PCA降维
2016-03-11 09:30
225 查看
1.1算法流程
假设有m个samples,每个数据有n维。1. 计算各个feature的平均值,计μj ;(Xj(i)表示第i个样本的第j维特征的value)
μj = Σm Xj(i)/m
meanVals = mean(dataMat, axis=0)
2. 将每一个feature scaling:将在不同scale上的feature进行归一化;
3. 将特征进行mean normalization
Xj(i)= (Xj(i)-μj)/sj
meanRemoved = dataMat - meanVals #remove mean
4. 求n×n的协方差矩阵Σ:

covMat = cov(meanRemoved, rowvar=0)
5.求取特征值和特征向量:
[U,S,V] = SVD(Σ)
eigVals,eigVects = linalg.eig(mat(covMat))
6. 按特征值从大到小排列,重新组织U
如果使用否则的话应进行排序,并按照该次序找到对应的特征向量重新排列。
eigValInd = argsort(eigVals)
7. 选择k个分量
按照第五、六步中讲的后,我们得到了一个n×n的矩阵Σ和U,这时,我们就需要从U中选出k个最重要的分量;即选择前k个特征向量,即为Ureduce, 该矩阵大小为n×k
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions

这样对于一个n维向量x,就可以降维到k维向量z了:

1.2、PCA降维实验
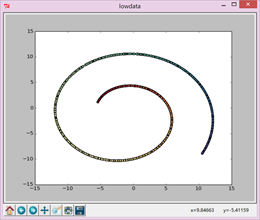
老师给的数据swissroll.dat

自己生成数据:
def make_swiss_roll(n_samples=100, noise=0.0, random_state=None):
#Generate a swiss roll dataset.
t = 1.5 * np.pi * (1 + 2 * random.rand(1, n_samples))
x = t * np.cos(t)
y = 83 * random.rand(1, n_samples)
z = t * np.sin(t)
X = np.concatenate((x, y, z))
X += noise * random.randn(3, n_samples)
X = X.T
t = np.squeeze(t)
return X, t
1、Y=100*random.rand(1,2000)
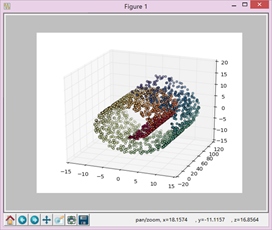

2、y=21*random.rand(1,2000)


2、y=1*random.rand(1,2000)

1.3、PCA
降维实验小结
可以看到,当y的变化幅度较小时,最后降维之后的数据更类似于x,z轴数据,当y变化较大时,更类似于变化较大的y和x。
相关文章推荐
- Linux 字符设备驱动模型
- Linux 内核链表
- Linux socket编程基础
- ARM 平台上的Linux系统启动流程
- Linux 系统调用过程
- android 换肤功能的实现
- Linux 内核模块编写与安装
- 让Qt应用程序跑在Android上
- url调用页面的方法
- JavaScript高级程序设计(第三版)学习笔记6、7章
- Hive--HiveQL:数据定义、数据操作
- java反射之获取Class对象
- web 应用加速方案:Varnish
- 开源的围棋软件
- oracle数据库迁移至mysql 之 sysdate格式化及运算替换
- HBase总结(十二)Java API 与HBase交互实例
- 关东升的《从零开始学Swift》3月9日已经上架
- 选择一个开源协议
- 《学习笔记》目前几种稀疏目标跟踪算法
- [BZOJ 1475]方格取数