one class SVM
2016-02-21 15:43
197 查看
背景:通常一类问题出现在需要对训练样本进行一定比例的筛选,或者已知的训练样本都是正样本,而负样本却很少的情况。
这种情况下,往往需要训练一个对于训练样本紧凑的分类边界,就可以通过负样本实验。一个简单的实际例子是:一个工厂对于产品的合格性进行检查时,往往所知道是合格产品的参数,而不合格的产品的参数要么空间比较大,要么知道的很少。这种情况下就可以通过已知的合格产品参数来训练一个一类分类器,得到一个紧凑的分类边界,超出这个边界就认为是不合格产品。形式化的说明知乎上有个很好的例子:
http://www.zhihu.com/question/22365729
原理:
它求解的模型如下所示:
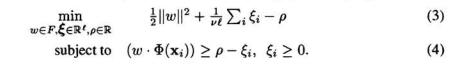
其中的参数V特别注意,它的值在0-1之间,是一个比例值,它的含义是:你的训练样本中最后被分类为负样本的比例。比如你有100个训练样本,V设为0.1,去学一个one class SVM,然后在学到的SVM上测试你之前用的训练集,最后可以看到有10个左右的样本的标签为-1,被分为负样本。下面还会通过实验进行说明。模型的求解等其他理论细节请参考大牛Bernhard Scholkopf的文章:Support Vector Method for Novelty Detection
http://papers.nips.cc/paper/1723-support-vector-method-for-novelty-detection.pdf
实验:
libsvm中有关于one class SVM的实现,算法就是根据上面Bernhard Scholkopf的文章。可以用下面代码进行测试:
通过上面的代码可以构造一个在圆内的训练样本,如下图所有:
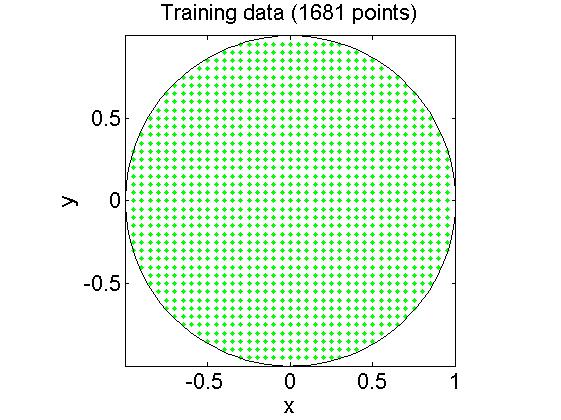
这样我们就假设所有圆外的样本为负样本,下面我们就进行one-class SVM训练,可以看到有个参数-n,它就是我们上面提到的V,也就是这些训练样本中包含负样本的比例。
上面的代码可以得到下面的结果:
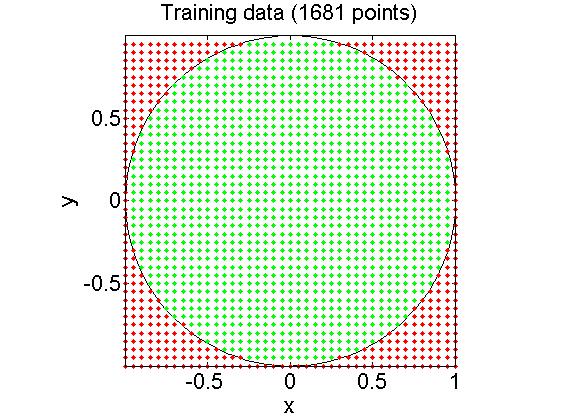
其中预测为正的用绿色表示,预测为负的用红色表示。
为了说明参数V的作用,将-n设为0.3后可以得到如下结果:
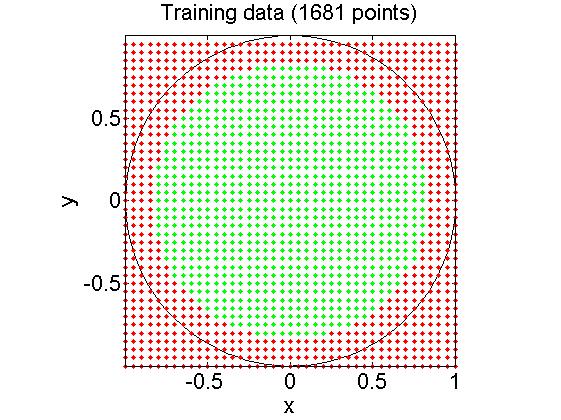
(黑线圆圈里是我们的训练样本的点)
上面是对负样本的检测效果验证,当一个新样本在圆内时,我们还是希望分类器可以将新样本分为正样本,下面就通过一段代码验证了这个效果:
上面的代码得到的效果如下图:
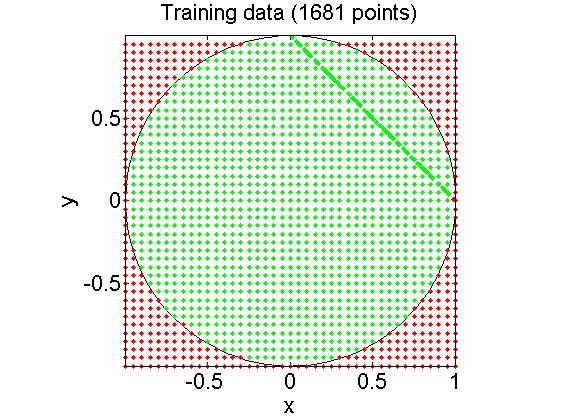
可以看到这些新样本的标签都分对了(n设为0.01的情况),另外,由于新样本(x1,y1)满足x1+y1=1所以显示在一条直线上。
这种情况下,往往需要训练一个对于训练样本紧凑的分类边界,就可以通过负样本实验。一个简单的实际例子是:一个工厂对于产品的合格性进行检查时,往往所知道是合格产品的参数,而不合格的产品的参数要么空间比较大,要么知道的很少。这种情况下就可以通过已知的合格产品参数来训练一个一类分类器,得到一个紧凑的分类边界,超出这个边界就认为是不合格产品。形式化的说明知乎上有个很好的例子:
http://www.zhihu.com/question/22365729
原理:
它求解的模型如下所示:
其中的参数V特别注意,它的值在0-1之间,是一个比例值,它的含义是:你的训练样本中最后被分类为负样本的比例。比如你有100个训练样本,V设为0.1,去学一个one class SVM,然后在学到的SVM上测试你之前用的训练集,最后可以看到有10个左右的样本的标签为-1,被分为负样本。下面还会通过实验进行说明。模型的求解等其他理论细节请参考大牛Bernhard Scholkopf的文章:Support Vector Method for Novelty Detection
http://papers.nips.cc/paper/1723-support-vector-method-for-novelty-detection.pdf
实验:
libsvm中有关于one class SVM的实现,算法就是根据上面Bernhard Scholkopf的文章。可以用下面代码进行测试:
% Generate training data
r = 20;
fprintf('Learning the function x^2 + y^2 < 1\n');
[XX,YY] = meshgrid(-1:1/r:1,-1:1/r:1);
X = [XX(:) YY(:)];
Y = 2*(sqrt(X(:,1).^2 + X(:,2).^2) < 1)-1 ;
Pin = find(Y==1);
X1 = X(Pin,:);
Y1 = Y(Pin);
% Plot training data
figure;hold on;
set(gca,'FontSize',16);
for i = 1:length(Y1)
if(Y1(i) > 0)
plot(X1(i,1),X1(i,2),'g.');
else
plot(X1(i,1),X1(i,2),'r.');
end
end
% Draw the decision boundary
theta = linspace(0,2*pi,100);
plot(cos(theta),sin(theta),'k-');
xlabel('x');
ylabel('y')
title(sprintf('Training data (%i points)',length(Y)));
axis equal tight; box on;通过上面的代码可以构造一个在圆内的训练样本,如下图所有:
这样我们就假设所有圆外的样本为负样本,下面我们就进行one-class SVM训练,可以看到有个参数-n,它就是我们上面提到的V,也就是这些训练样本中包含负样本的比例。
%%train one class SVM with 10% instances to be set as outlier model = svmtrain(Y1,X1,'-s 2 -n 0.01'); [Y1,Y2,Y3] = svmpredict(Y,X,model); for i = 1:length(Y) if(Y1(i) > 0) plot(X(i,1),X(i,2),'g.'); else plot(X(i,1),X(i,2),'r.'); end end
上面的代码可以得到下面的结果:
其中预测为正的用绿色表示,预测为负的用红色表示。
为了说明参数V的作用,将-n设为0.3后可以得到如下结果:
(黑线圆圈里是我们的训练样本的点)
上面是对负样本的检测效果验证,当一个新样本在圆内时,我们还是希望分类器可以将新样本分为正样本,下面就通过一段代码验证了这个效果:
X21 = rand(100,1); X22 = 1-X21; X2 = [X21 X22]; Y2 = ones(100,1); % X = [X;X2]; % Y = [Y;Y2]; [Y1,Y2,Y3] = svmpredict(Y2,X2,model); for i = 1:length(Y1) if(Y1(i) > 0) plot(X2(i,1),X2(i,2),'g.'); else plot(X2(i,1),X2(i,2),'r.'); end end
上面的代码得到的效果如下图:
可以看到这些新样本的标签都分对了(n设为0.01的情况),另外,由于新样本(x1,y1)满足x1+y1=1所以显示在一条直线上。

相关文章推荐
- libsvm支持向量机回归示例
- LSI SVM 挑战IBM SVC
- libsvm使用心得
- 支持向量机
- 高级IPv4 ACL典型配置指导
- 支持向量机(SVM)算法概述
- libsvm函数库使用说明
- Weka软件包管理器更新错误的解决方法
- 对SVM的认识
- SVM对手写数字的识别
- libsvm matlab 2013a for mac10.9 配置
- 使用深度卷积网络和支撑向量机实现的商标检测与分类的例子
- [转载]用opencv实现svm
- libsvm在matlab和Python上的探索
- Learning to ranking简介
- 结构风险最小和VC维理论的解释
- SVM学习
- matlab 使用最新版的libsvm-3.17
- OpenCV之CvANN_MLP和CvSVM测试
- Matlab中的多类别分类