Linux基础:shell中正则表达式grep,egrep的基础用法
2016-03-12 10:58
936 查看
在Linux系统中,正则表达式(RegularExpression)是通过一些特殊字符的排列,用以查找、替换、删除等操作的强大工具,对于每一个Linux用户,都是非常重要的。
在现有的系统中,正则表达式也分为基础正则表达式(grep),扩展正则表达式(egrep)。在正式了解正则表达式之前,先了解一些相关的字符概念,它们在正则表达式中都有特殊的含义与用法。
首先介绍一下基础正则表达式grep的用法
grep [OPTIONS] PATTERN [FILE...]
常用选项:
--color=auto:对匹配到的文本着色后高亮显示;
-i:忽略字符大小写;
-o:仅显示匹配 到的文本自身;
-v, --invert-match:反向匹配;
-E:支持扩展的正则表达式;
-q, --quiet, --silient:静默模式,不输出任何信息;
对于基础正则表达式grep,使用主要通过字符进行匹配,每个特殊字符分别有不同的匹配,对于每个字符的含义将通过一些例子进行说明:
字符匹配:
. :匹配任意单个字符
[ ] :匹配范围内的任意单个字符,如[0-9],[a-z],[A-Z]...
[^ ] :匹配范围外的任意单
[:digit:]:匹配任意单个数字,0-9
[:lower:]:匹配任意单个小写字母,a-z
[:upper:]:匹配任意单个大写字母,A-Z
[:alpha:]:匹配任意单个字母,包含大小写a-z,A-Z
[:alnum:]:匹配任意单个字符,包含a-z,A-Z,0-9
[:space:]:匹配任意会产生空白的字符
例:

如上例就是对含有“p..”,即p之后跟着两个任意字符的行进行匹配
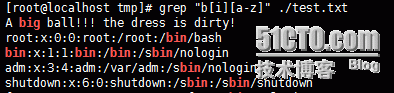
如上例就是对行中有,bi之后紧跟一个小写字母的任意字符进行匹配
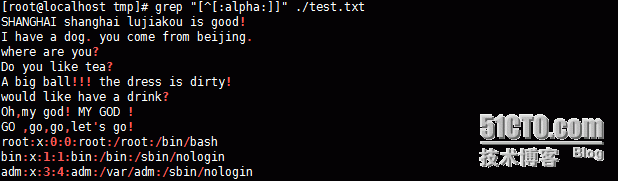
如上例是对所有不含有字符[a-zA-Z]中任意字符的行进行匹配
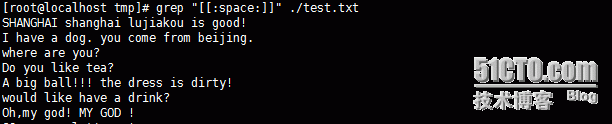
如上所示,就是对含有空格的行进行匹配
字符匹配单独使用的较少,基本都是和其它的一块使用,这里就不详细叙述了。
次数匹配:用在要指定其出现的次数的字符后面,用以限制其前面的字符要出现的次数;
*:匹配前面的字符任意次(0,1或多次);
grep "x*y":
xxxyabc:匹配3次
yabc:匹配0次
abcxy:匹配一次
abcy:匹配0次
.*:匹配任意长度的任意字符;
\+:匹配前面的字符至少1次;
grep "x\+y":
xxxyabc:匹配3次
yabc:不匹配
abcxy:匹配一次
abcy:不匹配
\?:匹配前面的0次或1次,即前面的字符可有可无;
grep "x\?y":
xxxyabc:匹配1次
yabc:匹配0次
abcxy:匹配1次
abcy;匹配0次
\{m\}:其前面的字符出现m次,m为非负整数;
grep "x\{2\}y":
xxxyabc:匹配
yabc:不匹配
abcxy:不匹配
abcy:不匹配
\{m,n\}:其前面的字符出现m次,m为非负整数;[m,n]
\{0,n\}:至多n次;
\{m,\}:至少m次;
\{m,n\}:前面的字符至多出现n次,至少m次
例:
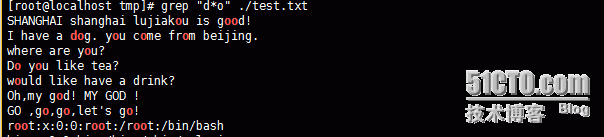
上面的例子可以看出“d*o”,对于前面的字母d,可以匹配0次,也可以匹配多次
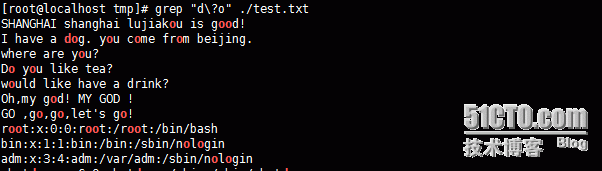
上面的例子可以看出,“d\?o”,匹配前面字母d,0次或1次,即前面的字符可有可无

“d\+o”,前面的d至少匹配一次

前面的字母o至少匹配两次
位置锁定:限制使用模式搜索文本,限制模式所匹配到的文本只能出现于目标文本的特定位置;
^:行首锁定;用于模式的最左侧,^PATTERN
$:行尾锁定;用于模式的最右侧,PATTERN$
^PATTERN$:要让PATTERN完全匹配一整行;
^$:空行;
^[[:space:]]*$:以空格为开头的,以任意字符为结尾的行
例:

以字母z开头,字母h结尾的行
单词锁定:由非特殊字符组成的连续字符(字符串)都称为单词;
\<或\b:词首锁定,用于单词模式的左侧,格式为\<PATTERN, \bPATTERN
\>或\b:词尾锁定,用于单词模式的右侧,格式为PATTERN\>, PATTERN\b
\<PATTERN\>:单词锁定;
例:

含有以字母g开头,d结尾的单词的行
一般情况下,基础正则表达式对于日常使用已相当足够,不过扩展正则表达式将使命令操作更加简化
egrep [OPTIONS] PATTERN [FILE...]
扩展正则表达式的元字符:
字符匹配:
.:任意单个字符
[ ]:范围内的任意单个字符
[^ ]:范围外的任意单个字符
匹配次数:
*:任意次;
?:0次或1次;
+:1次或多次;
{m}:匹配m次;
{m,n}:至少m次,至多n次;
位置锚定:
^:行首
$:行尾
\<, \b:词首
\>, \b:词尾
或者:a|b:a或者b
C|cat:表示C或cat
(C|c)at:表示Cat或cat
扩展正则表达式的用法较正则表达式基本相似,不过更加简单,用法也更多
例:
1.找出/proc/meminfo文件中,所有以大写或小写s开头的行;实现方法有三种
~]# egrep "^(s|S)" /tmp/meminfo:采用或的方式
~]# grep "^[sS]" /tmp/meminfo:中括号中的字母必须包含一个
~]# grep -i "^s" /tmp/meminfo:-i表示忽略字母大小写
2.echo输出一个绝对路径,使用egrep取出其基名;
~]# echo /etc/passwd/ | egrep -o "[^/]+/?$"
结果显示是/passwd,先用echo显示出路径,再采用管道,-o表示只显示匹配的结果,"[^/]+/?$"
表示,匹配结尾不含有“/”,且前面的“/”匹配0次或1次的字符
3、找出/etc/passwd文件中的三位或四位数;
~]# grep "\<[0-9]\{3,4\}\>" /etc/passwd
egrep "\<[0-9]{3,4}\>" /etc/passwd
grep还有egrep的一些简单用法就介绍到这里,以后的过程中还将持续更新!
刚开始写博客,其中有一些问题描述的不太清晰或者需要改正的,希望大家多提提意见。
本文出自 “飞越之路” 博客,请务必保留此出处http://zpf461435.blog.51cto.com/11283159/1750172
在现有的系统中,正则表达式也分为基础正则表达式(grep),扩展正则表达式(egrep)。在正式了解正则表达式之前,先了解一些相关的字符概念,它们在正则表达式中都有特殊的含义与用法。
首先介绍一下基础正则表达式grep的用法
grep [OPTIONS] PATTERN [FILE...]
常用选项:
--color=auto:对匹配到的文本着色后高亮显示;
-i:忽略字符大小写;
-o:仅显示匹配 到的文本自身;
-v, --invert-match:反向匹配;
-E:支持扩展的正则表达式;
-q, --quiet, --silient:静默模式,不输出任何信息;
对于基础正则表达式grep,使用主要通过字符进行匹配,每个特殊字符分别有不同的匹配,对于每个字符的含义将通过一些例子进行说明:
字符匹配:
. :匹配任意单个字符
[ ] :匹配范围内的任意单个字符,如[0-9],[a-z],[A-Z]...
[^ ] :匹配范围外的任意单
[:digit:]:匹配任意单个数字,0-9
[:lower:]:匹配任意单个小写字母,a-z
[:upper:]:匹配任意单个大写字母,A-Z
[:alpha:]:匹配任意单个字母,包含大小写a-z,A-Z
[:alnum:]:匹配任意单个字符,包含a-z,A-Z,0-9
[:space:]:匹配任意会产生空白的字符
例:
如上例就是对含有“p..”,即p之后跟着两个任意字符的行进行匹配
如上例就是对行中有,bi之后紧跟一个小写字母的任意字符进行匹配
如上例是对所有不含有字符[a-zA-Z]中任意字符的行进行匹配
如上所示,就是对含有空格的行进行匹配
字符匹配单独使用的较少,基本都是和其它的一块使用,这里就不详细叙述了。
次数匹配:用在要指定其出现的次数的字符后面,用以限制其前面的字符要出现的次数;
*:匹配前面的字符任意次(0,1或多次);
grep "x*y":
xxxyabc:匹配3次
yabc:匹配0次
abcxy:匹配一次
abcy:匹配0次
.*:匹配任意长度的任意字符;
\+:匹配前面的字符至少1次;
grep "x\+y":
xxxyabc:匹配3次
yabc:不匹配
abcxy:匹配一次
abcy:不匹配
\?:匹配前面的0次或1次,即前面的字符可有可无;
grep "x\?y":
xxxyabc:匹配1次
yabc:匹配0次
abcxy:匹配1次
abcy;匹配0次
\{m\}:其前面的字符出现m次,m为非负整数;
grep "x\{2\}y":
xxxyabc:匹配
yabc:不匹配
abcxy:不匹配
abcy:不匹配
\{m,n\}:其前面的字符出现m次,m为非负整数;[m,n]
\{0,n\}:至多n次;
\{m,\}:至少m次;
\{m,n\}:前面的字符至多出现n次,至少m次
例:
上面的例子可以看出“d*o”,对于前面的字母d,可以匹配0次,也可以匹配多次
上面的例子可以看出,“d\?o”,匹配前面字母d,0次或1次,即前面的字符可有可无
“d\+o”,前面的d至少匹配一次
前面的字母o至少匹配两次
位置锁定:限制使用模式搜索文本,限制模式所匹配到的文本只能出现于目标文本的特定位置;
^:行首锁定;用于模式的最左侧,^PATTERN
$:行尾锁定;用于模式的最右侧,PATTERN$
^PATTERN$:要让PATTERN完全匹配一整行;
^$:空行;
^[[:space:]]*$:以空格为开头的,以任意字符为结尾的行
例:
以字母z开头,字母h结尾的行
单词锁定:由非特殊字符组成的连续字符(字符串)都称为单词;
\<或\b:词首锁定,用于单词模式的左侧,格式为\<PATTERN, \bPATTERN
\>或\b:词尾锁定,用于单词模式的右侧,格式为PATTERN\>, PATTERN\b
\<PATTERN\>:单词锁定;
例:
含有以字母g开头,d结尾的单词的行
一般情况下,基础正则表达式对于日常使用已相当足够,不过扩展正则表达式将使命令操作更加简化
egrep [OPTIONS] PATTERN [FILE...]
扩展正则表达式的元字符:
字符匹配:
.:任意单个字符
[ ]:范围内的任意单个字符
[^ ]:范围外的任意单个字符
匹配次数:
*:任意次;
?:0次或1次;
+:1次或多次;
{m}:匹配m次;
{m,n}:至少m次,至多n次;
位置锚定:
^:行首
$:行尾
\<, \b:词首
\>, \b:词尾
或者:a|b:a或者b
C|cat:表示C或cat
(C|c)at:表示Cat或cat
扩展正则表达式的用法较正则表达式基本相似,不过更加简单,用法也更多
例:
1.找出/proc/meminfo文件中,所有以大写或小写s开头的行;实现方法有三种
~]# egrep "^(s|S)" /tmp/meminfo:采用或的方式
~]# grep "^[sS]" /tmp/meminfo:中括号中的字母必须包含一个
~]# grep -i "^s" /tmp/meminfo:-i表示忽略字母大小写
2.echo输出一个绝对路径,使用egrep取出其基名;
~]# echo /etc/passwd/ | egrep -o "[^/]+/?$"
结果显示是/passwd,先用echo显示出路径,再采用管道,-o表示只显示匹配的结果,"[^/]+/?$"
表示,匹配结尾不含有“/”,且前面的“/”匹配0次或1次的字符
3、找出/etc/passwd文件中的三位或四位数;
~]# grep "\<[0-9]\{3,4\}\>" /etc/passwd
egrep "\<[0-9]{3,4}\>" /etc/passwd
grep还有egrep的一些简单用法就介绍到这里,以后的过程中还将持续更新!
刚开始写博客,其中有一些问题描述的不太清晰或者需要改正的,希望大家多提提意见。
本文出自 “飞越之路” 博客,请务必保留此出处http://zpf461435.blog.51cto.com/11283159/1750172

相关文章推荐
- Shell基础(五):条件判断与流程控制
- Bash脚本编程总结
- 关于shell局部变量和全局变量
- shell订时检测sshd的端口
- linux下shell编程梳理
- 查找两个文件包含的字符串或不包含的字符串shell脚本
- 在 Visual Studio Code 中使用 PoweShell - CodeShell
- 系统加固shell脚本
- shell中正则的用法(grep sed awk)
- shell数组用法
- adb shell commands
- shellinabox安装
- shell 逻辑表达式汇总(if,大小比较)
- shell 脚本
- Unix-Shell
- shell 自动重启nginx php shell脚本
- Linux常用shell命令大全
- spark-shell 执行脚本并传入参数
- LinuxShell学习笔记
- telnet不能用!提示:-bash: telnet: command not found