速度Spark为什么能够把云计算大数据的速度提高到100倍以上
2016-03-11 20:47
507 查看
**
1、基于内存计算
**Hadoop**  shuffle 70%决定了效率 map->reduce 每次计算结果放到磁盘上(容错,容灾),io网络开销都比较大 **Spark** 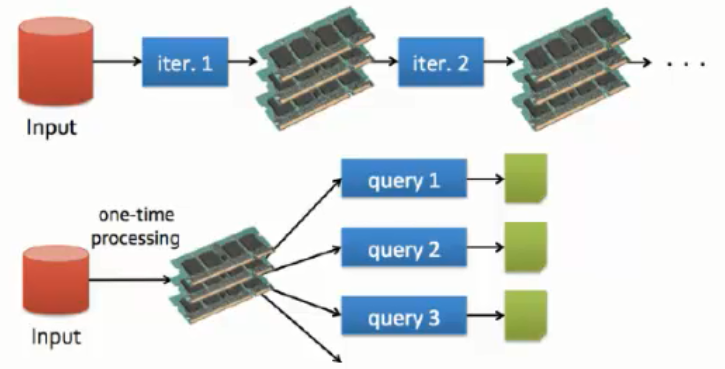 当然对内存要求比较大
2、DAG 有向无环图
对数据的操作首先记录下来,暂时不执行(transform阶段),具体要结果的时候(reduceByKey)才会执行
3、任务调度机制( Scheduler)
一个虚拟机可以开多个任务 Spark不同任务间可以共享数据(内存级别) Hadoop中不同任务共享数据--磁盘
4、容错机制(Lineage)
Hadoop中一个节点出错要重新运行

相关文章推荐
- 云计算+大数据+深度学习+人工智能+量子计算=?
- 云计算与openstack介绍
- 【云计算】基于Ansible的自动部署平台化思路
- 云计算的文档管理软件与过去的相比具备哪些优势?
- 一句话说出你对云计算的理解
- 了解云计算与虚拟化
- 江湖风云再起——全球最高性价比私有云平台解决方案发布
- 云计算学习
- 从IaaS的云计算到智慧城市,这绝对是未来的方向!
- Cloud Insight 和 BearyChat 第一次合体,好紧张!
- 云计算
- 云计算工具,框架,服务简单介绍
- OpenStack云计算快速入门之三:OpenStack镜像管理
- OpenStack云计算快速入门之二:OpenStack安装与配置
- OpenStack云计算快速入门之一:OpenStack及其构成简介
- wemall微信商城云平台 快速创建您的微信商城
- Discuz! X3.1直接进入云平台列表的方法
- Zoho CEO:云计算泡沫巨大 Salesforce只是新的Siebel
- 如何理解云计算
- 【云计算】Netflix 开源持续交付平台 Spinnaker