数据结构与算法——图
2016-02-19 17:05
441 查看
图
在图中,节点之间的关系是任意的,任意两个节点之间都可能有关系
图的术语巨多无比,接下来给大家总结一下:
图分为有向图、无向图,无向图由定点和边组成,有向图有顶点和弧组成,弧分为弧头、弧尾。
图按照节点和边(弧)的多少分为,稀疏图、稠密图,这两者没有具体界定只是个人感觉概念。任意两个顶点之间都存在边就叫完全图,有向的叫有向完全图,无重复的边或者顶点到自身的边叫简单图。
顶点之间有邻接点、依附概念。无向图顶点的边数叫度,有向图分为入度、出度。
图上的边、弧带有权的叫网
顶点直接存在路径,两顶点直接存在路径就说明是连通的。如果路径能回到最初点就叫环,不重复的叫简单路径。任意两点都是连通的叫连通图,有向的叫强连通图。图中若包含子图,子图的最大连通就是连通分量,有向的称为强连通分量。
无向图中,连通且n个点,n-1条边叫生成树。有向图中一顶点入度为0其余顶点入度为1叫有向树,一个图由若干条有向树组成叫生成森林。
上面的皆是图的定义,完全不用背,多看几幅图就明白了。
图的存储
由于图没有顶点的概念且结构复杂,任意两点都有可能存在关系。所以用单纯的线性结构是不能存储的,所以请看下面各位前辈提供的存储方式。邻接矩阵:图是由顶点跟边组成的,那大家自然能想到的最直接的方式就是分开存储,但完全分开又没有关系的链接了。那分开又有关系的方法就是二维数组了。如下图
顶点分别是V0,V1,V2,V3,而下列的表就组成了一个边数的数组。有填1,没有填0,V1的度(连接V1得边数)为2。主对角斜线是V0-V0,V1-V1,V2-V2,V3-V3,不存在顶点到自身的边。
以主对角线为准是不是就形成了对称矩阵,这样的话只存一个三角就可以了。。。。
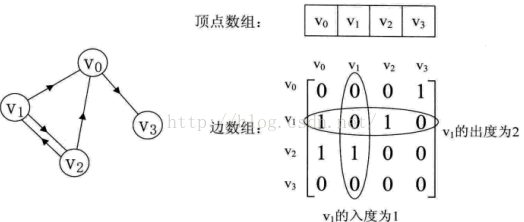
如下图,主对角线是0,但是因为此图是有向的所以并不对称。横向为入度,竖向为出度。所以图中横向的V1出度为2,竖向V1出度为1。
每条边上带权的图就叫网,下列就是一个有向网图。那么解释一下权,图中V0到V4得弧上有数字6.这就是一条带权的边。所以下列左边的图为一个有向网图
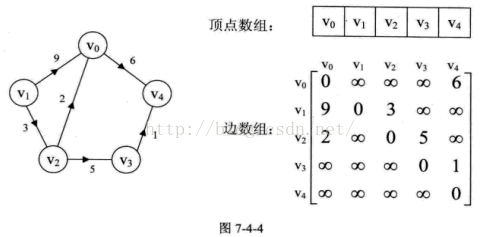
接下来创建邻接矩阵,其实就是给顶点表和边表输入数据的过程。
邻接矩阵是一个不错的存储方式,但是如果一个图里只有一条有权的边呢?那整个矩阵之中只有一个是有值得其他都为空,这样就大大的浪费了空间资源。
所以我们想出了新的办法:邻接表
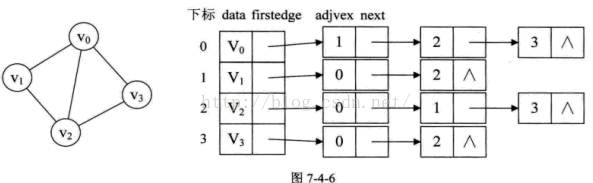
至于存储带权值的的网图,就再定义一份数据域存储权值即可。
十字链表
邻接表是由缺陷的,关心了出度问题想了解入度就必须全部遍历才可以。反之,逆邻接表解决了入度却不了解出度的情况,那么有没有办法把邻接表和逆邻接表结合起来?那就是十字链表:
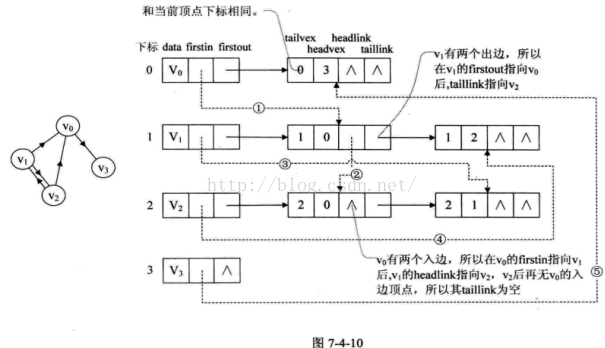
上图就是十字链表,看起来比较杂乱,但是,很好理解。以V1为例,一块空间指向1 0 和 1 2是出度,一块指向 2 1 是入度。这样就做到同时指向两块关系内存了。
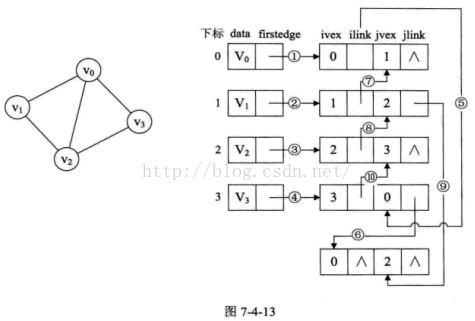
下面是邻接多重表:
如果在无向图中,我们关注的是顶点,那此时用邻接多重表是不错的选择。
ivex和jvex是某条边的两个顶点,ilink和jlink是指向ivex和jvex的吓一条边。
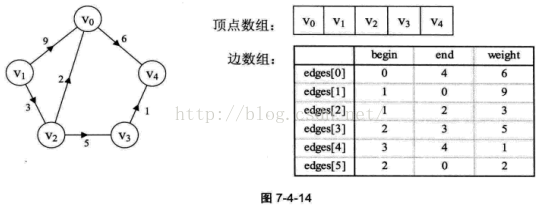
最后一个方法是边集数组:
是从begin开始到end得一条边,权为weight。
说了这么多得图的存储方式,他该怎么遍历呢?那么我们的遍历原则是:从某一个顶点出发访问遍图中其余点使每个顶点只被访问一次。
方式有两种:
1.深度优先遍历:
下图是我们储存数组之后的抽象形状。以A为例,A有两条边通向B和F,可以形成下图右边的图形。

依照上图右手边图形遍历,第一个遍历A然后记录并继续向下,一直继续到F都没有重复,继续右边是A,我们已经记录过所以后退回到F继续到G发现BD都走过那就后退,再来是H。此时我们已经遍历了一整个线路,但是还有很多没有遍历,那么这个时候我们要后退到G发现没有未便利过的,继续后退F,后退到E发现可以,可是H已经记录过,那么继续后退。
总结起来就是优先遍历下面的一层层回退到最顶端
void DFSTraverse(MGraph g){
int i;
for(i=0;i<g.numVertexes; i++)
visited[i]=FALSE; //初始化都没被访问
for(i=0;i<g.numVertexes; i++)
if(!visited[i])<span style="white-space:pre"> </span>//对没访问过得元素调用DFS
4000
DFS(G,i);
}void DFS(M<span style="font-family:Arial, Helvetica, sans-serif;">Graph</span><span style="font-family: Arial, Helvetica, sans-serif;"> g,int i</span><span style="font-family: Arial, Helvetica, sans-serif;">){</span>int j;
<pre name="code" class="cpp"> visited[i]=TRUE;<span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> //先设置为true</span>
<pre name="code" class="cpp"><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> print(g.vexs[i]);</span>
<pre name="code" class="cpp"><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;">for(j=0;j<g.numVertexes; j++)</span>
<span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;">if(g.arc[i][j] == 1 && !=visited[j])</span>
<span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> </span><span style="font-family: Arial, Helvetica, sans-serif;"> DFS(G,j);</span>
}
2.广度优先遍历:
如下图,首先遍历A,A有两个连接点B,F,然后B出栈,通过B找到C,I,G。F找到的是G,E 因为G存在了所以这里不存,弹出C通过C找到D,然后通过弹出I,但是与I相邻的已经遍历过了,那就不存,然后弹出G找到H,然后弹出E找不到相邻的。最后弹出D,H 整个过程完毕。 如下图出队列入队列。

最小生成树:就是利用最小的成本链接全部节点,就是N个节点,N-1条边把一个连通图连起来。并且使权值的和最小。

如上图7-6-2的三个方案。他们的权值相加,证明第三个是最优的。 相关的有两种算法,普利姆算法、克鲁斯卡尔算法
下面是算法内容,暂时没什么思路构思了之后写
拓扑排序
关键路径

相关文章推荐
- poj 1451(Trie)
- iOS学习_Lesson01_数据结构
- 关于VFS文件系统中的superblock、inode、d_entry和file数据结构
- Redis中5种数据结构的使用场景介绍
- Redis中5种数据结构的使用场景介绍
- 《数据结构与算法分析(c 描述)》—— 第二章笔记
- 数据结构之栈(四)
- HDU 5479 Scaena Felix(简单的数据结构题目)
- 《数据结构与算法分析(c 描述)》—— 第一章笔记
- c++ 数据结构 哈夫曼树
- poj 1195(二维树状数组)
- 数据结构实验之二叉树三:统计叶子数
- 学习笔记------数据结构(C语言版)数组之十字链表
- 数据结构---树形结构
- [NOIP2004]合并果子 T2 数据结构 简单贪心
- 数据结构之栈(三)
- C#中使用Redis不同数据结构的内存占有量的疑问和对比测试
- Java数据结构----优先队列
- 数据结构
- 学习笔记------数据结构(C语言版)数组之行逻辑链接的顺序表