PCA、LDA的参考学习、理解、混乱、清晰的过程
2016-02-18 15:12
239 查看
部分资料来自他人博客,基础上进行理解
LDA参考 http://blog.csdn.net/warmyellow/article/details/5454943
LDA算法入门
一. LDA算法概述:
线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。因此,它是一种有效的特征抽取方法。使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且同时类内散布矩阵最小。就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。
二. LDA假设以及符号说明:
假设对于一个
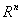
空间有m个样本分别为x1,x2,……xm 即 每个x是一个n行的矩阵,其中
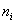
表示属于i类的样本个数,假设有一个有c个类,则

。
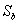
………………………………………………………………………… 类间离散度矩阵

………………………………………………………………………… 类内离散度矩阵
………………………………………………………………………… 属于i类的样本个数
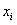
…………………………………………………………………………… 第i个样本

…………………………………………………………………………… 所有样本的均值
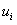
…………………………………………………………………………… 类i的样本均值
三. 公式推导,算法形式化描述
根据符号说明可得类i的样本均值为:
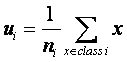
…………………………………………………………………… (1)
同理我们也可以得到总体样本均值:
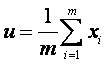
………………………………………………………………………… (2)
根据类间离散度矩阵和类内离散度矩阵定义,可以得到如下式子:
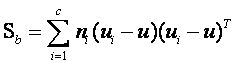
……………………………………………… (3)
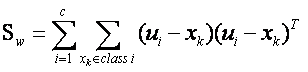
…………………………………… (4)
当然还有另一种类间类内的离散度矩阵表达方式:
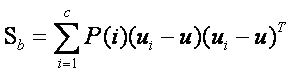
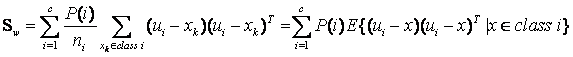
其中
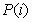
是指i类样本
的先验概率,即样本中属于i类的概率(

),把
代入第二组式子中,我们可以发现第一组式子只是比第二组式子都少乘了1/m,我们将在稍后进行讨论,其实对于乘不乘该1/m,对于算法本身并没有影响,现在我们分析一下算法的思想,
我们可以知道矩阵

的实际意义是一个协方差矩阵,这个矩阵所刻画的是该类与样本总体之间的关系,其中该矩阵对角线上的函数所代表的是该类相对样本总体的方差(即分散度),(横线是自己开始的认知混乱,把LDA公式当成了PCA快速计算里面的一个步骤,造成错误理解)用各子类作为样本,表示d个特征向量之间的相关性(假设是d维空间,有d个特征向量),那么,非对角线上的元素所代表的是不同特征向量之间的相关性,对角线元素反映的是d维中某个特征向量内的各子类相关性,是该类样本总体均值的协方差(即该类和总体样本的相关联度或称冗余度),所以根据公式(3)可知(3)式即把所有样本中各个样本根据自己所属的类计算出样本与总体的协方差矩阵的总和,这从宏观上描述了所有类和总体之间的离散冗余程度。同理可以的得出(4)式中为分类内各个样本和所属类之间的协方差矩阵之和,它所刻画的是从总体来看类内各个样本与类之间(这里所刻画的类特性是由是类内各个样本的平均值矩阵构成)离散度,其实从中可以看出不管是类内的样本期望矩阵还是总体样本期望矩阵,它们都只是充当一个媒介作用,不管是类内还是类间离散度矩阵都是从宏观上刻画出类与类之间的样本的离散度和类内样本和样本之间的离散度。
LDA做为一个分类的算法,我们当然希望它所分的类之间耦合度低,类内的聚合度高,即类内离散度矩阵的中的数值要小,而类间离散度矩阵中的数值要大,这样的分类的效果才好。
这里我们引入Fisher鉴别准则表达式:
PCA参考 http://pinkyjie.com/2010/08/31/covariance/
思考总结:
一维向量, 均值:表示向量平均数 方差:向量取值离散度 标准差:向量取值距向量均值的距离,方差开根号
二维向量, 协方差:表示两个向量之间的相关性,有2中计算方式
1、套用一维向量的方差公式,表示两个向量之间的相关性 ,
cov(X,Y)=∑ni=1(Xi−X¯)(Yi−Y¯)n−1
或者直接通过相关性公式计算:cov(X,Y)指向量x与向量y的 相关性, 样本矩阵MySample 10个样本,每个样本3个向量组成,所以这个样本矩阵 是每一个样本里面包含了多个向量 ,cov(MySample),指的是MySample里面的3个向量之间的相关性

协方差也只能处理二维问题,也就是只能反映2个向量之间的相关性,那维数多了自然就需要计算多个协方差,就需要协方差矩阵了
因此上面的 三维向量的样本矩阵MySample 向量x,y,z之间的相关性 通过如下协方差矩阵来表示,。

为了描述方便,我们先将三个维度的数据分别赋值:
计算dim1与dim2,dim1与dim3,dim2与dim3的协方差:
搞清楚了这个后面就容易多了,协方差矩阵的对角线就是各个维度上的方差,下面我们依次计算:
这样,我们就得到了计算协方差矩阵所需要的所有数据。
直接调用Matlab自带的

把我们计算的数据对号入座,是一摸一样的
2、向量中心化,样本矩阵转置*矩阵,除以(n-1)
Update:今天突然发现,原来协方差矩阵还可以这样计算,先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。其实这种方法也是由前面的公式通道而来,只不过理解起来不是很直观,但在抽象的公式推导时还是很常用的!同样给出Matlab代码实现:
注意区分:
1、矩阵转置*矩阵【 (X'*X) 】 并不是等于 协方差矩阵,
而是协方差矩阵可以通过样本矩阵转置相乘,再除以(n-1)的方式快速计算得到。
向量*向量的转置 = ?
2、LDA计算公式 既不是协方差的公式【差-积X*Y-和-均】,也不是 【矩阵转置*矩阵(X'*X) 】
而是【差-积(向量与自己转置的积(X*X'))-
和】
形式上更类似于 方差的概念【差-积(自己与自己)-和-均】 ,只不过方差里面的自乘积元素是标量, LDA里面自乘积的元素是矢量
3、卷积 不要把卷积和相关性混了
matlab中,cov() 是相关系数计算函数 卷积函数 conv——一维卷积 conv2——二维卷积
矩阵没有卷积,向量才有卷积
卷积:http://blog.csdn.net/anan1205/article/details/12313593
没有矩阵卷积的,只有向量卷积。当然,如果你硬要把向量理解为一个1*n的矩阵,那也说的过去。 图像中是存在矩阵卷积操作的。
所谓两个向量卷积,说白了就是多项式乘法。比如:p=[1 2 3],q=[1 1]是两个向量,p和q的卷积如下:把p的元素作为一个多项式的系数,多项式按升幂(或降幂)排列,比如就按升幂吧,写出对应的多项式:1+2x+3x^2;同样的,把q的元素也作为多项式的系数按升幂排列,写出对应的多项式:1+x。卷积就是“两个多项式相乘取系数”。(1+2x+3x^2)×(1+x)=1+3x+5x^2+3x^3所以p和q卷积的结果就是[1
3 5 3]。记住,当确定是用升幂或是降幂排列后,下面也都要按这个方式排列,否则结果是不对的。你也可以用matlab试试p=[1 2 3]q=[1 1]conv(p,q)看看和计算的结果是否相同。
LDA参考 http://blog.csdn.net/warmyellow/article/details/5454943
LDA算法入门
一. LDA算法概述:
线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。因此,它是一种有效的特征抽取方法。使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且同时类内散布矩阵最小。就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。
二. LDA假设以及符号说明:
假设对于一个
空间有m个样本分别为x1,x2,……xm 即 每个x是一个n行的矩阵,其中
表示属于i类的样本个数,假设有一个有c个类,则
。
………………………………………………………………………… 类间离散度矩阵
………………………………………………………………………… 类内离散度矩阵
………………………………………………………………………… 属于i类的样本个数
…………………………………………………………………………… 第i个样本
…………………………………………………………………………… 所有样本的均值
…………………………………………………………………………… 类i的样本均值
三. 公式推导,算法形式化描述
根据符号说明可得类i的样本均值为:
…………………………………………………………………… (1)
同理我们也可以得到总体样本均值:
………………………………………………………………………… (2)
根据类间离散度矩阵和类内离散度矩阵定义,可以得到如下式子:
……………………………………………… (3)
…………………………………… (4)
当然还有另一种类间类内的离散度矩阵表达方式:
其中
是指i类样本
的先验概率,即样本中属于i类的概率(
),把
代入第二组式子中,我们可以发现第一组式子只是比第二组式子都少乘了1/m,我们将在稍后进行讨论,其实对于乘不乘该1/m,对于算法本身并没有影响,现在我们分析一下算法的思想,
我们可以知道矩阵
的实际意义是一个协方差矩阵,这个矩阵所刻画的是该类与样本总体之间的关系,其中该矩阵对角线上的函数所代表的是该类相对样本总体的方差(即分散度),(横线是自己开始的认知混乱,把LDA公式当成了PCA快速计算里面的一个步骤,造成错误理解)用各子类作为样本,表示d个特征向量之间的相关性(假设是d维空间,有d个特征向量),那么,非对角线上的元素所代表的是不同特征向量之间的相关性,对角线元素反映的是d维中某个特征向量内的各子类相关性,是该类样本总体均值的协方差(即该类和总体样本的相关联度或称冗余度),所以根据公式(3)可知(3)式即把所有样本中各个样本根据自己所属的类计算出样本与总体的协方差矩阵的总和,这从宏观上描述了所有类和总体之间的离散冗余程度。同理可以的得出(4)式中为分类内各个样本和所属类之间的协方差矩阵之和,它所刻画的是从总体来看类内各个样本与类之间(这里所刻画的类特性是由是类内各个样本的平均值矩阵构成)离散度,其实从中可以看出不管是类内的样本期望矩阵还是总体样本期望矩阵,它们都只是充当一个媒介作用,不管是类内还是类间离散度矩阵都是从宏观上刻画出类与类之间的样本的离散度和类内样本和样本之间的离散度。
LDA做为一个分类的算法,我们当然希望它所分的类之间耦合度低,类内的聚合度高,即类内离散度矩阵的中的数值要小,而类间离散度矩阵中的数值要大,这样的分类的效果才好。
这里我们引入Fisher鉴别准则表达式:
PCA参考 http://pinkyjie.com/2010/08/31/covariance/
思考总结:
一维向量, 均值:表示向量平均数 方差:向量取值离散度 标准差:向量取值距向量均值的距离,方差开根号
二维向量, 协方差:表示两个向量之间的相关性,有2中计算方式
1、套用一维向量的方差公式,表示两个向量之间的相关性 ,
cov(X,Y)=∑ni=1(Xi−X¯)(Yi−Y¯)n−1
或者直接通过相关性公式计算:cov(X,Y)指向量x与向量y的 相关性, 样本矩阵MySample 10个样本,每个样本3个向量组成,所以这个样本矩阵 是每一个样本里面包含了多个向量 ,cov(MySample),指的是MySample里面的3个向量之间的相关性
协方差也只能处理二维问题,也就是只能反映2个向量之间的相关性,那维数多了自然就需要计算多个协方差,就需要协方差矩阵了
因此上面的 三维向量的样本矩阵MySample 向量x,y,z之间的相关性 通过如下协方差矩阵来表示,。
为了描述方便,我们先将三个维度的数据分别赋值:
123 | dim1 = MySample(:,1);dim2 = MySample(:,2);dim3 = MySample(:,3); |
123 | sum( (dim1-mean(dim1)) .* (dim2-mean(dim2)) ) / ( size(MySample,1)-1 ) % 得到 74.5333sum( (dim1-mean(dim1)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -10.0889sum( (dim2-mean(dim2)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -106.4000 |
123 | std(dim1)^2 % 得到 108.3222std(dim2)^2 % 得到 260.6222std(dim3)^2 % 得到 94.1778 |
直接调用Matlab自带的
cov函数进行验证:
1 | cov(MySample) |
把我们计算的数据对号入座,是一摸一样的
2、向量中心化,样本矩阵转置*矩阵,除以(n-1)
Update:今天突然发现,原来协方差矩阵还可以这样计算,先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。其实这种方法也是由前面的公式通道而来,只不过理解起来不是很直观,但在抽象的公式推导时还是很常用的!同样给出Matlab代码实现:
12 | X = MySample - repmat(mean(MySample),10,1); % 中心化样本矩阵,使各维度均值为0C = (X'*X)./(size(X,1)-1); |
1、矩阵转置*矩阵【 (X'*X) 】 并不是等于 协方差矩阵,
而是协方差矩阵可以通过样本矩阵转置相乘,再除以(n-1)的方式快速计算得到。
向量*向量的转置 = ?
2、LDA计算公式 既不是协方差的公式【差-积X*Y-和-均】,也不是 【矩阵转置*矩阵(X'*X) 】
而是【差-积(向量与自己转置的积(X*X'))-
和】
形式上更类似于 方差的概念【差-积(自己与自己)-和-均】 ,只不过方差里面的自乘积元素是标量, LDA里面自乘积的元素是矢量
3、卷积 不要把卷积和相关性混了
matlab中,cov() 是相关系数计算函数 卷积函数 conv——一维卷积 conv2——二维卷积
矩阵没有卷积,向量才有卷积
卷积:http://blog.csdn.net/anan1205/article/details/12313593
没有矩阵卷积的,只有向量卷积。当然,如果你硬要把向量理解为一个1*n的矩阵,那也说的过去。 图像中是存在矩阵卷积操作的。
所谓两个向量卷积,说白了就是多项式乘法。比如:p=[1 2 3],q=[1 1]是两个向量,p和q的卷积如下:把p的元素作为一个多项式的系数,多项式按升幂(或降幂)排列,比如就按升幂吧,写出对应的多项式:1+2x+3x^2;同样的,把q的元素也作为多项式的系数按升幂排列,写出对应的多项式:1+x。卷积就是“两个多项式相乘取系数”。(1+2x+3x^2)×(1+x)=1+3x+5x^2+3x^3所以p和q卷积的结果就是[1
3 5 3]。记住,当确定是用升幂或是降幂排列后,下面也都要按这个方式排列,否则结果是不对的。你也可以用matlab试试p=[1 2 3]q=[1 1]conv(p,q)看看和计算的结果是否相同。

相关文章推荐
- PPT嵌入字体的方法
- 怎么限制Google自己主动调整字体大小
- 算法基础:整数排序问题(连续整数仅仅保留首尾两个数字)
- RSA算法原理
- 解决pod search出来的库不是最新
- php代码缓存问题
- MySQL数据库的优化
- Cef重要概念
- C语言二分查找法
- android—binder进程间通讯流程分析
- RxJava 操作符分类
- Android Day02 --java基础
- Android中Video的三种播放方式的实现
- matlab画甘特图
- 系统负载测试工具-LoadRunner
- #2015年总结
- android studio下“HAX is not working...”问题的解决
- putty远程连接工具使用
- Cef应用资源布局
- LeakCanary 中文使用说明