召回率和准确率
2016-03-08 21:40
246 查看
召回率和精度示意图
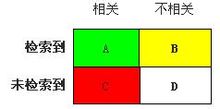
假定:从一个大规模数据集合中检索文档的时,可把文档分成四组:
- 系统检索到的相关文档(A)
系统检索到的不相关文档(B)
相关但是系统没有检索到的文档(C)
不相关且没有被系统检索到的文档(D)
则:
召回率R:用检索到相关文档数作为分子,所有相关文档总数作为分母,即R = A / ( A + C )
精度P:用检索到相关文档数作为分子,所有检索到的文档总数作为分母.即P = A / ( A + B ).
举例来说:
一个数据库有500个文档,其中有50个文档符合定义的问题。系统检索到75个文档,但是只有45个符合定义的问题。
召回率R=45/50=90%
精度P=45/75=60%
本例中,系统检索是比较有效的,召回率为90%。但是结果有很大的噪音,有近一半的检索结果是不相关。研究表明:在不牺牲精度的情况下,获得一个高召回率是很困难的
假定:从一个大规模数据集合中检索文档的时,可把文档分成四组:
- 系统检索到的相关文档(A)
系统检索到的不相关文档(B)
相关但是系统没有检索到的文档(C)
不相关且没有被系统检索到的文档(D)
则:
召回率R:用检索到相关文档数作为分子,所有相关文档总数作为分母,即R = A / ( A + C )
精度P:用检索到相关文档数作为分子,所有检索到的文档总数作为分母.即P = A / ( A + B ).
举例来说:
一个数据库有500个文档,其中有50个文档符合定义的问题。系统检索到75个文档,但是只有45个符合定义的问题。
召回率R=45/50=90%
精度P=45/75=60%
本例中,系统检索是比较有效的,召回率为90%。但是结果有很大的噪音,有近一半的检索结果是不相关。研究表明:在不牺牲精度的情况下,获得一个高召回率是很困难的

相关文章推荐
- OSX 的文件系统终端命令
- 字符流小说 分页功能!
- arp命令
- windows+ubuntu引导修复
- arm9的中断
- Docker入门教程(九)10个镜像相关的API
- Linux-github 搭建静态博客
- UITextView 文本垂直居中
- 全注解整合ssh
- Android studio 导入xutils3报错
- 单词数 (HDU_2072) 字典树
- 用户首选项
- Hdu 5016 Baby Ming and Matrix games【dfs】
- 备份oracle数据脚本
- 深入理解CSS
- RM2016视觉开源OpenCv2代码
- Android:分页下载示例(PullToRefresh)
- MMU与cache
- 从NavigationController 下的UITableView中移除 header
- 稀疏矩阵的压缩存储及其两种转置算法