java中集合类的一些简单总结
2016-03-12 13:29
656 查看
本人这几天在一本java教学教材中看到有集合类这一词,这到底是干嘛的,会不会是和数组一样保存多个对象,然后也可以从中取一些元素???
我先做了一张图,这样集合类各个接口各个实现类的关系就清晰了,
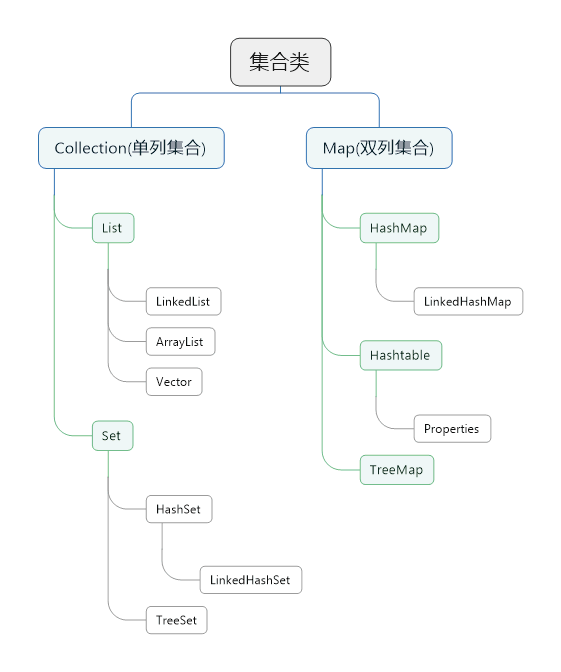
集合类分为单列集合和双列集合,先来总结一下这个单列集合。
Collection:Collectiom是单列集合的根接口,也称为超级接口,常用的子接口有List接口和Set接口,用来储存一系列符合规则的元素。
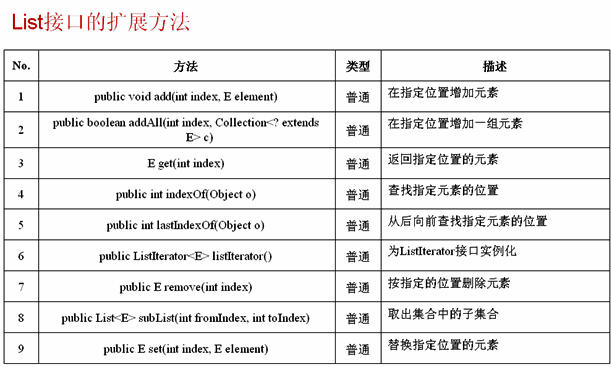
List: List接口有三个主要实现类,ArrayList,LinkedList,Vector; List具备了Collection接口的所有方法和属性;List接口中的元素是有序的,而且是可重复的;List方法如下图:
ArrayList: 在ArrayList内部封装了一个长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组来储存这些元素,因此Arraay集合可以看作一个长度可变的数组;但ArrayList 其中有个缺点,就是增加或删除指点位置的元素,会创建新的数组,因此它的效率就比较低,这个时候就要使用LinkedList集合了。下面代码是实现Arraylist的一些方法:
LinkedList: 其内部维护一个双向循环链表,链表中每一个元素都使用引用的方式来记住它的前一个元素和后一个元素,从而将所有的元素彼此连接起来,所以在增删元素的时候中具有很高的效率;下面代码是集合LinkekList的一些方法:
Vector: Vector类和ArrayList类的用法一样的,只是ArrayList的对象是异步的,而Vector的对象是同步的,所以考虑到线程安全的话就要用Vector;
下图是Vector 和Arraylist的一些同异:

Set: Set接口主要实现类有两个,HashSet ,TreeSet; Set接口的元素是无序的,并且是不可重复的。
HashSet:根据哈希值确定元素的储存位置, HashSet继承AbstractSet类,实现Set、Cloneable、Serializable接口。其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。还有一点,存入对象时,首先会调用该类的hashcode()方法和equals()方法;
LinkedHashSet: LinkedHashSet是具有可预知迭代顺序的Set接口的哈希表和链接列表实现。LinkedHashSet继承HashSet接口,有以LinkedHashMap为基来实现的。
TreeSet:TreeSet 是 利用二叉树的方法来储存元素,存入一个元素都会与其他元素进行比较,意味着必须实现Coparator接口中的CompareTo()方法;或者实现一个自定义的比较器。
粗略的讲完单列集合,接下来总结一下双列集合。
Map:Map 是双列集合的根接口,常用的实现类有*HashMap,TreeMap,HashTable;*Map接口的每一个元素都包含一个对象键Key和一个值对象Value;键与值之间存在一种一一对应的关系,这种关系叫做映射;一个键只能对应一个值,键是唯一的,不重复的,(键相等,值覆盖);
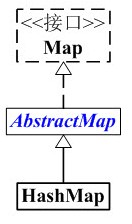
HashMap: 它是一个散列表,它储存的内容是键值对,即(key,value)映射关系,适合插入,删除,定位元素,它的key、value都可以为null。此外,HashMap中的映射不是有序的。它的实现不是同步的的,意味着它不是线程安全的。HashMap与Map的关系如下:
LinkedHashMap:LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。 LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
TreeMap:TreeMap集合是用来存储键值映射关系的,其中不允许出现重复的键,和TreeSet 一样,通过二叉树的原理来保证键的唯一性。适用于按自然顺序或自定义顺序遍历键(key)。一般情况下排序才用到TreeMap.
HashTable:表示键/值对的集合,这些键/值对根据键的哈希代码进行组织。它与HashMap相似,区别在于HashTable是线程安全的,但HashTable存取元素的速度是相当的慢,基本都被HashMap类所取代。HashTable中有一个子类Properties非常重要,Properties主要用来存储字符串中的键和值;
下面单独讲几个常用接口
Iterator接口
在没有Iterator接口之前,需要使用Enumeration接口,1Enumeration对象有两个重要方法,hasMoreElement()方法判断是否存在下一个元素;
nextElement()方法逐一取出每一个元素;
Iterator对象也叫迭代器,迭代顺序从第一个到最后一个;Iterator有两个重要方法,使用hasNext()方法判断是否存在下一个元素,如果存在,则使用next()方法将元素取出,否则说明已经到了集合末尾,停止遍历元素。注意,使用next()方法取出元素时必须保证获取的元素存在,不然就会抛出异常。
与Collection.Map有所不同,Collection主要用来存储元素,Iterator主要用来迭代访问(遍历)Collection中的元素;
说到遍历,在这里补充一个foreach循环知识点,
语法格式为:
foreach循环与for循环相比优点: 不需要获取容器的长度,不需要索引访问容器的元素;缺点:只能访问集合中的元素,不能对其中的元素进行修改。
2. ListIterator接口
ListIterator接口 是Iterator的子类,它有两个重要方法,利用hasPrevious()方法和Previous 方法实现反向迭代元素。
下面补充一个泛型的简要内容
使用<参数化类型>的方式指定该类中的方法操作的数据类型
格式例如为:
ArrayList<参数化类型> list = new ArrayList<参数化类型>();
我先做了一张图,这样集合类各个接口各个实现类的关系就清晰了,
集合类分为单列集合和双列集合,先来总结一下这个单列集合。
Collection:Collectiom是单列集合的根接口,也称为超级接口,常用的子接口有List接口和Set接口,用来储存一系列符合规则的元素。
List: List接口有三个主要实现类,ArrayList,LinkedList,Vector; List具备了Collection接口的所有方法和属性;List接口中的元素是有序的,而且是可重复的;List方法如下图:
ArrayList: 在ArrayList内部封装了一个长度可变的数组对象,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组来储存这些元素,因此Arraay集合可以看作一个长度可变的数组;但ArrayList 其中有个缺点,就是增加或删除指点位置的元素,会创建新的数组,因此它的效率就比较低,这个时候就要使用LinkedList集合了。下面代码是实现Arraylist的一些方法:
package com.jihe;
import java.util.ArrayList;
import java.util.Iterator;
public class ArrayList_1 {
public static void main(String[] args) {
ArrayList al = new ArrayList(); //创建Arraylist集合
al.add("小明 ");
al.add("小李");
al.add("小陈");
// al.clear(); // 删除集合中所有元素
// al.addAll(al); //将特定集合中的所有元素添加到该集合中
// al.remove(2); // 删除该集合中特定位置的元素
// al.removeAll(al); //删除集合中的所有元素
// al.add(1, "小黑"); // 将元素插入List集合的1处;
// Object oj = al.get(2); // 返回集合索引的index处的值(这里的index=2)
Iterator it = al.iterator(); //获得Iterator 对象 利用iterator()获得迭代器对象
while(it.hasNext()){ // 判断ArrayList集合中是否含有下个元素
System.out.println(it.next()); // 取出ArrayList集合中的元素
}
}
}LinkedList: 其内部维护一个双向循环链表,链表中每一个元素都使用引用的方式来记住它的前一个元素和后一个元素,从而将所有的元素彼此连接起来,所以在增删元素的时候中具有很高的效率;下面代码是集合LinkekList的一些方法:
package com.jihe;
import java.util.LinkedList;
public class LinkedList_1 {
public static void main(String[] args) {
LinkedList ll = new LinkedList();
ll.add("大明");
ll.add("大李");
ll.add("大陈");
// ll.add(0, "大白"); // 在列表中指定位置插入指定的元素
// ll.addFirst("大白"); // 将指定元素插入列表的开头
// Object ob = ll.removeFirst(); // 移除并返回此表的第一个元素
// Object ob1 = ll.removeLast(); //除并返回此表的最后一个元素
// System.out.println(ob);
// System.out.println(ob1);
System.out.println(ll);
}
}Vector: Vector类和ArrayList类的用法一样的,只是ArrayList的对象是异步的,而Vector的对象是同步的,所以考虑到线程安全的话就要用Vector;
下图是Vector 和Arraylist的一些同异:
Set: Set接口主要实现类有两个,HashSet ,TreeSet; Set接口的元素是无序的,并且是不可重复的。
HashSet:根据哈希值确定元素的储存位置, HashSet继承AbstractSet类,实现Set、Cloneable、Serializable接口。其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。还有一点,存入对象时,首先会调用该类的hashcode()方法和equals()方法;
LinkedHashSet: LinkedHashSet是具有可预知迭代顺序的Set接口的哈希表和链接列表实现。LinkedHashSet继承HashSet接口,有以LinkedHashMap为基来实现的。
TreeSet:TreeSet 是 利用二叉树的方法来储存元素,存入一个元素都会与其他元素进行比较,意味着必须实现Coparator接口中的CompareTo()方法;或者实现一个自定义的比较器。
粗略的讲完单列集合,接下来总结一下双列集合。
Map:Map 是双列集合的根接口,常用的实现类有*HashMap,TreeMap,HashTable;*Map接口的每一个元素都包含一个对象键Key和一个值对象Value;键与值之间存在一种一一对应的关系,这种关系叫做映射;一个键只能对应一个值,键是唯一的,不重复的,(键相等,值覆盖);
HashMap: 它是一个散列表,它储存的内容是键值对,即(key,value)映射关系,适合插入,删除,定位元素,它的key、value都可以为null。此外,HashMap中的映射不是有序的。它的实现不是同步的的,意味着它不是线程安全的。HashMap与Map的关系如下:
LinkedHashMap:LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。 LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
TreeMap:TreeMap集合是用来存储键值映射关系的,其中不允许出现重复的键,和TreeSet 一样,通过二叉树的原理来保证键的唯一性。适用于按自然顺序或自定义顺序遍历键(key)。一般情况下排序才用到TreeMap.
HashTable:表示键/值对的集合,这些键/值对根据键的哈希代码进行组织。它与HashMap相似,区别在于HashTable是线程安全的,但HashTable存取元素的速度是相当的慢,基本都被HashMap类所取代。HashTable中有一个子类Properties非常重要,Properties主要用来存储字符串中的键和值;
下面单独讲几个常用接口
Iterator接口
在没有Iterator接口之前,需要使用Enumeration接口,1Enumeration对象有两个重要方法,hasMoreElement()方法判断是否存在下一个元素;
nextElement()方法逐一取出每一个元素;
Iterator对象也叫迭代器,迭代顺序从第一个到最后一个;Iterator有两个重要方法,使用hasNext()方法判断是否存在下一个元素,如果存在,则使用next()方法将元素取出,否则说明已经到了集合末尾,停止遍历元素。注意,使用next()方法取出元素时必须保证获取的元素存在,不然就会抛出异常。
与Collection.Map有所不同,Collection主要用来存储元素,Iterator主要用来迭代访问(遍历)Collection中的元素;
说到遍历,在这里补充一个foreach循环知识点,
语法格式为:
for(容器中元素类型 临时变量:容器变量){
执行语句
}foreach循环与for循环相比优点: 不需要获取容器的长度,不需要索引访问容器的元素;缺点:只能访问集合中的元素,不能对其中的元素进行修改。
2. ListIterator接口
ListIterator接口 是Iterator的子类,它有两个重要方法,利用hasPrevious()方法和Previous 方法实现反向迭代元素。
下面补充一个泛型的简要内容
使用<参数化类型>的方式指定该类中的方法操作的数据类型
格式例如为:
ArrayList<参数化类型> list = new ArrayList<参数化类型>();
package com.jihe;
import java.util.ArrayList;
public class Fanxing {
public static void main(String[] args) {
ArrayList <String> list = new ArrayList <String>(); // 创建 ArrayList集合,使用范型
list.add("我");
list.add("爱");
list.add("你");
for(String list2:list){ // 遍历
System.out.print(list2);
}
}
}

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树