数据库事务
2016-02-23 14:21
232 查看
数据并发的问题
一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库。数据库中的相同数据可能同时被多个事务访问,如果没有采取必要的隔离措施,就会导致各种并发问题,破坏数据的完整性。这些问题可以归结为5类,包括3类数据读问题(脏读、幻象读和不可重复读)以及2类数据更新问题(第一类丢失更新和第二类丢失更新)。下面,我们分别通过实例讲解引发问题的场景。
脏读(dirty read)
在讲解脏读前,我们先讲一个笑话:一个有结巴的人在饮料店柜台前转悠,老板很热情地迎上来:“喝一瓶?”,结巴连忙说:“我…喝…喝…”,老板麻利地打开易拉罐递给结巴,结巴终于憋出了他的那句话:“我…喝…喝…喝不起啊!”。在这个笑话中,饮料店老板就对结巴进行了脏读。
A事务读取B事务尚未提交的更改数据,并在这个数据的基础上操作。如果恰巧B事务回滚,那么A事务读到的数据根本是不被承认的。来看取款事务和转账事务并发时引发的脏读场景:
在这个场景中,B希望取款500元而后又撤销了动作,而A往相同的账户中转账100元,就因为A事务读取了B事务尚未提交的数据,因而造成账户白白丢失了500元。
不可重复读(unrepeatable read)
不可重复读是指A事务读取了B事务已经提交的更改数据。假设A在取款事务的过程中,B往该账户转账100元,A两次读取账户的余额发生不一致:
在同一事务中,T4时间点和T7时间点读取账户存款余额不一样。
幻象读(phantom read)
A事务读取B事务提交的新增数据,这时A事务将出现幻象读的问题。幻象读一般发生在计算统计数据的事务中,举一个例子,假设银行系统在同一个事务中,两次统计存款账户的总金额,在两次统计过程中,刚好新增了一个存款账户,并存入100元,这时,两次统计的总金额将不一致:
如果新增数据刚好满足事务的查询条件,这个新数据就进入了事务的视野,因而产生了两个统计不一致的情况。
幻象读和不可重复读是两个容易混淆的概念,前者是指读到了其它已经提交事务的新增数据,而后者是指读到了已经提交事务的更改数据(更改或删除),为了避免这两种情况,采取的对策是不同的,防止读取到更改数据,只需要对操作的数据添加行级锁,阻止操作中的数据发生变化,而防止读取到新增数据,则往往需要添加表级锁——将整个表锁定,防止新增数据。
第一类丢失更新
A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
A事务在撤销时,“不小心”将B事务已经转入账户的金额给抹去了。
第二类丢失更新
A事务覆盖B事务已经提交的数据,造成B事务所做操作丢失:
数据库事务隔离级别与锁
关键字: 事务
一,事务的4个基本特征
Atomic(原子性):
事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要
么全部成功,要么全部失败。
Consistency(一致性):
只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初
状态。
Isolation(隔离性):
事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正
确性和完整性。同时,并行事务的修改必须与其他并行事务的修改
相互独立。
Durability(持久性):
事务结束后,事务处理的结果必须能够得到固化。
以上属于废话
二,为什么需要对事务并发控制
如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形
Lost update:
两个事务都同时更新一行数据,但是第二个事务却中途失败退出,
导致对数据的两个修改都失效了。
Dirty Reads:
一个事务开始读取了某行数据,但是另外一个事务已经更新了此数
据但没有能够及时提交。这是相当危险的,因为很可能所有的操作
都被回滚。
Non-repeatable Reads:
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。
Second lost updates problem:
无法重复读取的特例。有两个并发事务同时读取同一行数据,然后其
中一个对它进行修改提交,而另一个也进行了修改提交。这就会造成
第一次写操作失效。
Phantom Reads:
事务在操作过程中进行两次查询,第二次查询的结果包含了第一次查
询中未出现的数据(这里并不要求两次查询的SQL语句相同)。这是
因为在两次查询过程中有另外一个事务插入数据造成的。
三, 数据库的隔离级别
为了兼顾并发效率和异常控制,在标准SQL规范中,定义了4个事务隔
离级别,(ORACLE和SQLSERER对标准隔离级别有不同的实现)
Read Uncommitted:
直译就是"读未提交",意思就是即使一个更新语句没有提交,但是别
的事务可以读到这个改变.这是很不安全的.
Read Committed:
直译就是"读提交",意思就是语句提交以后即执行了COMMIT以后
别的事务就能读到这个改变.
Repeatable Read:
直译就是"可以重复读",这是说在同一个事务里面先后执行同一个
查询语句的时候,得到的结果是一样的.
Serializable:
直译就是"序列化",意思是说这个事务执行的时候不允许别的事务
并发执行.
四,隔离级别对并发的控制
下表是各隔离级别对各种异常的控制能力。
(注:LU:丢失更新;DR:脏读;NRR:非重复读;SLU:二类丢失更新;PR:幻像读)
顺便举一小例。
MS_SQL:
--事务一
set transaction isolation level serializable
begin tran
insert into test values('xxx')
--事务二
set transaction isolation level read committed
begin tran
select * from test
--事务三
set transaction isolation level read uncommitted
begin tran
select * from test
在查询分析器中执行事务一后,分别执行事务二,和三。结果是事务二会等待,而事务三则会执行。
ORACLE:
--事务一
set transaction isolation level serializable;
insert into test values('xxx');
select * from test;
--事务二
set transaction isolation level read committed--ORACLE默认级别
select * from test
执行事务一后,执行事务二。结果是事务二只读出原有的数据,无视事务一的插入操作。
读者是否发现MS_SQL和ORACLE对并发控制的处理有所不同呢?
五,锁
下表是锁的兼容或冲突情形。
现有 S U X
请求
S Y Y N
U Y N N
X N N N
oracle:
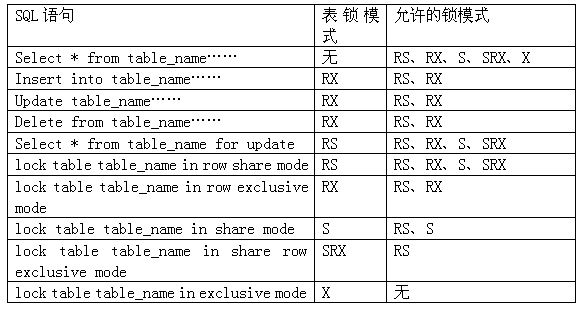
六,隔离级别与锁
七,注意点
一般处理并发问题时的步骤:
1、开启事务。
2、申请写权限,也就是给对象(表或记录)加锁。
3、假如失败,则结束事务,过一会重试。
4、假如成功,也就是给对象加锁成功,防止其他用户再用同样的方式打开。
5、进行编辑操作。
6、写入所进行的编辑结果。
7、假如写入成功,则提交事务,完成操作。
8、假如写入失败,则回滚事务,取消提交。
9、(7.8)两步操作已释放了锁定的对象,恢复到操作前的状态。
对多表的操作最好一起取得锁,或则保证处理顺序;个人感觉还是前者好,虽然效率低一些
八,附
查看锁
ORACLE:
selectobject_name,session_id,os_user_name,oracle_username,process,locked_mode,status
from v$locked_object l, all_objects a
where l.object_id=a.object_id;
MS_SQL:EXEC SP_LOCK
事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
针对上面的描述可以看出,事务的提出主要是为了解决并发情况下保持数据一致性的问题。
事务具有以下4个基本特征。
● Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
● Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
● Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
● Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
2.事务的语句
开始事物:BEGIN TRANSACTION
提交事物:COMMIT TRANSACTION
回滚事务:ROLLBACK TRANSACTION
3.事务的4个属性
①原子性(Atomicity):事务中的所有元素作为一个整体提交或回滚,事务的个元素是不可分的,事务是一个完整操作。
②一致性(Consistemcy):事物完成时,数据必须是一致的,也就是说,和事物开始之前,数据存储中的数据处于一致状态。保证数据的无损。
③隔离性(Isolation):对数据进行修改的多个事务是彼此隔离的。这表明事务必须是独立的,不应该以任何方式以来于或影响其他事务。
④持久性(Durability):事务完成之后,它对于系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库
4.事务的保存点
SAVE TRANSACTION 保存点名称 --自定义保存点的名称和位置
ROLLBACK TRANSACTION 保存点名称 --回滚到自定义的保存点
其他高手的一些补充:
事务的标准定义: 指作为单个逻辑工作单元执行的一系列操作,而这些逻辑工作单元需要具有原子性, 一致性,隔离性和持久性四个属性,统称为ACID特性。
所谓事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。例如,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。
事务和程序是两个概念。一般地讲,一个程序中包含多个事务。
事务的开始与结束可以由用户显式控制。如果用户没有显式地定义事务,则由DBMS按缺省规定自动划分事
务。在SQL语言中,定义事务的语句有三条:
BEGIN TRANSACTION
COMMIT
ROLLBACK
同生共死。。
显示事务被用begin transaction 与 end transaction 标识起来,其中的 update 与delete 语句或者全部执行或者全部不执行。。如:
begin transaction T1
update student
set name='Tank'
where id=2006010
delete from student
where id=2006011
commit
简单地说,事务是一种机制,用以维护数据库的完整性。
其实现形式就是将普通的SQL语句嵌入到Begin Tran...Commit Tran 中(或完整形式 BeginTransaction...Commit Transaction),当然,必要时还可以使用RollBack Tran 回滚事务,即撤销操作。
利用事务机制,对数据库的操作要么全部执行,要么全部不执行,保证数据库的一致性。需要使用事务的SQL语句通常是更新和删除操作等。
end transaction T1
关于savepoint
用户在事务(transaction)内可以声明(declare)被称为保存点(savepoint)
的标记。保存点将一个大事务划分为较小的片断。
用户可以使用保存点(savepoint)在事务(transaction)内的任意位置作标
记。之后用户在对事务进行回滚操作(rolling back)时,就可以选择从当前
执行位置回滚到事务内的任意一个保存点。例如用户可以在一系列复杂的更
新(update)操作之间插入保存点,如果执行过程中一个语句出现错误,用
户 可以回滚到错误之前的某个保存点,而不必重新提交所有的语句。
在开发应用程序时也同样可以使用保存点(savepoint)。如果一个过程
(procedure)内包含多个函数(function),用户可以在每个函数的开始位置
创建一个保存点。当一个函数失败时,就很容易将数据恢复到函数执行之前
的状态,回滚(roll back)后可以修改参数重新调用函数,或执行相关的错误
处理。
当事务(transaction)被回滚(rollback)到某个保存点(savepoint)后,
Oracle将释放由被回滚语句使用的锁。其他等待被锁资源的事务就可以继续
执行。需要更新(update)被锁数据行的事务也可以继续执行。
将事务(transaction)回滚(roll back)到某个保存点(savepoint)的过程如
下:
1. Oracle 回滚指定保存点之后的语句
2. Oracle 保留指定的保存点,但其后创建的保存点都将被清除
3. Oracle 释放此保存点后获得的表级锁(table lock)与行级锁(row
lock),但之前的数据锁依然保留。
被部分回滚的事务(transaction)依然处于活动状态,可以继续执行。
一个事务(transaction)在等待其他事务的过程中,进行回滚(roll back)到
某个保存点(savepoint)的操作不会释放行级锁(row lock)。为了避免事务
因为不能获得锁而被挂起,应在执行 UPDATE 或 DELETE 操作前使用 FOR
UPDATE ... NOWAIT 语句。(以上内容讲述的是回滚保存点之前所获得的
锁。而在保存点之后获得的行级锁是会被释放的,同时保存点之后执行的
SQL 语句也会被完全回滚)。
一个数据库可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库。数据库中的相同数据可能同时被多个事务访问,如果没有采取必要的隔离措施,就会导致各种并发问题,破坏数据的完整性。这些问题可以归结为5类,包括3类数据读问题(脏读、幻象读和不可重复读)以及2类数据更新问题(第一类丢失更新和第二类丢失更新)。下面,我们分别通过实例讲解引发问题的场景。
脏读(dirty read)
在讲解脏读前,我们先讲一个笑话:一个有结巴的人在饮料店柜台前转悠,老板很热情地迎上来:“喝一瓶?”,结巴连忙说:“我…喝…喝…”,老板麻利地打开易拉罐递给结巴,结巴终于憋出了他的那句话:“我…喝…喝…喝不起啊!”。在这个笑话中,饮料店老板就对结巴进行了脏读。
A事务读取B事务尚未提交的更改数据,并在这个数据的基础上操作。如果恰巧B事务回滚,那么A事务读到的数据根本是不被承认的。来看取款事务和转账事务并发时引发的脏读场景:
| 时间 | 转账事务A | 取款事务B |
| T1 | | 开始事务 |
| T2 | 开始事务 | |
| T3 | | 查询账户余额为1000元 |
| T4 | | 取出500元把余额改为500元 |
| T5 | 查询账户余额为500元(脏读) | |
| T6 | | 撤销事务余额恢复为1000元 |
| T7 | 汇入100元把余额改为600元 | |
| T8 | 提交事务 | |
不可重复读(unrepeatable read)
不可重复读是指A事务读取了B事务已经提交的更改数据。假设A在取款事务的过程中,B往该账户转账100元,A两次读取账户的余额发生不一致:
| 时间 | 取款事务A | 转账事务B |
| T1 | | 开始事务 |
| T2 | 开始事务 | |
| T3 | | 查询账户余额为1000元 |
| T4 | 查询账户余额为1000元 | |
| T5 | | 取出100元把余额改为900元 |
| T6 | | 提交事务 |
| T7 | 查询账户余额为900元(和T4读取的不一致) | |
幻象读(phantom read)
A事务读取B事务提交的新增数据,这时A事务将出现幻象读的问题。幻象读一般发生在计算统计数据的事务中,举一个例子,假设银行系统在同一个事务中,两次统计存款账户的总金额,在两次统计过程中,刚好新增了一个存款账户,并存入100元,这时,两次统计的总金额将不一致:
| 时间 | 统计金额事务A | 转账事务B |
| T1 | | 开始事务 |
| T2 | 开始事务 | |
| T3 | 统计总存款数为10000元 | |
| T4 | | 新增一个存款账户,存款为100元 |
| T5 | | 提交事务 |
| T6 | 再次统计总存款数为10100元(幻象读) | |
幻象读和不可重复读是两个容易混淆的概念,前者是指读到了其它已经提交事务的新增数据,而后者是指读到了已经提交事务的更改数据(更改或删除),为了避免这两种情况,采取的对策是不同的,防止读取到更改数据,只需要对操作的数据添加行级锁,阻止操作中的数据发生变化,而防止读取到新增数据,则往往需要添加表级锁——将整个表锁定,防止新增数据。
第一类丢失更新
A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
| 时间 | 取款事务A | 转账事务B |
| T1 | 开始事务 | |
| T2 | | 开始事务 |
| T3 | 查询账户余额为1000元 | |
| T4 | | 查询账户余额为1000元 |
| T5 | | 汇入100元把余额改为1100元 |
| T6 | | 提交事务 |
| T7 | 取出100元把余额改为900元 | |
| T8 | 撤销事务 | |
| T9 | 余额恢复为1000元(丢失更新) | |
第二类丢失更新
A事务覆盖B事务已经提交的数据,造成B事务所做操作丢失:
| 时间 | 转账事务A | 取款事务B |
| T1 | | 开始事务 |
| T2 | 开始事务 | |
| T3 | | 查询账户余额为1000元 |
| T4 | 查询账户余额为1000元 | |
| T5 | | 取出100元把余额改为900元 |
| T6 | | 提交事务 |
| T7 | 汇入100元 | |
| T8 | 提交事务 | |
| T9 | 把余额改为1100元(丢失更新) | |
数据库事务隔离级别与锁
关键字: 事务
一,事务的4个基本特征
Atomic(原子性):
事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要
么全部成功,要么全部失败。
Consistency(一致性):
只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初
状态。
Isolation(隔离性):
事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正
确性和完整性。同时,并行事务的修改必须与其他并行事务的修改
相互独立。
Durability(持久性):
事务结束后,事务处理的结果必须能够得到固化。
以上属于废话
二,为什么需要对事务并发控制
如果不对事务进行并发控制,我们看看数据库并发操作是会有那些异常情形
Lost update:
两个事务都同时更新一行数据,但是第二个事务却中途失败退出,
导致对数据的两个修改都失效了。
Dirty Reads:
一个事务开始读取了某行数据,但是另外一个事务已经更新了此数
据但没有能够及时提交。这是相当危险的,因为很可能所有的操作
都被回滚。
Non-repeatable Reads:
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。
Second lost updates problem:
无法重复读取的特例。有两个并发事务同时读取同一行数据,然后其
中一个对它进行修改提交,而另一个也进行了修改提交。这就会造成
第一次写操作失效。
Phantom Reads:
事务在操作过程中进行两次查询,第二次查询的结果包含了第一次查
询中未出现的数据(这里并不要求两次查询的SQL语句相同)。这是
因为在两次查询过程中有另外一个事务插入数据造成的。
三, 数据库的隔离级别
为了兼顾并发效率和异常控制,在标准SQL规范中,定义了4个事务隔
离级别,(ORACLE和SQLSERER对标准隔离级别有不同的实现)
Read Uncommitted:
直译就是"读未提交",意思就是即使一个更新语句没有提交,但是别
的事务可以读到这个改变.这是很不安全的.
Read Committed:
直译就是"读提交",意思就是语句提交以后即执行了COMMIT以后
别的事务就能读到这个改变.
Repeatable Read:
直译就是"可以重复读",这是说在同一个事务里面先后执行同一个
查询语句的时候,得到的结果是一样的.
Serializable:
直译就是"序列化",意思是说这个事务执行的时候不允许别的事务
并发执行.
四,隔离级别对并发的控制
下表是各隔离级别对各种异常的控制能力。
| LU | DR | NRR | SLU | PR | |
| RU | Y | Y | Y | Y | Y |
| RC | N | N | Y | Y | Y |
| RR | N | N | N | N | Y |
| S | N | N | N | N | N |
顺便举一小例。
MS_SQL:
--事务一
set transaction isolation level serializable
begin tran
insert into test values('xxx')
--事务二
set transaction isolation level read committed
begin tran
select * from test
--事务三
set transaction isolation level read uncommitted
begin tran
select * from test
在查询分析器中执行事务一后,分别执行事务二,和三。结果是事务二会等待,而事务三则会执行。
ORACLE:
--事务一
set transaction isolation level serializable;
insert into test values('xxx');
select * from test;
--事务二
set transaction isolation level read committed--ORACLE默认级别
select * from test
执行事务一后,执行事务二。结果是事务二只读出原有的数据,无视事务一的插入操作。
读者是否发现MS_SQL和ORACLE对并发控制的处理有所不同呢?
五,锁
下表是锁的兼容或冲突情形。
现有 S U X
请求
S Y Y N
U Y N N
X N N N
| 现有 | S | U | X |
| 申请 | |||
| S | Y | Y | N |
| U | Y | N | N |
| X | N | N | N |
oracle:
六,隔离级别与锁
七,注意点
一般处理并发问题时的步骤:
1、开启事务。
2、申请写权限,也就是给对象(表或记录)加锁。
3、假如失败,则结束事务,过一会重试。
4、假如成功,也就是给对象加锁成功,防止其他用户再用同样的方式打开。
5、进行编辑操作。
6、写入所进行的编辑结果。
7、假如写入成功,则提交事务,完成操作。
8、假如写入失败,则回滚事务,取消提交。
9、(7.8)两步操作已释放了锁定的对象,恢复到操作前的状态。
对多表的操作最好一起取得锁,或则保证处理顺序;个人感觉还是前者好,虽然效率低一些
八,附
查看锁
ORACLE:
selectobject_name,session_id,os_user_name,oracle_username,process,locked_mode,status
from v$locked_object l, all_objects a
where l.object_id=a.object_id;
MS_SQL:EXEC SP_LOCK
事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
针对上面的描述可以看出,事务的提出主要是为了解决并发情况下保持数据一致性的问题。
事务具有以下4个基本特征。
● Atomic(原子性):事务中包含的操作被看做一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
● Consistency(一致性):只有合法的数据可以被写入数据库,否则事务应该将其回滚到最初状态。
● Isolation(隔离性):事务允许多个用户对同一个数据进行并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。
● Durability(持久性):事务结束后,事务处理的结果必须能够得到固化。
2.事务的语句
开始事物:BEGIN TRANSACTION
提交事物:COMMIT TRANSACTION
回滚事务:ROLLBACK TRANSACTION
3.事务的4个属性
①原子性(Atomicity):事务中的所有元素作为一个整体提交或回滚,事务的个元素是不可分的,事务是一个完整操作。
②一致性(Consistemcy):事物完成时,数据必须是一致的,也就是说,和事物开始之前,数据存储中的数据处于一致状态。保证数据的无损。
③隔离性(Isolation):对数据进行修改的多个事务是彼此隔离的。这表明事务必须是独立的,不应该以任何方式以来于或影响其他事务。
④持久性(Durability):事务完成之后,它对于系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库
4.事务的保存点
SAVE TRANSACTION 保存点名称 --自定义保存点的名称和位置
ROLLBACK TRANSACTION 保存点名称 --回滚到自定义的保存点
其他高手的一些补充:
事务的标准定义: 指作为单个逻辑工作单元执行的一系列操作,而这些逻辑工作单元需要具有原子性, 一致性,隔离性和持久性四个属性,统称为ACID特性。
所谓事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位。例如,在关系数据库中,一个事务可以是一条SQL语句、一组SQL语句或整个程序。
事务和程序是两个概念。一般地讲,一个程序中包含多个事务。
事务的开始与结束可以由用户显式控制。如果用户没有显式地定义事务,则由DBMS按缺省规定自动划分事
务。在SQL语言中,定义事务的语句有三条:
BEGIN TRANSACTION
COMMIT
ROLLBACK
同生共死。。
显示事务被用begin transaction 与 end transaction 标识起来,其中的 update 与delete 语句或者全部执行或者全部不执行。。如:
begin transaction T1
update student
set name='Tank'
where id=2006010
delete from student
where id=2006011
commit
简单地说,事务是一种机制,用以维护数据库的完整性。
其实现形式就是将普通的SQL语句嵌入到Begin Tran...Commit Tran 中(或完整形式 BeginTransaction...Commit Transaction),当然,必要时还可以使用RollBack Tran 回滚事务,即撤销操作。
利用事务机制,对数据库的操作要么全部执行,要么全部不执行,保证数据库的一致性。需要使用事务的SQL语句通常是更新和删除操作等。
end transaction T1
关于savepoint
用户在事务(transaction)内可以声明(declare)被称为保存点(savepoint)
的标记。保存点将一个大事务划分为较小的片断。
用户可以使用保存点(savepoint)在事务(transaction)内的任意位置作标
记。之后用户在对事务进行回滚操作(rolling back)时,就可以选择从当前
执行位置回滚到事务内的任意一个保存点。例如用户可以在一系列复杂的更
新(update)操作之间插入保存点,如果执行过程中一个语句出现错误,用
户 可以回滚到错误之前的某个保存点,而不必重新提交所有的语句。
在开发应用程序时也同样可以使用保存点(savepoint)。如果一个过程
(procedure)内包含多个函数(function),用户可以在每个函数的开始位置
创建一个保存点。当一个函数失败时,就很容易将数据恢复到函数执行之前
的状态,回滚(roll back)后可以修改参数重新调用函数,或执行相关的错误
处理。
当事务(transaction)被回滚(rollback)到某个保存点(savepoint)后,
Oracle将释放由被回滚语句使用的锁。其他等待被锁资源的事务就可以继续
执行。需要更新(update)被锁数据行的事务也可以继续执行。
将事务(transaction)回滚(roll back)到某个保存点(savepoint)的过程如
下:
1. Oracle 回滚指定保存点之后的语句
2. Oracle 保留指定的保存点,但其后创建的保存点都将被清除
3. Oracle 释放此保存点后获得的表级锁(table lock)与行级锁(row
lock),但之前的数据锁依然保留。
被部分回滚的事务(transaction)依然处于活动状态,可以继续执行。
一个事务(transaction)在等待其他事务的过程中,进行回滚(roll back)到
某个保存点(savepoint)的操作不会释放行级锁(row lock)。为了避免事务
因为不能获得锁而被挂起,应在执行 UPDATE 或 DELETE 操作前使用 FOR
UPDATE ... NOWAIT 语句。(以上内容讲述的是回滚保存点之前所获得的
锁。而在保存点之后获得的行级锁是会被释放的,同时保存点之后执行的
SQL 语句也会被完全回滚)。

相关文章推荐
- MySQL中select filed from table where field in (....)语句的排序问题
- MySQL事务机制
- ThinkPHP中使用memcached缓存
- 修改mysql最大连接数的方法
- sql全文索引 sphinx
- SQL Server 2008 允许远程连接的解决方法
- MySQL数据库乱码
- mysql命中索引规律
- install mysql
- Oracle varchar2 4000
- install mysql
- sql存储过程几个简单例子
- mongodb在secondary不能直接获取primary的信息解决方法
- oracle 调用java执行系统命令(linux环境)
- 生产环境使用 pt-table-checksum 检查MySQL数据一致性
- 史上最全的MySQL备份方法
- Redis缓存Session
- SQL Server将一列的多行内容拼接成一行的问题讨论
- MySQL 5.6版本GTID复制异常处理一例
- 不同服务器数据库表之间的数据还原