Oracle中"行转列"的实现方式
2016-03-07 09:02
771 查看
在报表的开发当中,难免会遇到行转列的问题。
以Oracle中scott的emp为例,统计各职位的人员在各部门的人数分布情况,就可以用"行转列":
scott的emp的原始数据为:
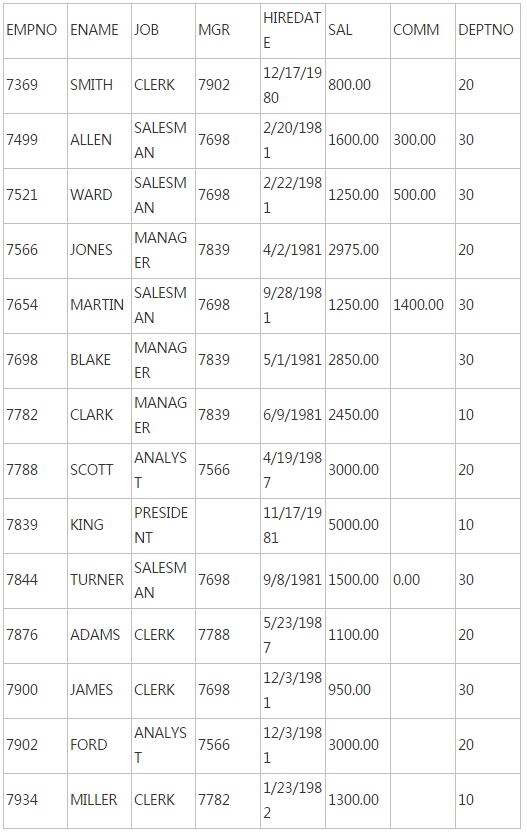
使用 "行转列" 统计各职位的人员在各部门的分布人数后,数据为:

一、经典的实现方式
主要是利用decode函数、聚合函数(如max、sum等)、group by分组实现的
二、PIVOT
Oracle 11g后,出现PIVOT,更简便地实现“行转列”。使用前,需确定数据库环境大于11g,最好也确认下生产环境的数据库是否大于11g,避免项目后期出现状况。
三、PIVOT XML
使用经典的方法和PIVOT方法,DEPTNO的参数是硬编码的。而通过PIVOT XML能解决这一问题,使分列条件可以是动态的。但,输出的是XML的CLOB的格式。目前,Java读取PIVOT XML CLOB貌似比较困难(本人没有成功读取,可见下文描述,如有知晓者,请知悉)。
本文转自:http://www.cnblogs.com/nick-huang/p/3836061.html
以Oracle中scott的emp为例,统计各职位的人员在各部门的人数分布情况,就可以用"行转列":
scott的emp的原始数据为:
使用 "行转列" 统计各职位的人员在各部门的分布人数后,数据为:
一、经典的实现方式
主要是利用decode函数、聚合函数(如max、sum等)、group by分组实现的
select t.job, count(decode(t.deptno, '10', 1)) as "10(DEPTNO)", count(decode(t.deptno, '20', 1)) as "20(DEPTNO)", count(decode(t.deptno, '30', 1)) as "30(DEPTNO)", count(decode(t.deptno, '40', 1)) as "40(DEPTNO)" from scott.emp t group by t.job;
二、PIVOT
Oracle 11g后,出现PIVOT,更简便地实现“行转列”。使用前,需确定数据库环境大于11g,最好也确认下生产环境的数据库是否大于11g,避免项目后期出现状况。
with tmp_tab as( select t.job, t.deptno from scott.emp t ) select * from tmp_tab t pivot(count(1) for deptno in (10, 20, 30, 40));
三、PIVOT XML
使用经典的方法和PIVOT方法,DEPTNO的参数是硬编码的。而通过PIVOT XML能解决这一问题,使分列条件可以是动态的。但,输出的是XML的CLOB的格式。目前,Java读取PIVOT XML CLOB貌似比较困难(本人没有成功读取,可见下文描述,如有知晓者,请知悉)。
with tmp_tab as( select t.job, t.deptno from scott.emp t ) select * from tmp_tab t pivot xml (count(1) for deptno in (select deptno from scott.dept));
本文转自:http://www.cnblogs.com/nick-huang/p/3836061.html

相关文章推荐
- Oracle SQL性能优化
- ORACLE 块参数设置
- oracle链接查询
- Oracle 使用MERGE INTO 语句更新数据
- Oracle学习之shared pool的组成
- Oracle学习之sql语句执行过程分析
- Oracle学习之oracle的启动停止
- oracle常用管理命令
- 在debian上安装和配置Oracle JAVA 8(JDK/JRE)方法
- oracle日期计算
- Centos-6.7下_Oracle 11gR2"静默"详细安装过程及排错
- ORA-3136 datagurad
- oracle自学笔记
- 【C类】Oracle 各类课程集
- asp.net及IIS使用Oracle.DataAccess连接Oracle11g总结
- oracle数据库大小文件最大值的计算方式
- ORACLE RAC(11203)环境将误建立在本地目录的文件转移到ASM存储中
- Oracle Application Testing Suite 12.5.0.2Sample MedRec无法访问问题
- 在本地将sql文件导入oracle数据库中文出现乱码
- centos7.0下安装oracle11g