学习记录 - 3
2016-02-10 23:34
399 查看
聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。- 维基百科
聚类分析是数据挖掘中一种重要的分析方法。对大量数据进行聚类分析,从未知中找到有意义的分类,挖掘每一类的特点和内在联系,加强对于事物本质关系的理解,这样有助于可以提高效率。比如应用于分析用户、顾客需求等等。
著名的“啤酒与尿布”的案例,属于购物篮分析,也是一个典型的商品聚类的问题。(据说此案例是编出来的,不过用来说明聚类的效益还是很好的)
smartbi的节点库也有聚类分析节点,包括k-means、层次聚类方法、模糊C均值、异常、类分配器、相似搜索。
k-means就是一种聚类算法,它可以把杂乱无章的、无标记的数据中自行分为k类。它的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为k个类别,算法描述如下:
适当选择k个类的初始中心;
在第n次迭代中,对任意一个样本,求其到k个中心的距离,将该样本归到距离最短的中心所在的类;
利用均值等方法更新该类的中心值;
对于所有的k个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
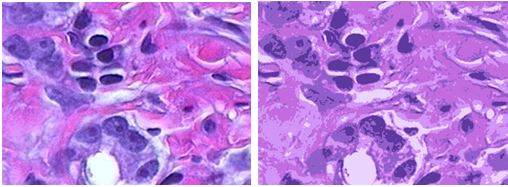
以前接触过k-means算法,对H&E image应用k-means聚类,左图为原图像,右图为聚类后的图像。
在图像压缩中应用,这样对k-means算法形成一个直观印象。
层次聚类算法,通过对数据集按照某种方法进行层次分解,直到满足某种条件为止。按照分类原理的不同,可以分为凝聚和分裂两种方法。
凝聚的层次聚类是一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足,绝大多数层次聚类方法属于这一类,它们只是在簇间相似度的定义上有所不同。
分裂的层次聚类与凝聚的层次聚类相反,采用自顶向下的策略,它首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。
例如,凝聚的层次聚类

假如上图层次聚类时在第二层就满足了终止条件,则会得到下面的结果。

其他的下次再看:)
附 对H&E image应用k-means聚类的matlab代码
以前简单粗暴的实现,尚未优化
聚类分析是数据挖掘中一种重要的分析方法。对大量数据进行聚类分析,从未知中找到有意义的分类,挖掘每一类的特点和内在联系,加强对于事物本质关系的理解,这样有助于可以提高效率。比如应用于分析用户、顾客需求等等。
著名的“啤酒与尿布”的案例,属于购物篮分析,也是一个典型的商品聚类的问题。(据说此案例是编出来的,不过用来说明聚类的效益还是很好的)
smartbi的节点库也有聚类分析节点,包括k-means、层次聚类方法、模糊C均值、异常、类分配器、相似搜索。
k-means就是一种聚类算法,它可以把杂乱无章的、无标记的数据中自行分为k类。它的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为k个类别,算法描述如下:
适当选择k个类的初始中心;
在第n次迭代中,对任意一个样本,求其到k个中心的距离,将该样本归到距离最短的中心所在的类;
利用均值等方法更新该类的中心值;
对于所有的k个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
以前接触过k-means算法,对H&E image应用k-means聚类,左图为原图像,右图为聚类后的图像。
在图像压缩中应用,这样对k-means算法形成一个直观印象。
层次聚类算法,通过对数据集按照某种方法进行层次分解,直到满足某种条件为止。按照分类原理的不同,可以分为凝聚和分裂两种方法。
凝聚的层次聚类是一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足,绝大多数层次聚类方法属于这一类,它们只是在簇间相似度的定义上有所不同。
分裂的层次聚类与凝聚的层次聚类相反,采用自顶向下的策略,它首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件。
例如,凝聚的层次聚类
假如上图层次聚类时在第二层就满足了终止条件,则会得到下面的结果。
其他的下次再看:)
附 对H&E image应用k-means聚类的matlab代码
以前简单粗暴的实现,尚未优化
%读取图片
I0=imread('kmeans_image.png');
I=im2double(I0);
I2=zeros(size(I));
%imshow(I);
%参数
k=5;%中心的个数
N=size(I);%图片大小
eps=1e-4;
cls=zeros(N(1),N(2));%类别
a=zeros(k,1);
center_rgb=zeros(k,3);
new_center=zeros(k,3);
temp=zeros(N(1),N(2),k);%存储每个点到k个中心的距离
sum=zeros(k,3);
%随机选择k个中心,存储其color值
center=[randi(N(1),k,1) randi(N(2),k,1)];%center(i,:)表示第i个中心
for j=1:k
center_rgb(j,:)=I(center(j,1),center(j,2),:);
end
for times=1:20
%求每个像素的值到k个中心值的欧氏距离
for i=1:N(1)
for j=1:N(2)
for m=1:k
a=[I(i,j,1) I(i,j,2) I(i,j,3)];
temp(i,j,m)=norm(a-center_rgb(m,:));
end
end
end
%找到每个像素最小的距离并记录其类别
for i=1:N(1)
for j=1:N(2)
for m=1:k
a(m)=temp(i,j,m);
end
[minv cls(i,j)]=min(a);
end
end
%计算每一类别的中心
sum=sum*0;
for i=1:N(1)
for j=1:N(2)
sum(cls(i,j),:)=sum(cls(i,j),:)+[I(i,j,1) I(i,j,2) I(i,j,3)];
end
end
for m=1:k
new_center(m,:)=sum(m,:)/length(find(cls==m));
end
index=norm(new_center-center_rgb);
if index<eps
break;
else
center_rgb=new_center;
end
%I(1:3,4:6,:)
end
%对图片进行聚类
for i=1:N(1)
for j=1:N(2)
m=cls(i,j);
I2(i,j,1)=new_center(m,1);
I2(i,j,2)=new_center(m,2);
I2(i,j,3)=new_center(m,3);
end
end
imshow(I2);
%imwrite(I2,'after_kmeans.png','png');
%%灰度
%读取图片
I0=imread('kmeans_image.png');
I=rgb2gray(I0);
I=im2double(I);
I2=zeros(size(I));
J=zeros(10,1);
%imshow(I);
%参数
% for k=1:10
k=8;%中心的个数
N=size(I);%图片大小
eps=1e-6;
cls=zeros(N(1),N(2));%类别
a=zeros(k,1);
center_rgb=zeros(k,1);
new_center=zeros(k,1);
%适当选择k个中心,存储其灰度值
center=[randi(N(1),k,1) randi(N(2),k,1)];%center(i,:)表示第i个中心
for j=1:k
center_rgb(j)=I(center(j,1),center(j,2));
end
for times=1:50
%找到每个像素最小的灰度距离记录其类别
for i=1:N(1)
for j=1:N(2)
a=abs(I(i,j)-center_rgb);
[minv cls(i,j)]=min(a);
end
end
%计算每一类别的中心
a=a*0;
for i=1:N(1)
for j=1:N(2)
a(cls(i,j))=a(cls(i,j))+I(i,j);
end
end
for m=1:k
new_center(m)=a(m)/length(find(cls==m));
end
index=norm(new_center-center_rgb);
if index<eps
break;
else
center_rgb=new_center;
end
end
%对图片进行聚类
for i=1:N(1)
for j=1:N(2)
m=cls(i,j);
I2(i,j)=new_center(m);
end
end
imshow(I2);
% for m=1:k
% for i=1:N(1)
% for j=1:N(2)
% J(k)=J(k)+(I(i,j)-new_center(cls(i,j)))^2;
% end
% end
% end
% k
% end
% p=polyfit(x,J',3);
% xi=linspace(1,10);
% yi=polyval(p,xi);
% plot(x,J','o',xi,yi);
% imwrite(I2,'after_kmeans_gray.png','png');

相关文章推荐
- python中kmeans聚类实现代码
- 聚类算法总结
- kmeans python版
- Mahout-kmeans命令行文本文件聚类
- 聚类问题
- 聚类分析
- gmm(Gaussian Mixture Mode)的理解
- 聚类(序)——监督学习与无监督学习
- 聚类(1)——混合高斯模型 Gaussian Mixture Model
- 聚类(2)——层次聚类 Hierarchical Clustering
- Kmeans和FMC自己理解
- K-means(K-均值)算法和降维对分算法 VB实现及应用
- 阅读笔记之:Multimodal learning in Loosely-organized web images-CVPR2014
- 聚类与神经网络
- 基于密度的聚类
- 像元纯度指数算法C++实现
- 【机器学习】K-means聚类
- 聚类分析学习笔记
- 针对toy datasets的不同聚类方法比较
- Kmeans算法详解及实现