CentOS6.7+jdk8+hadoop2.7.1+hbase1.1.3+hive2.0.0+scala2.11.7+spark1.6集群安装!!!
2016-03-10 00:00
1166 查看
集群规划如下:
(在安装的过程中注册个hadoop用户,密码也为hadoop)
注意:后面所有操作我都是以root用户权限进行的,实验环境下这样方便操作
NETWORKING=yes
HOSTNAME=hadoop0
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:x.x.x.x 子网掩码:x.x.x.x 网关:x.x.x.x -> apply
192.168.43.100 hadoop0
192.168.43.101 hadoop1
192.168.43.102 hadoop2
关闭防火墙开机启动
#chkconfig iptables off
然后打开Xshell 远程连上linux虚拟机hadoop0上

依次点击:窗口>传输新建文件>取消>一次性接受。
连上后输入put 回车后即可上传文件


红色标记即为要上传的
将公钥拷贝到要免登陆的机器上
# ssh-copy-id -i localhost
测试是否还需要密码?
#ssh localhost
# tar -zxvf jdk-8u74-linux-x64.gz -C /home/hadoop/java/
将java添加到环境变量中
#vim /etc/profile
在文件最后添加
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
export PATH=$PATH:$JAVA_HOME/bin
保存退出后,刷新配置
#source /etc/profile
像下图 就OK了

第一个:hadoop-env.sh
#vim hadoop-env.sh

第二个:core-site.xml
#vim core-site.xml
<configuration>
<property>
<!—指定NameNode的地址 -->
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hp/hadoop-2.7.1/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
第四个:mapred-site.xml
此文件默认没有,可将所给模版复制一份
#cp mapred-site.xml.template mapred-site.xml
#vim mapred-site.xml
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<!—设置reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第六个:slaves
# vim slaves
hadoop1
hadoop2
export HADOOP_HOME=/home/hadoop/hp/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#source /etc/profile
2.4格式化namenode(在hadoop0上执行)
#hdfs namenode -format 或#hadoop namenode –format(第一次运行hadoop集群时执行)2.5启动hadoop
#cd /home/hadoop/hp/hadoop-2.7.1/sbin
#./start-all.sh (已不推荐)
或者:
先启动HDFS
#./start-dfs.sh
再启动YARN
#./start-yarn.sh

http://192.168.8.118:50070 (HDFS管理界面)

http://192.168.8.118:8088 (MR管理界面)

注意:haoop2.X已经没有50030,新的yarn架构默认是8088,也没有tasktracker 与jobtracker 进程了,为什么?请看这里http://www.aboutyun.com/thread-7678-1-1.html
补充:若要将SecondaryNameNode放在其它节点启动,如在hadoop1上,配置如下:
# vim masters(此文件hadoop2.7默认不存在)
Hadoop1
#vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop0:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
</configuration>
然后在hadoop0执行:# rsync -az /home/hadoop/ root@hadoop1:/home/hadoop/
#rsync -az /home/hadoop/ root@hadoop2:/home/hadoop/
排错:启动和关闭hadoop 时都会有如下警告

如何解决请参考http://f.dataguru.cn/thread-376971-1-1.html
添加环境变量
#vim /etc/profile
export HBASE_HOME=/home/hadoop/hbase/hbase-1.1.3
export PATH=$PATH:$HBASE_HOME/bin
刷新
#source /etc/profile
2.0.配置hbase集群 要修改3个文件
#cd /home/hadoop/hbase/hbase-1.1.3
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
//告诉hbase,hadoop 的配置文件路径
export HBASE_CLASSPATH=/home/hadoop/hp/hadoop-2.7.1/etc/hadoop
//告诉hbase使用默认自带的 Zookeeper
export HBASE_MANAGES_ZK=true
<configuration>
<property>
<name>hbase.master</name>
<value>hadoop0:60000</value>
</property>
<property>
<!-- 指定hbase在HDFS上存储的路径 -->
<name>hbase.rootdir</name>
<value>hdfs://hadoop0:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop0:2181,hadoop1:2181,hadoop2:2181</value>
</property>
</configuration>
hadoop1
hadoop2

访问HBase的master web页面: http://192.168.43.100:16010

访问HBase的regionserver web页面: http://192.168.43.102:16030

若要进入hbase的shell终端,执行:# hbase shell

在hadoop1/hadoop2上查看:# jps

关闭hbase,在hadoop0上执行:# stop-hbase.sh

排错:如果没有HMaster,说明与hadoop的连接有问题,如果没有HRegionServer有可能是集群时间不同步
2.0.配置hive环境变量,初始化hive在hdfs上的工作目录
# vim /etc/profile
export HIVE_HOME= /home/hadoop/hive/apache-hive-2.0.0-bin
export PATH = $HIVE_HOME/bin:$PATH
# source /etc/profile 使修改的环境变量立即生效
初始化hadoop 环境变量
#hadoop fs -mkdir /tmp
#hadoop fs –mkdir -p /usr/hive/warehouse
#hadoop fs -chmod g+w /tmp
#hadoop fs -chmod g+w /usr/hive/warehouse
配置hive相关的配置文件:/home/hadoop/hive/apache-hive-2.0.0-bin/conf/目录下
#cp hive-env.sh.template hive-env.sh
#cp hive-default.xml.template hive-site.xml
#cp hive-log4j2.properties.template hive-log4j2.properties
#cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
运行hive:
#cd /home/hadoop/hive/apache-hive-2.0.0-bin
#./bin/hive
默认将会进入hive的控制台
执行:# show tables; //如果不出错,则表明默认版本的hive安装成功

此时再打开一个终端执行:# jps

此种为默认配置,hive的metastore保存在一个叫derby的数据库的,该
数据库是一个嵌入式数据库,如果同时有两个人或者多个人操作,就会报错。
排错:运行hive时报错如下

按提示执行:# schematool -dbType derby -initSchema
又报如下错:

执行:# rm -rf $HIVE_HOME/metastore_db
这样问题解决了…………….
当报如下错时:

# mkdir /home/hadoop/hive/apache-hive-2.0.0-bin/iotmp
#vim /home/hadoop/hive/apache-hive-2.0.0-bin/conf/hive-site.xml

再次启动hive就好了。
export SCALA_HOME=/home/hadoop/scala/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin
#source /etc/profile

export SPARK_HOME=/home/hadoop/spark/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:$ SPARK_HOME/bin
2.2修改配置文件(# cd /home/hadoop/spark/spark-1.6.0-bin-hadoop2.6/conf)
# cp spark-env.sh.template spark-env.sh
#vim spark-env.sh
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
export SCALA_HOME=/home/hadoop/scala/scala-2.11.7
export SPARK_MASTER_IP=192.168.43.100
export SPARK_WORKER_MEMORY=512M
export HADOOP_CONF_DIR=/home/hadoop/hp/hadoop-2.7.1/etc/hadoop
# cp slaves.template slaves
#vim slaves
hadoop1
hadoop2
# rsync -az /home/hadoop/spark root@hadoop2:/home/hadoop/spark
#./sbin/star-all.sh


在hadoop1/hadoop2上执行:# jps

测试: http://192.168.43.100:8080

也可以在hadoop0上执行:spark-shell
#cd /home/hadoop/spark/spark-1.6.0-bin-hadoop2.6
#./bin/star-all.shll
安装成功,如下

| 主机名 | IP | 安装的软件 |
| Hadoop0 | 192.168.43.100 | jdk、hadoop、hbase、hive、scala、spark |
| Hadoop1 | 192.168.43.101 | jdk、hadoop、hbase、scala、spark |
| Hadoop2 | 192.168.43.102 | jdk、hadoop、hbase、scala、spark |
一. 准备环境
1.0下载Vmware并安装
官网地址:http://www.vmware.com/products/workstation/workstation-evaluation2.0安装linux虚拟机
大概步骤是:文件〉新建虚拟机〉自定义 ,下一步〉下一步(在安装的过程中注册个hadoop用户,密码也为hadoop)
注意:后面所有操作我都是以root用户权限进行的,实验环境下这样方便操作
2.1修改主机名
#vim /etc/sysconfig/networkNETWORKING=yes
HOSTNAME=hadoop0
2.2修改IP
(试验环境下我通过手机开一个热点,然后电脑通过无线连上手机,然后就可以将虚拟机网络改为桥接方式,这样所有虚拟机就可以组成一个局域网络了,而且可以自动获取地址,若是校园网桥接不可以…….)进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:x.x.x.x 子网掩码:x.x.x.x 网关:x.x.x.x -> apply
2.3 修改hosts
#vim /etc/hosts192.168.43.100 hadoop0
192.168.43.101 hadoop1
192.168.43.102 hadoop2
2.4关闭防火墙
#service iptables stop关闭防火墙开机启动
#chkconfig iptables off
2.5创建解压目录
#mkdir /hoame/hadoop/{java,hp,hbase,hive,scala,spark}2.6 上传文件
我的做法:先在windows上装上Xshell5然后打开Xshell 远程连上linux虚拟机hadoop0上

依次点击:窗口>传输新建文件>取消>一次性接受。
连上后输入put 回车后即可上传文件

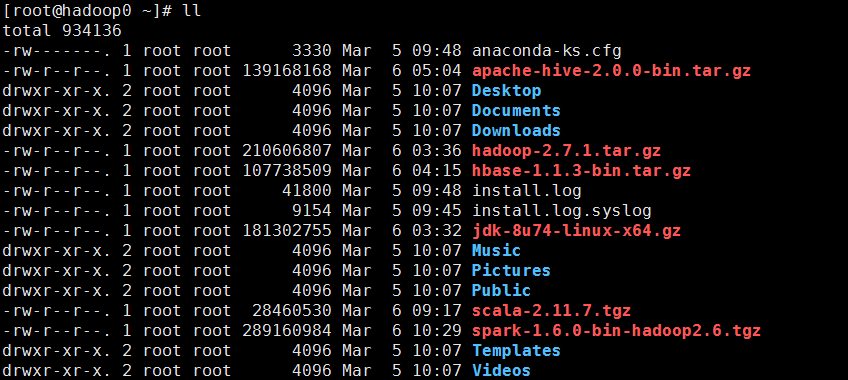
红色标记即为要上传的
2.7配置免密码登陆
# ssh-keygen -t rsa(四个回车)将公钥拷贝到要免登陆的机器上
# ssh-copy-id -i localhost
测试是否还需要密码?
#ssh localhost
二.安装hadoop
1.0安装JDK
解压# tar -zxvf jdk-8u74-linux-x64.gz -C /home/hadoop/java/
将java添加到环境变量中
#vim /etc/profile
在文件最后添加
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
export PATH=$PATH:$JAVA_HOME/bin
保存退出后,刷新配置
#source /etc/profile
像下图 就OK了

2.0解压hadoop
# tar -zxvf hadoop-2.7.1.tar.gz -C /home/hadoop/hp/2.1修改hadoop的配置
(照此安装配置文件所在目录:/home/hadoop/hp/hadoop-2.7.1/etc/hadoop/ )第一个:hadoop-env.sh
#vim hadoop-env.sh

第二个:core-site.xml
#vim core-site.xml
<configuration>
<property>
<!—指定NameNode的地址 -->
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hp/hadoop-2.7.1/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
第四个:mapred-site.xml
此文件默认没有,可将所给模版复制一份
#cp mapred-site.xml.template mapred-site.xml
#vim mapred-site.xml
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<!—设置reduce获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第六个:slaves
# vim slaves
hadoop1
hadoop2
2.2将hadoop添加到环境变量
# vim /etc/proflieexport HADOOP_HOME=/home/hadoop/hp/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#source /etc/profile
2.3克隆hadoop0
将hadoop0克隆两份,并将主机名改为hadoop1(ip配置为192.168.43.101)和hadoop2(IP配置为192.168.43.102),测试相互之间一定要能ping通,而且hadoop0可以不需要密码ssh上hadoop1和hadoop2。2.4格式化namenode(在hadoop0上执行)
#hdfs namenode -format 或#hadoop namenode –format(第一次运行hadoop集群时执行)2.5启动hadoop
#cd /home/hadoop/hp/hadoop-2.7.1/sbin
#./start-all.sh (已不推荐)
或者:
先启动HDFS
#./start-dfs.sh
再启动YARN
#./start-yarn.sh
3.0验证是否启动成功
使用jps命令验证
http://192.168.8.118:50070 (HDFS管理界面)

http://192.168.8.118:8088 (MR管理界面)
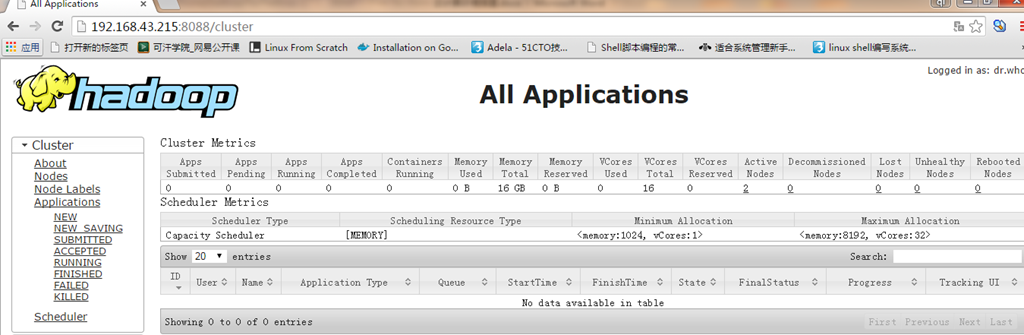
注意:haoop2.X已经没有50030,新的yarn架构默认是8088,也没有tasktracker 与jobtracker 进程了,为什么?请看这里http://www.aboutyun.com/thread-7678-1-1.html
补充:若要将SecondaryNameNode放在其它节点启动,如在hadoop1上,配置如下:
# vim masters(此文件hadoop2.7默认不存在)
Hadoop1
#vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop0:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
</configuration>
然后在hadoop0执行:# rsync -az /home/hadoop/ root@hadoop1:/home/hadoop/
#rsync -az /home/hadoop/ root@hadoop2:/home/hadoop/
4.0总结
hadoop安装简单来说就是: 配ssh、配JAVA_HOME 和HADOOP_HOME等profile参数、配数据存放目录 及 mapreduce运行在yarn上, 指出 namenode , master是谁,slaves是谁。排错:启动和关闭hadoop 时都会有如下警告

如何解决请参考http://f.dataguru.cn/thread-376971-1-1.html
三.安装hbase
1.0.解压
# tar hbase-1.1.3-bin.tar.gz -C /home/hadoop/hbase/添加环境变量
#vim /etc/profile
export HBASE_HOME=/home/hadoop/hbase/hbase-1.1.3
export PATH=$PATH:$HBASE_HOME/bin
刷新
#source /etc/profile
2.0.配置hbase集群 要修改3个文件
#cd /home/hadoop/hbase/hbase-1.1.3
2.1修改hbase-env.sh
#vim conf/hbase-env.shexport JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
//告诉hbase,hadoop 的配置文件路径
export HBASE_CLASSPATH=/home/hadoop/hp/hadoop-2.7.1/etc/hadoop
//告诉hbase使用默认自带的 Zookeeper
export HBASE_MANAGES_ZK=true
2.2修改hbase-site.xml
#vim conf/hbase-site.xml<configuration>
<property>
<name>hbase.master</name>
<value>hadoop0:60000</value>
</property>
<property>
<!-- 指定hbase在HDFS上存储的路径 -->
<name>hbase.rootdir</name>
<value>hdfs://hadoop0:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop0:2181,hadoop1:2181,hadoop2:2181</value>
</property>
</configuration>
2.3配置 regionservers
#vim regionservershadoop1
hadoop2
3.0启动hbase
在hadoop0上执行:# start-hbase.sh
访问HBase的master web页面: http://192.168.43.100:16010

访问HBase的regionserver web页面: http://192.168.43.102:16030
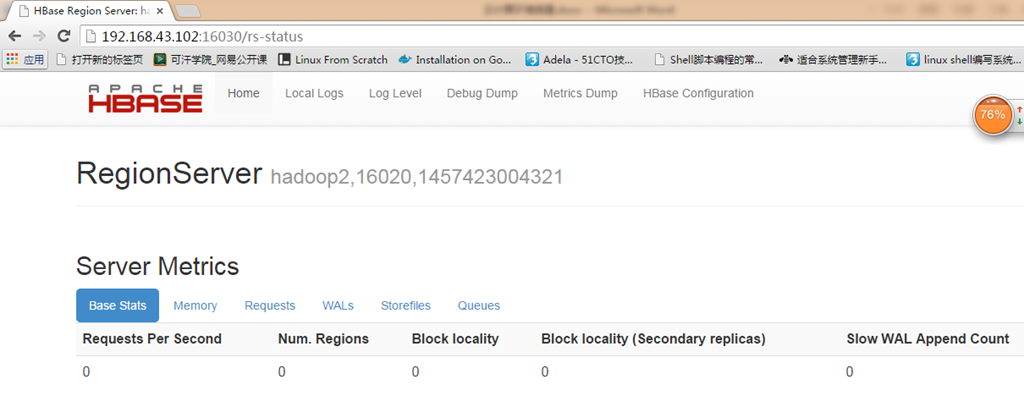
若要进入hbase的shell终端,执行:# hbase shell

在hadoop1/hadoop2上查看:# jps
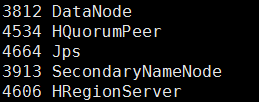
关闭hbase,在hadoop0上执行:# stop-hbase.sh
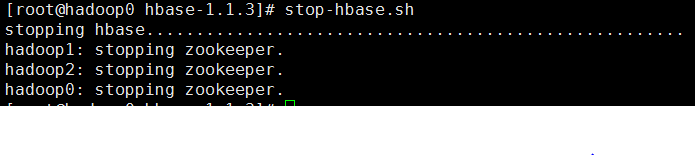
排错:如果没有HMaster,说明与hadoop的连接有问题,如果没有HRegionServer有可能是集群时间不同步
四.安装hive
1.0解压
# tar apache-hive-2.0.0-bin.tar.gz -C /home/hadoop/hive/2.0.配置hive环境变量,初始化hive在hdfs上的工作目录
# vim /etc/profile
export HIVE_HOME= /home/hadoop/hive/apache-hive-2.0.0-bin
export PATH = $HIVE_HOME/bin:$PATH
# source /etc/profile 使修改的环境变量立即生效
初始化hadoop 环境变量
#hadoop fs -mkdir /tmp
#hadoop fs –mkdir -p /usr/hive/warehouse
#hadoop fs -chmod g+w /tmp
#hadoop fs -chmod g+w /usr/hive/warehouse
配置hive相关的配置文件:/home/hadoop/hive/apache-hive-2.0.0-bin/conf/目录下
#cp hive-env.sh.template hive-env.sh
#cp hive-default.xml.template hive-site.xml
#cp hive-log4j2.properties.template hive-log4j2.properties
#cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
运行hive:
#cd /home/hadoop/hive/apache-hive-2.0.0-bin
#./bin/hive
默认将会进入hive的控制台
执行:# show tables; //如果不出错,则表明默认版本的hive安装成功
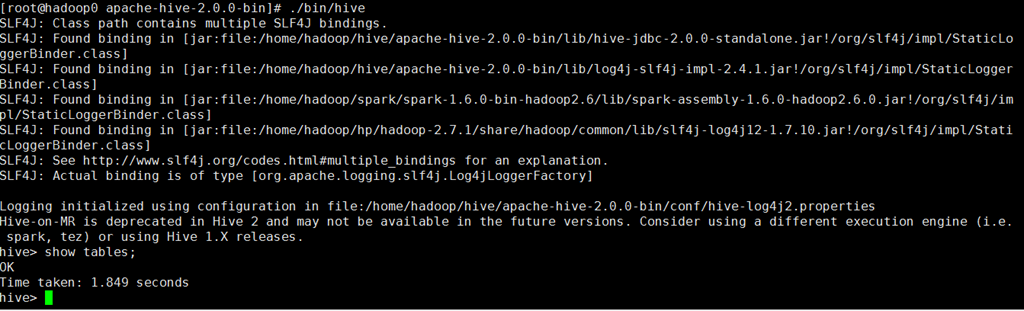
此时再打开一个终端执行:# jps
此种为默认配置,hive的metastore保存在一个叫derby的数据库的,该
数据库是一个嵌入式数据库,如果同时有两个人或者多个人操作,就会报错。
排错:运行hive时报错如下
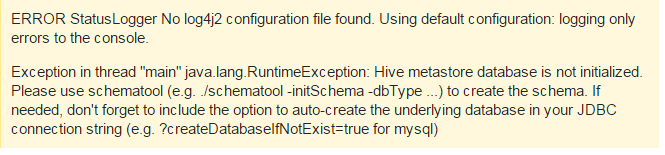
按提示执行:# schematool -dbType derby -initSchema
又报如下错:

执行:# rm -rf $HIVE_HOME/metastore_db
重新执行# $HIVE_HOME/bin/schematool -initSchema -dbType derby
这样问题解决了…………….
当报如下错时:
# mkdir /home/hadoop/hive/apache-hive-2.0.0-bin/iotmp
#vim /home/hadoop/hive/apache-hive-2.0.0-bin/conf/hive-site.xml
再次启动hive就好了。
五.安装spark
1.0解压scala
#tar scala-2.11.7.tgz -C /home/hadoop/scala/1.1 配置环境变量
#vim /etc/profileexport SCALA_HOME=/home/hadoop/scala/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin
#source /etc/profile
1.2 验证scala

2.0解压spark
#tar spark-1.6.0-bin-hadoop2.6.tgz -C /home/hadoop/spark/2.1 配置环境变量
#vim /etc/profileexport SPARK_HOME=/home/hadoop/spark/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:$ SPARK_HOME/bin
2.2修改配置文件(# cd /home/hadoop/spark/spark-1.6.0-bin-hadoop2.6/conf)
# cp spark-env.sh.template spark-env.sh
#vim spark-env.sh
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
export SCALA_HOME=/home/hadoop/scala/scala-2.11.7
export SPARK_MASTER_IP=192.168.43.100
export SPARK_WORKER_MEMORY=512M
export HADOOP_CONF_DIR=/home/hadoop/hp/hadoop-2.7.1/etc/hadoop
# cp slaves.template slaves
#vim slaves
hadoop1
hadoop2
2.3同步到其它节点
# rsync -az /home/hadoop/scala root@hadoop2:/home/hadoop/scala# rsync -az /home/hadoop/spark root@hadoop2:/home/hadoop/spark
3.0启动spark
#cd /home/hadoop/spark/spark-1.6.0-bin-hadoop2.6#./sbin/star-all.sh


在hadoop1/hadoop2上执行:# jps

测试: http://192.168.43.100:8080

也可以在hadoop0上执行:spark-shell
#cd /home/hadoop/spark/spark-1.6.0-bin-hadoop2.6
#./bin/star-all.shll
安装成功,如下

4.0总结
SPARK安装就是:配scala,SPARK_MASTER_IP ,HADOOP_CONF_DIR ,slaves
相关文章推荐
- Linux系统快速入门
- Linux 学习日记 2: 目录结构和文件操作
- Linux常见问题及命令总结
- 阿里云使用笔记-SVN安装与部署-centos7
- 阿里云使用笔记-Lrzsz上传下载文件-centos7
- CentOS6.5 安装vsftpd
- Linux常用命令
- Linux下批量杀掉 包含某个关键字的 程序进程
- 更改CentOS yum 源为163的源
- Centos搭建SVN服务器三步曲
- CentOS下忘记mysql密码的解决办法
- Linux后台进程管理
- 查看linux服务器硬盘IO读写负载
- centos7将网卡加入到网桥后, Missing config file br-ex,网卡无法正常启动问题解决
- vmware centos7 clone mac地址导致 Failed to start LSB: Bring up/down networking.
- CentOS 7.0,启用iptables防火墙(转)
- centos 7.0 网卡配置及重命名教程(转)
- CentOS 7最小化安装后找不到‘ifconfig’命令——修复小提示(转)
- 如何在CentOS 7上修改主机名hostname
- 关于centos重启network没有默认路由,问题分析