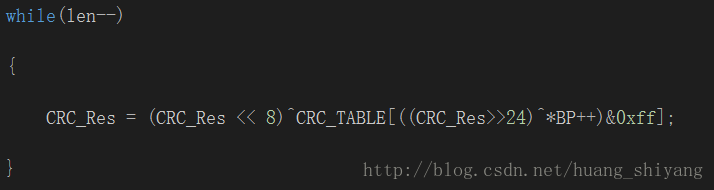
这也是本文最初说的改进查找表法,其才最最确的查找表法,无论CRC_RES初始为任意值, 其都能与直接移位运算
相对应。
再回到上文中的直接查找表法,运用结合率与交换率,进行转换 . 假设CRC_RES 初始为(A11, A12, A13, A14)
可以证明,其等价于CRC_Init = 0 , 前四个字节进来的分别是B1^A11, B2^A12, B3^A13, B4^A14,
因此, 正确的改法如下:
上述CRC_Init 可以初始为任何值对比, 可以发现改进的查找表简洁直观多了。
———————————————————————————————————————————— 我是后来发现可以从代码中将循环移位直接推导到改进查找表的。网络上多是先从直接查找表到改进查找表。现在想来一开始应该就是从循环移位直接推到官方提供的查找表方法。但是作为补充,我这里两个方法都再列出来了。
————————————————————————————————————————————
由于我们用实际字节存储的时候, 都是LSBF(least significant bit first)。 而我们原来里面是用的MSBF, 也就是说, 在原算法中, 我们需要:把每次get_msg_byte都需要Reflected initial value需要reflected。最后的结果需要reflected下
字节在读进行时先做一次字节翻转如下:
镜像查找表:
以crc的低字节为0b10000000为例
其实际值应该是0x01,但是get_msg_byte = 0x80
对于get_msg_byte 正向 table[0x01]= 0x04C11DB7
所以反向table[0x10]=reflect(0x4C11DB7)=0xEDB88320
注意这里的table, 是用reflected的多项式生成的,initial value也是reflected的. 为了get_msg_byte不需要reflect, 那么table中, index也是被reflected了.代码实现如下:
双字翻转
镜像表的生成:
逆向CRC32镜像表的使用:

CRC校验的由来及查找表的推导到此已经完成,接下来说CRC的一些可变参数。
* 多项式的w, 以及多项式
* initial value
* 做处理的时候是 MSBF还是LSBF
* final register (同initial value, 为了区分不同的crc, 当同一个消息时,所以定义了最后的xor final register)
相应国际标准可参考http://en.wikipedia.org/wiki/Cyclic_redundancy_check CRC初始值的选择 从上文知道,对于一个指定的数据串,只有当CRC初始值为0时,直接查找法与改进查找法的值才是相同的。也就当CRC初始化为其他值时,用优化的查找算法得到的值与直接查找法是不同的。 但是将CRC初始化为0,存在一个问题:那就是当传输的数据为前面都为0时,如下: Data1:
Data2:
CRC(Data1)=CRC(Data2) 在数据传输过程若出现字节丢失,CRC校验是无法察觉的(多数CRC在底层有硬件电路检验)。 因此有必要将CRC的值初始化为一个非零的值,那么上述数据串在做CRC校验时,其CRC结果是不一样的。所以CRC初始化为0xFFFFFFFF要比初始化为0时好。 假设DATA = (D1, D2, ... Dn), 那么其等于做 CRC_INIT = 0, FF^D1, FF^D2, FF^D3, FF^D4, D5, ... Dn 的 CRC校验
有疑问的话,可以邮箱咨询我,huangshiyang7197@foxmail.com.
———————————————————————————————————————————
本次更新的目的是主要进行一次再排版,顺畅文章的思路。
同时鉴于一些网友私信问我的一些问题进行解答。我自己最近再次琢磨了下CRC也发现了一些问题,会在相应章节进行细节补充,也进行勘误。
——————————————————————————————————————————
以下内容是参考网上一些大神的博客整理写出的总结,加上代码参考,仅供参考。如有疑问,欢迎大家提出一起学习交流。
引言:
在数据传送过程中,为了能够进行错误检测,往往在数据后追加一些校验码。在讲CRC校验的由来前,先简单说一下奇偶校 验及校验和。奇偶校验:
在数据传输过程,尤其是传送串口数据时,有奇校验和偶校检,考虑如下字节: 00101100 若采用奇校验位则最后会补一位0,若采用偶校验则会补一位1。 判断补0或补1其实很简单,奇校验凑奇数个‘1’,偶校验凑偶数个’1‘。 这个校验应该算是所有数据校验中最简单的了,然而它也有不足之处:如果数据传输过程只有奇数个码位变化,那么不管 变化在哪我们判断数据传输错误是对的,但是一旦有2位发生了变化,我们就无法检测到错误,该方法的校错率是50%。校验和(累加求模):
由于奇偶校验并的校错率达50%,那么自然有了其它校验方法,常见的则是校验和,校验和顾明思义就是对传送的数据进 行相加,并将校验的结果添加到数据末端,以传送如下8位数据如下: 0x01,0xFF,0x02,0xC0 那么在传输数据时,就会往数据里面再加上一个校验字节(如果字数据加一个word,以此类推),上述的校验和结果是 0xC2,这样0xC2就会被添加到数据末端。 那么校验和的校验出错的概率是多少呢,以传2个2位数为例上面的结果表明,假设我传的数据 是 00 ,00那么校验和应该是00,但是实际上还有3种组合相加校验和也是00,怎么确定 原来的数据就是00,00呢,所以有3/16的概率会校验出错的,近似取1/4。(当然错一位的概率要比错两位的概率高,这点我 们不深究) 如果是N个2位数据呢,因为所有的数据结果都是均匀分配的,2位有4种结果,那么就有1/4的概率检测错误数据传输。
同理,对于字节校验有1/256的概率无法检测错误数据传输,数据的位宽越大,校验出错概率越低。
因此,CRC还算不上是好的算法, 好的算法要求数据的数据能散列的分布在检测码,CRC便应运而生。
CRC的背景理论
CRC(Cyclic Redundancy Check,循环冗余检验)是基于数据计算一组效验码,用于核对数据传输过程中是否被更改或传输错误。CRC校验的原理是将数据追加结尾的nbits的0当作一个很大阶的多项式, 用它去除于另一个双方约定的多项式,得到的余 数,作为校验码,其中w为约定多项式的最大阶数, 最后传输原始数据追加检测码,其中任何一位发生变化,都导致最后得到 的结果差别很大。CRC因为容易简单实现以及容错性强, 而被广泛使用。
算法原理
关于算法原理, http://www.cnblogs.com/esestt/archive/2007/08/09/848856.html 作了比较详细的介绍,诸位可以参考上述链接,然后跳到代码实现部分,以下是从上述算法原理的摘抄总结。
假设数据传输过程中需要发送15位的二进制信息g=101001110100001,这串二进制码可表示为代数多项式g(x) = x^14 + x^12 + x^9 + x^8 + x^7 + x^5 + 1,其中g中第k位的值,对应g(x)中x^k的系数。将g(x)乘以x^m,既将g后加m个0, 然后除以m阶多项式h(x),得到的(m-1)阶余项r(x)对应的二进制码r就是CRC编码。
h(x)可以自由选择或者使用国际通行标准,一般按照h(x)的阶数m,将CRC算法称为CRC-m,比如CRC-32、CRC-64等。国际通行标准可以参看http://en.wikipedia.org/wiki/Cyclic_redundancy_check
定义g(x) 与 h(x)的除运算是m 次循环移位异或运算,如上例g(x) 与 h(x)的除运算如下
经过迭代运算后,最终得到的r是10001100,这就是CRC效验码。
CRC直接移位算法:
通过示例,可以发现一些规律,依据这些规律调整算法:1. 每次迭代,根据gk的首位决定b,b是与gk进行运算的二进制码。若gk的首位是1,则b=h;若gk的首位是0,则b=0, 或者跳过此次迭代,上面的例子中就是碰到0后直接跳到后面的非零位。
2. 每次迭代,gk的首位将会被移出,所以只需考虑第2位后计算即可。这样就可以舍弃h的首位,将b取h的后m位。比如 CRC-8的h是111010101,b只需是11010101。
3. 每次迭代,受到影响的是gk的前m位,所以构建一个m位的寄存器S,此寄存器储存gk的前m位。每次迭代计算前先将S 的首位抛弃,将寄存器左移一位,同时将g的后一位加入寄存器。若使用此种方法,计算步骤如下:
※蓝色表示寄存器S的首位,是需要移出的,b根据S的首位选择0或者h。黄色是需要移入寄存器的位。S'是经过位移后的 S。通过上述算法实现CRC运算即为直接移位的CRC算法。
如上原理图解,直接的CRC-32校验代码如下:
CRC直接查找表法:
2018/02/08 更新————————————————————————————————————————————— 在最开始的时侯,本文特地从CRC直接运算到直接查找表法,再到改进的查找表法,后来再次接触到CRC时发现其实从直接移位运算其实就可以推到CRC 改进查找表法且并没有CRC_Init = 0 的限制,因此对本节进行更新。同时为保留原文结构,还是再次介绍直接查表法。
—————————————————————————————————————————————
移位运算的方法在大数据运算时每次一位一位的异或实际上运行效率并不高。于是便有了查找表法,最直接的查找表方式如下:以最初上面的那个例子,将数据按每4位组成1个block,这样g就被分成6个block。
下面的表展示了4次迭代计算步骤,灰色背景的位是保存在寄存器中的。
经4次迭代,B1被移出寄存器。被移出的部分我们不关心。我们关心的是这4次迭代对B2和B3产生了什么影响。注意表中红色的部分,先作如下定义:
B23 =00111010
b1 = 00000000
b2 =01010100
b3 =10101010
b4 =11010101
b' = b1 xorb2 xor b3 xor b4
4次迭代对B2和B3来说,实际上就是让它们与b1,b2,b3,b4做了xor计算,既:
B23xor b1 xor b2 xor b3 xor b4
可以证明xor运算满足交换律和结合律,于是:
B23 xor b1 xor b2 xor b3 xor b4 = B23 xor (b1 xor b2 xor b3 xor b4) = B23 xor b'
因此CRC运算满足结合率与交换率(请大家时刻记住这两条定律,后面的推导太有用了)
b1是由B1的第1位决定的,b2是由B1迭代1次后的第2位决定(既是由B1的第1和第2位决定),同理,b3和b4都是由B1决定。通过B1就可以计算出b'。另外,B1由4位组成,其一共2^4有种可能值。于是我们就可以想到一种更快捷的算法,事先将b'所有可能的值,16个值可以看成一个表;这样就可以不必进行那4次迭代,而是用B1查表得到b'值,将B1移出,B3移入,与b'计算,然后是下一次迭代。
可以看到每次迭代,寄存器中的数据以4位为单位移入和移出,关键是通过寄存器前4位查表获得,这样的算法可以大大提高运算速度。
算法过程如下:
由上图CRC32的直接查找表法实现如下:
代码中最后还进行了4次CRC运算,其实参照CRC32直接移位运算,不难理解,其最后左移了4个字节0进来。上述的整个过程就是直接的CRC查找表运算。关于查找表的推导,按一位一位移位运算去理解就知道原理了, 可以发现与CRC直接移位运算代码基本差不多, 这里不再作过多描述。代码实现如下:
好了, 上面已经介绍完了CRC的直接查找表算法。聪明的你会发现,这与官方提供的CRC查找表算法有出入。是的上述的直接查找表是有问题的,其只有在CRC_Init = 0 时, 结果才正确。但是如果将CRC_Init初始为其他值时就不对了,为什么呢?
再看下直接移位运算CRC代码解析,如下:
假设CRC32 初始时为(A11, A12, A13, A14)(Ai为一个字节,初始寄存器CRC_32是4个字节)
进来的字节是B1B2...Bn那么最开始作的运算是
CRC_RES = ( CRC_TABLE[A11^B1] ^(A12,A13,A14,0) = (A21,A22,A23,A24)
第二次运算是: CRC_RES = ( CRC_TABLE[A21^B2] ^(A22,A23,A24,0) = (A31,A32,A33,A34) ..... n 次迭代
CRC_RES = ( CRC_TABLE[An1^Bn] ^(An2,An3,An4,0)
因此查找表的正确写法应该如下:
这也是本文最初说的改进查找表法,其才最最确的查找表法,无论CRC_RES初始为任意值, 其都能与直接移位运算
相对应。
再回到上文中的直接查找表法,运用结合率与交换率,进行转换 . 假设CRC_RES 初始为(A11, A12, A13, A14)
可以证明,其等价于CRC_Init = 0 , 前四个字节进来的分别是B1^A11, B2^A12, B3^A13, B4^A14,
因此, 正确的改法如下:
上述CRC_Init 可以初始为任何值对比, 可以发现改进的查找表简洁直观多了。
———————————————————————————————————————————— 我是后来发现可以从代码中将循环移位直接推导到改进查找表的。网络上多是先从直接查找表到改进查找表。现在想来一开始应该就是从循环移位直接推到官方提供的查找表方法。但是作为补充,我这里两个方法都再列出来了。
————————————————————————————————————————————
镜像CRC查找表法:
改进的查找表法便是我们经常见到的CRC32校验查表法。但是如果将上面的查找表生成代码生成的查找表,与CRC32提供的查找表(官方)对比,会发现完全不同,那么这又是怎么回事。刚才我们用的数据都是假设高位在前,低位在后。但是很多情况,我们传输的数据是低位在前,高位在后,这便使得对于这种逆向的数据,要么我们每次对数据进行一次翻转,要么我们可以镜像查找表。先说翻转:由于我们用实际字节存储的时候, 都是LSBF(least significant bit first)。 而我们原来里面是用的MSBF, 也就是说, 在原算法中, 我们需要:把每次get_msg_byte都需要Reflected initial value需要reflected。最后的结果需要reflected下
字节在读进行时先做一次字节翻转如下:
镜像查找表:
以crc的低字节为0b10000000为例
其实际值应该是0x01,但是get_msg_byte = 0x80
对于get_msg_byte 正向 table[0x01]= 0x04C11DB7
所以反向table[0x10]=reflect(0x4C11DB7)=0xEDB88320
注意这里的table, 是用reflected的多项式生成的,initial value也是reflected的. 为了get_msg_byte不需要reflect, 那么table中, index也是被reflected了.代码实现如下:
双字翻转
镜像表的生成:
逆向CRC32镜像表的使用:
CRC校验的由来及查找表的推导到此已经完成,接下来说CRC的一些可变参数。
可变参数
我们知道, CRC算法受到下列形态的影响* 多项式的w, 以及多项式
* initial value
* 做处理的时候是 MSBF还是LSBF
* final register (同initial value, 为了区分不同的crc, 当同一个消息时,所以定义了最后的xor final register)
相应国际标准可参考http://en.wikipedia.org/wiki/Cyclic_redundancy_check CRC初始值的选择 从上文知道,对于一个指定的数据串,只有当CRC初始值为0时,直接查找法与改进查找法的值才是相同的。也就当CRC初始化为其他值时,用优化的查找算法得到的值与直接查找法是不同的。 但是将CRC初始化为0,存在一个问题:那就是当传输的数据为前面都为0时,如下: Data1:
| 0 | 0 | 0 | 0 | 0 | 0 | A | B | C | D |
| 0 | 0 | 0 | 0 | 0 | A | B | C | D |
附录代码
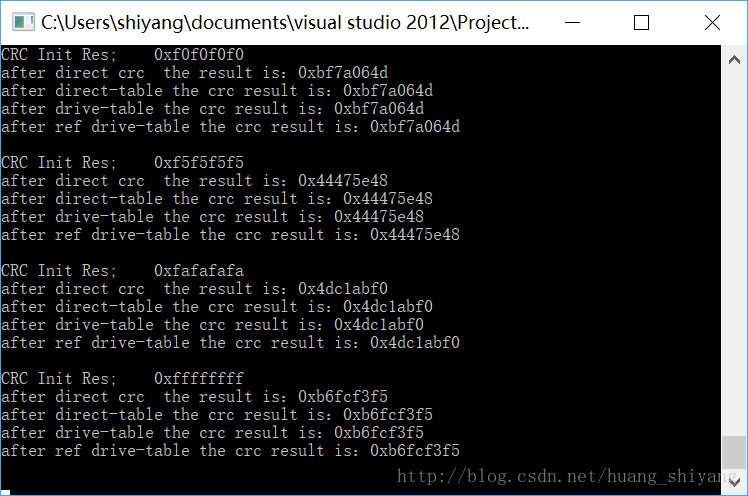
如下代码包含正向表,逆向表, 直接CRC, 直接查找表, 改进查找表,不同CRC初始值下的结果对比。#include<iostream>
using namespace std;
#define TABLE_SIZE 256
#define CRC_POLY 0x04C11DB7
//#define CRC_POLY 0xedb88320
#define LUT_LENGTH 8
#define CRC_LENGTH 32
#define DATA_SIZE 10
typedef unsigned int DWords;
typedef unsigned char Byte;
typedef unsigned char * BPoint;
typedef unsigned int uint;
DWords CRC_TABLE[TABLE_SIZE]={0};
DWords RefCRC_TABLE[TABLE_SIZE]={0};
Byte Serial_Data[DATA_SIZE]={18,51,63,47,15,132,94,87,56,41};
Byte RefSerial_Data[DATA_SIZE];
DWords CRC32_Direct(int len,BPoint ptr, DWords CRC_Init)
{
DWords crc32;
int i;
crc32 = CRC_Init;
while(len--!=0)
{
crc32 ^= ((*ptr++)<<24);
for(i=0; i<8;i++) //crc共移位32,刚好补了32位0进来
{
if(crc32&0x80000000)
{
crc32<<= 1;
crc32 ^=CRC_POLY;
}
else
crc32 <<= 1;
}
}
return crc32;
}
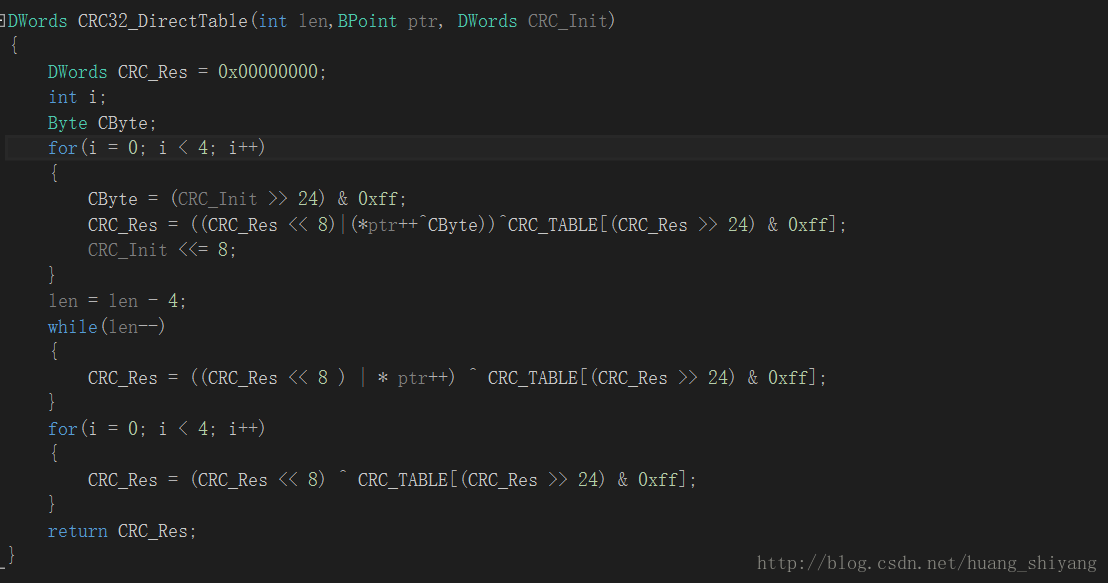
DWords CRC32_DirectTable(int len,BPoint ptr, DWords CRC_Init)
{
DWords CRC_Res = 0x00000000;
int i;
Byte CByte;
for(i = 0; i < 4; i++)
{
CByte = (CRC_Init >> 24) & 0xff;
CRC_Res = ((CRC_Res << 8)|(*ptr++^CByte))^CRC_TABLE[(CRC_Res >> 24) & 0xff];
CRC_Init <<= 8;
}
len = len - 4;
while(len--)
{
CRC_Res = ((CRC_Res << 8 ) | * ptr++) ^ CRC_TABLE[(CRC_Res >> 24) & 0xff];
}
for(i = 0; i < 4; i++)
{
CRC_Res = (CRC_Res << 8) ^ CRC_TABLE[(CRC_Res >> 24) & 0xff];
}
return CRC_Res;
}
DWords CRC32_DriveTable(int len , BPoint ptr, DWords CRC_Init)
{
DWords CRC_Res = CRC_Init;
while(len--)
{
CRC_Res = (CRC_Res << 8)^CRC_TABLE[((CRC_Res>>24)^*ptr++)&0xff];
}
return CRC_Res;
}
DWords CRC32_RfDriveTable(int len, BPoint ptr , DWords CRC_Init)
{
DWords CRC_Res = CRC_Init;
while(len--)
{
CRC_Res = (CRC_Res >> 8)^RefCRC_TABLE[(CRC_Res&0xff)^*ptr++];
}
return CRC_Res;
}
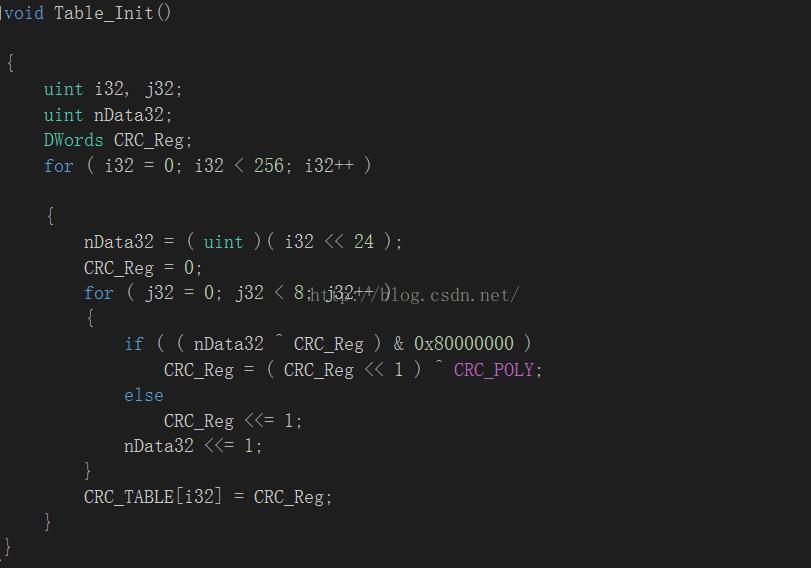
void Table_Init()
{
uint i32, j32;
uint nData32;
DWords CRC_Reg;
for ( i32 = 0; i32 < 256; i32++ )
{
nData32 = ( uint )( i32 << 24 );
CRC_Reg = 0;
for ( j32 = 0; j32 < 8; j32++ )
{
if ( ( nData32 ^ CRC_Reg ) & 0x80000000 )
CRC_Reg = ( CRC_Reg << 1 ) ^ CRC_POLY;
else
CRC_Reg <<= 1;
nData32 <<= 1;
}
CRC_TABLE[i32] = CRC_Reg;
}
}
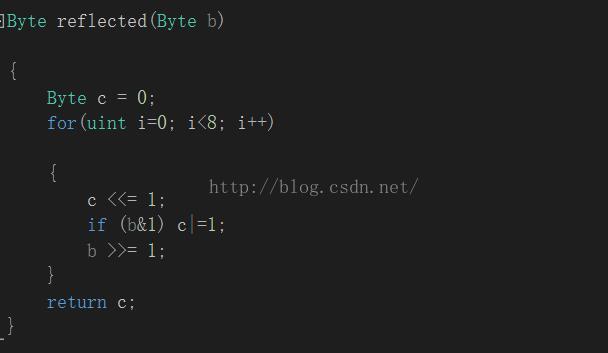
Byte reflected(Byte b)
{
Byte c = 0;
for(uint i=0; i<8; i++)
{
c <<= 1;
if (b&1) c|=1;
b >>= 1;
}
return c;
}
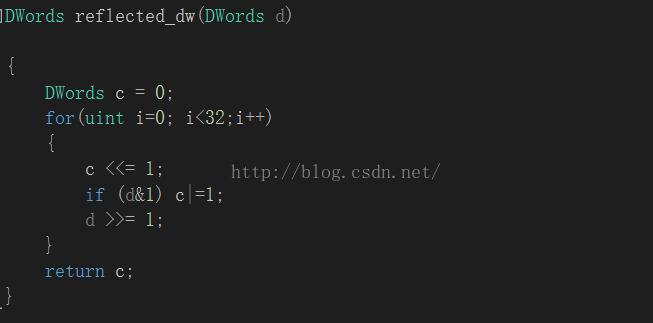
DWords reflected_dw(DWords d)
{
DWords c = 0;
for(uint i=0; i<32;i++)
{
c <<= 1;
if (d&1) c|=1;
d >>= 1;
}
return c;
}
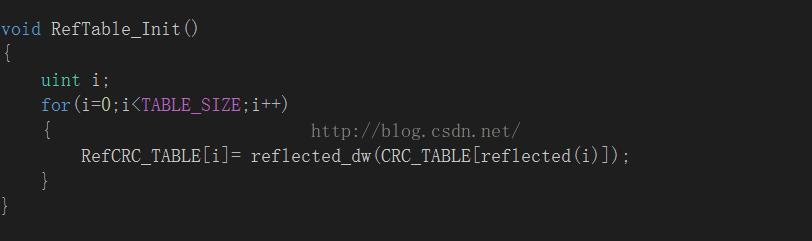
void RefTable_Init()
{
uint i;
for(i=0;i<TABLE_SIZE;i++)
{
RefCRC_TABLE[i]= reflected_dw(CRC_TABLE[reflected(i)]);
}
}
void RefData_Init()
{
uint i;
for( i = 0;i<DATA_SIZE;i++)
{
RefSerial_Data[i] = reflected(Serial_Data[i]);
}
}
int main()
{
uint i, len;
BPoint BP;
DWords CRC_Res = 0x00;
DWords CRC_Init = 0x00;
Table_Init();
RefTable_Init();
RefData_Init();
cout << "Test CRC:\n"<<endl;
for(i = 0; i < 256; i += 5)
{
CRC_Init = (i << 24) + (i <<16) + (i << 8) + i;
cout<< "CRC Init Res;\t 0x" << hex <<CRC_Init<<endl;
BP = Serial_Data;
len = DATA_SIZE;
//Direct CRC
CRC_Res = CRC32_Direct(len,BP,CRC_Init);
cout<<"after direct crc the result is:0x"<<hex<<CRC_Res<<endl;
//Direct CRC TABLE
CRC_Res = CRC32_DirectTable(len, BP, CRC_Init);
cout<<"after direct-table the crc result is:0x"<<hex<<CRC_Res<<endl;
//Drive CRC_TABLE
CRC_Res = CRC32_DriveTable(len, BP, CRC_Init);
cout<<"after drive-table the crc result is:0x"<<hex<<CRC_Res<<endl;
BP = RefSerial_Data;
CRC_Init = reflected_dw(CRC_Init);
CRC_Res = CRC32_RfDriveTable(len, BP, CRC_Init);
CRC_Res = reflected_dw(CRC_Res);
cout<<"after ref drive-table the crc result is:0x"<<hex<<CRC_Res<<endl;
cout << endl;
}
cin.get();
} 运行结果如下,可以发现四个结果均是一致的:有疑问的话,可以邮箱咨询我,huangshiyang7197@foxmail.com.

相关文章推荐
- java Jackson 库操作 json 的基本演示
- 20145312 《Java程序设计》第2周学习总结
- Spring MVC入门实例
- 第一次c++上机报告--2
- 20145321 《Java程序设计》第2周学习总结
- 3.10 java基础总结集合①迭代器iterator
- 3.9 java基础总结集合①LIst②Set③Map④泛型⑤Collections
- COM组件注册方法(VC++)
- python小白-day9 数据库操作与Paramiko模块
- 3.8 java基础总结①多线程
- Good Morning
- python小白-day8 socketserver模块
- 第二次c++上机实验
- PHP——做服务
- 详解php中switch你可能不知道的事
- python学习笔记之类class(第六天)
- 详解php中switch你可能不知道的事
- 详解php中switch你可能不知道的事
- python_dict字典常用函数小结
- php策略模式