hadoop
2016-02-18 00:00
232 查看
摘要: Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
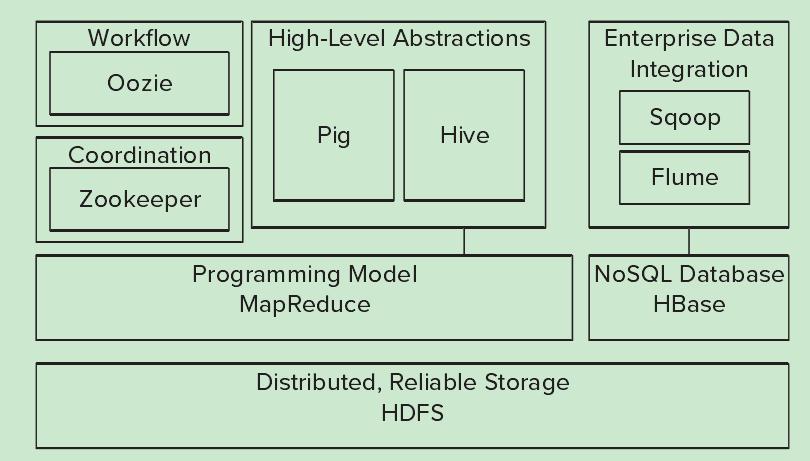
HDFS—— Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS为HBase等工具提供了基础。
MapReduce ——Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型。MapReduce把任务分为map(映射)阶段和 reduce(化简)。开发人员使用存储在HDFS中数据(可实现快速存储),编写Hadoop的MapReduce任务。由于MapReduce工作原 理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
Hbase——HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
Zookeeper ——用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Oozie——Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Pig——它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
Hive ——Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这 些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分 析师。
Hadoop的生态圈还包括以下几个框架,用来与其它企业融合:
Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop。
除了在图1-1所示的核心部件外,Hadoop生态圈正在不断增长,以提供更新功能和组件,如以下内容:
Whirr——Whirr是一组用来运行云服务的Java类库,使用户能够轻松地将Hadoop集群运行于Amazon EC2、Rackspace等虚拟云计算平台。
Mahout——Mahout是一个机器学习和数据挖掘库,它提供的MapReduce包含很多实现,包括聚类算法、回归测试、统计建模。通过使用 Apache Hadoop 库,可以将Mahout有效地扩展到云中。
BigTop —— BigTop作为Hadoop子项目和相关组件,是一个用于打包和互用性测试的程序和框架。
Ambari——Ambar通过为配置、管理和监控Hadoop集群提供支持,简化了Hadoop的管理。
HDFS—— Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS为HBase等工具提供了基础。
MapReduce ——Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型。MapReduce把任务分为map(映射)阶段和 reduce(化简)。开发人员使用存储在HDFS中数据(可实现快速存储),编写Hadoop的MapReduce任务。由于MapReduce工作原 理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
Hbase——HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
Zookeeper ——用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
Oozie——Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Pig——它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
Hive ——Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这 些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分 析师。
Hadoop的生态圈还包括以下几个框架,用来与其它企业融合:
Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop。
除了在图1-1所示的核心部件外,Hadoop生态圈正在不断增长,以提供更新功能和组件,如以下内容:
Whirr——Whirr是一组用来运行云服务的Java类库,使用户能够轻松地将Hadoop集群运行于Amazon EC2、Rackspace等虚拟云计算平台。
Mahout——Mahout是一个机器学习和数据挖掘库,它提供的MapReduce包含很多实现,包括聚类算法、回归测试、统计建模。通过使用 Apache Hadoop 库,可以将Mahout有效地扩展到云中。
BigTop —— BigTop作为Hadoop子项目和相关组件,是一个用于打包和互用性测试的程序和框架。
Ambari——Ambar通过为配置、管理和监控Hadoop集群提供支持,简化了Hadoop的管理。

相关文章推荐
- nginx 配置 中英
- apache 配置 中英
- apache.commons.logging.Log
- Linux下安装GCC5.3.0(亲测有效)
- 寻求系统架构师合作开发项目
- Linux下Mysql主从配置
- centos环境下php7安装记录
- tomcat运行失败
- spark架构详解
- CDH集群中YARN的参数配置
- 关于Thread对象的suspend,resume,stop方法
- 方框滤波,高斯滤波,中值滤波,双边滤波,opencv实现
- VS2012配置OpenCV2.4.9
- Linux 文件系统:procfs, sysfs, debugfs 用法简介
- Apache 编译 --with-apr parameter is incorrect 错误
- 老王学linux-centos6.7RHCS
- 传智播客168期JavaEE就业班(第八天 WEB简介 Tomcat)
- springmvc应用程序使用maven部署到tomcat中时产生的异常的解决(javax/servlet/ServletContext&SpringServletContainerInitializer->javax.servlet.ServletContainerInitializer)
- 20160217自学Linux_最基本(ls,cd,date,cal,stat,printenv,flie)+使用帮助
- centos开放8000端口