Hadoop的技术堆栈(hadoop technology stack)
2016-03-01 00:29
204 查看
概述
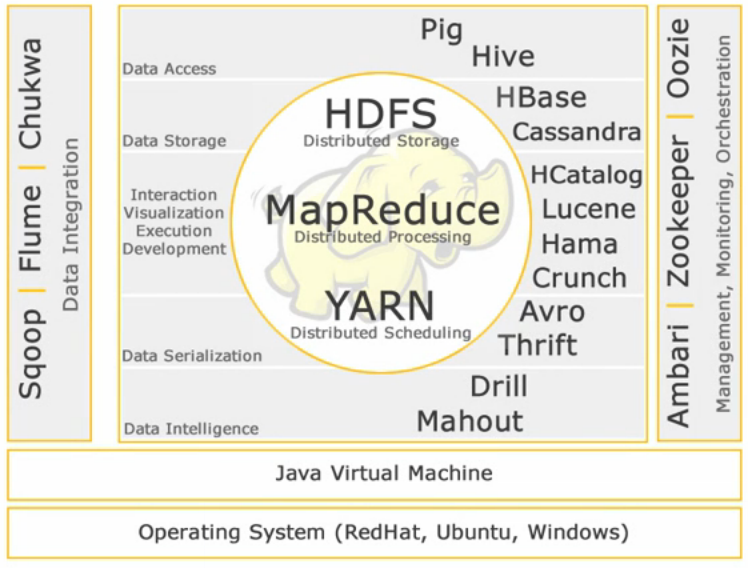
技术架构
Hadoop的核心
HDFS分布式存储
MapReduce分布式处理
YARN分布式调度
数据访问Data Access
Pig
Hive
数据存储Data Storage
HBase
Cassandra
数据序列化Data Serialization
Avro
Thrift
数据智能Data Intelligence
Drill
Mahout
Hadoop孵化器Hadoop incubator
Chukwa
Ambari
HDT
HCatalog
Knox
Spark
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
YARN最初是为了修复MapReduce实现里的明显不足,并对可伸缩性(支持一万个节点和二十万个内核的集群)、可靠性和集群利用率进行了提升。YARN实现这些需求的方式是,把Job Tracker的两个主要功能(资源管理和作业调度/监控)分成了两个独立的服务程序——全局的资源管理(RM)和针对每个应用的应用 Master(AM),这里说的应用要么是传统意义上的MapReduce任务,要么是任务的有向无环图(DAG)。
YARN从某种那个意义上来说应该算做是一个云操作系统,它负责集群的资源管理。在操作系统之上可以开发各类的应用程序,例如批处理MapReduce、流式作业Storm以及实时型服务Storm等。这些应用可以同时利用Hadoop集群的计算能力和丰富的数据存储模型,共享同一个Hadoop 集群和驻留在集群上的数据。此外,这些新的框架还可以利用YARN的资源管理器,提供新的应用管理器实现。
用MapReduce进行数据分析。当业务比较复杂的时候,使用MapReduce将会是一个很复杂的事情,比如你需要对数据进行很多预处理或转换,以便能够适应MapReduce的处理模式。另一方面,编写MapReduce程序,发布及运行作业都将是一个比较耗时的事情。Pig的出现很好的弥补了这一不足。Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。本质是上来说,当你使用Pig进行处理时,Pig本身会在后台生成一系列的MapReduce操作来执行任务,但是这个过程对用户来说是透明的。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynamo (分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型)。Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
技术架构
Hadoop的核心
HDFS分布式存储
MapReduce分布式处理
YARN分布式调度
数据访问Data Access
Pig
Hive
数据存储Data Storage
HBase
Cassandra
数据序列化Data Serialization
Avro
Thrift
数据智能Data Intelligence
Drill
Mahout
Hadoop孵化器Hadoop incubator
Chukwa
Ambari
HDT
HCatalog
Knox
Spark
概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
技术架构
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Hadoop的核心
HDFS(分布式存储)
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
MapReduce(分布式处理)
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。YARN(分布式调度)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。YARN最初是为了修复MapReduce实现里的明显不足,并对可伸缩性(支持一万个节点和二十万个内核的集群)、可靠性和集群利用率进行了提升。YARN实现这些需求的方式是,把Job Tracker的两个主要功能(资源管理和作业调度/监控)分成了两个独立的服务程序——全局的资源管理(RM)和针对每个应用的应用 Master(AM),这里说的应用要么是传统意义上的MapReduce任务,要么是任务的有向无环图(DAG)。
YARN从某种那个意义上来说应该算做是一个云操作系统,它负责集群的资源管理。在操作系统之上可以开发各类的应用程序,例如批处理MapReduce、流式作业Storm以及实时型服务Storm等。这些应用可以同时利用Hadoop集群的计算能力和丰富的数据存储模型,共享同一个Hadoop 集群和驻留在集群上的数据。此外,这些新的框架还可以利用YARN的资源管理器,提供新的应用管理器实现。
数据访问(Data Access)
Pig
Apache Pig 是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。[1]用MapReduce进行数据分析。当业务比较复杂的时候,使用MapReduce将会是一个很复杂的事情,比如你需要对数据进行很多预处理或转换,以便能够适应MapReduce的处理模式。另一方面,编写MapReduce程序,发布及运行作业都将是一个比较耗时的事情。Pig的出现很好的弥补了这一不足。Pig能够让你专心于数据及业务本身,而不是纠结于数据的格式转换以及MapReduce程序的编写。本质是上来说,当你使用Pig进行处理时,Pig本身会在后台生成一系列的MapReduce操作来执行任务,但是这个过程对用户来说是透明的。
Hive
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
数据存储(Data Storage)
HBase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。Cassandra
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynamo (分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型)。Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
数据序列化(Data Serialization)
Avro
Thrift
数据智能(Data Intelligence)
Drill
Mahout
Hadoop孵化器(Hadoop incubator)
Chukwa
Ambari
HDT
HCatalog
Knox
Spark

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- java结合HADOOP集群文件上传下载
- 让python在hadoop上跑起来
- 用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
- Hadoop安装感悟