java国际化——日期和时间+排序
2016-02-04 14:38
495 查看
【0】README
1) 本文部分文字描述转自 core java volume 2 , 测试源代码均为原创, 旨在理解 java国际化——日期和时间+排序 的基础知识 ;【1】日期和时间
1)当格式化日期和时间时,需要考虑4个与 Locale 相关的问题: (干货——当格式化日期和时间时,需要考虑4个与 Locale 相关的问题)1.1)月份和星期应该用本地语言来表示;
1.2)年月日的顺序要符合本地习惯;
1.3)公历可能不是本地首选的日期表示方法;
1.4)必须要考虑本地的时区;
2)solution: java 的 DateFormat 类可以处理这些问题。 它和 NumberFormat 类很相似;
step1)首先, 得到一个 Locale, 可以使用默认的Locale 或调用静态的 getAvialbleLocales 方法来得到一个 支持日期格式化的Locale 数组;
step2)然后,调用下列3个工厂方法之一:
fmt = DateFormat.getDateInstance(dateStyle, loc);
fmt = DateFormat.getTimeInstance(timeStyle, loc);
fmt = DateFormat.getDateTimeInstance(dateStyle, timeStyle, loc);
2.1)为了支持设定想要的风格, 这些工厂方法设计了一个参数,可以是如下值:
DateFormat.DEFAULT
DateFormat.FULL
DateFormat.LONG
DateFormat.MEDIUM
DateFormat.SHORT
2.2) 工厂方法返回一个格式化对象, 可以用它来格式化日期:
Date now = new Date();
String s = fmt.format(now);
2.3)和 NumberFormat 类一样, 你可以使用 parse 方法来解析用户输入的一个日期(解析String类型)。如
TextField inputField ;
DateFormat format = DateFormat.getDateInstance(DateFormat.MEDIUM);
Date input = fmt.parse(inputField.getText().trim());
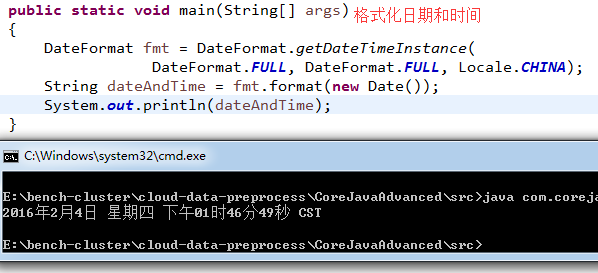
3)看个荔枝(格式化日期和时间):
// date format with given locale
public static void main(String[] args)
{
DateFormat fmt = DateFormat.getDateTimeInstance(
DateFormat.FULL, DateFormat.FULL, Locale.CHINA);
String dateAndTime = fmt.format(new Date());
System.out.println(dateAndTime); // Thu Feb 04 13:48:59 CST 2016
try
{
System.out.println(fmt.parse(dateAndTime.toString()));
} catch (ParseException e)
{
e.printStackTrace();
}
}
【2】排序(不同Locales, 不同的规则罢了, Collator 叫做排序器)
1)problem+solution1.1)problem: java中的 compareTo方法使用 Unicode字符来决定顺序的。如,小写字母的Unicode值比大写的大,有重音符的字母的值甚至更大, 这将使结果失去意义(如大写A,和重音符A,无法通过字典序做比较);
1.2)solution: 一般,先得到一个 Locale 对象,然后,调用 getInstance 工厂方法来得到一个 Collator 对象,最后,当希望对字符串进行排序时,使用这个排序器的compare方法,而不是String类的 compareTo 方法, 如:
Locale loc = ....; Collator coll = Collator.getInstance(loc); if(coll.compare(a,b) < 0) // a comes before b...
Attention) 更为重要的是, Collator 类实现了 Comparetor 接口, 因此,可以传一个 排序器对象到 Collections.sort 方法来对一组字符串进行排序: Collections.sort(strings, coll);
【3】排序强度
1)字符间的差别: 分为首要的、其次的、和再次的;如, A 和 Z 之间的差别被归为首要的, 而 A 和 A(头顶小圆圈)的差别是其次的, 而A 和 a 是再次的;2)排序强度设置:

2.1)如果将强度设为 Collator.PRIMARY:那么排序器将只关注 primary级的差别;
2.2) 如果将强度设为 Collator.SECONDARY: 那么排序器将关注 primary + secondary 级的差别, 也就是说,两个字符串在“secondary”或“tertiary”强度下很容易被区分开;
2.3) 如果将强度设为 Collator.IDENTICAL:则不允许有任何差异;这种设置在与排序器的第二种具有相当技术性的设置,即分解模式,联合使用时,就会显得特别有用;
【4】排序器分解模式
1)分解: 即一个字符对应多个Unicode编码;如A(头顶一个圆圈)可以是Unicode字符 U+00C5, 或者表示为 普通的A(U+0065)后跟一个圆圈;2)Unicode标准: 对字符串定义了四种范化形式: D, KD, C 和 KC;
3)我们可以选择排序器所使用的范化程度(如下表所示):

3.1)NO_DECOMPOSITION(不分解): Collator.NO_DECOMPOSITION 表示不对字符串做任何范化,这时选项处理速度较快, 但是对于以多种形式表示字符的文本就显得不适用了;
3.2)CANONICAL_DECOMPOSITION(规范分解): 默认值Collator.CANONICAL_DECOMPOSITION 使用 范化形式D, 这对于包含重音但不包含连字的文本是非常有用的形式;
3.3)完全分解: 最后是使用 范化形式KD的完全分解;
4)让排序器去多次分解一个字符串是很浪费时间的: getCollationKey方法: 返回一个 CollationKey对象, 可以用它来进行更深入的,更快速的比较操作,下面是一个荔枝: (干货——让排序器去多次分解一个字符串是很浪费时间的,故而引入了 getCollationKey方法, CollationKey==排序键)
String a = …;
CollationKey key = coll.getCollationKey(a);
if(key.compareTo(coll.getCollationKey(b)) == 0) // fast comparison
5)最后,有可能在你不需要进行排序时, 也希望将字符串转换为它们的范化形式。java.text.Normalizer 类实现了 对范化的处理, 如:
String name = “augs”;
String normalized = Normalizer.normalize(name, Normalizer.Form.NFD); // use normalization from D
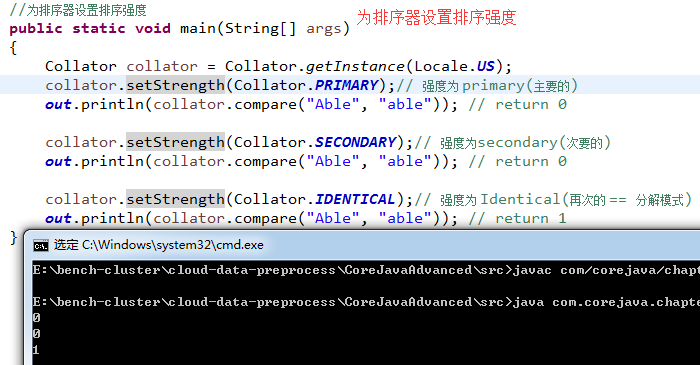
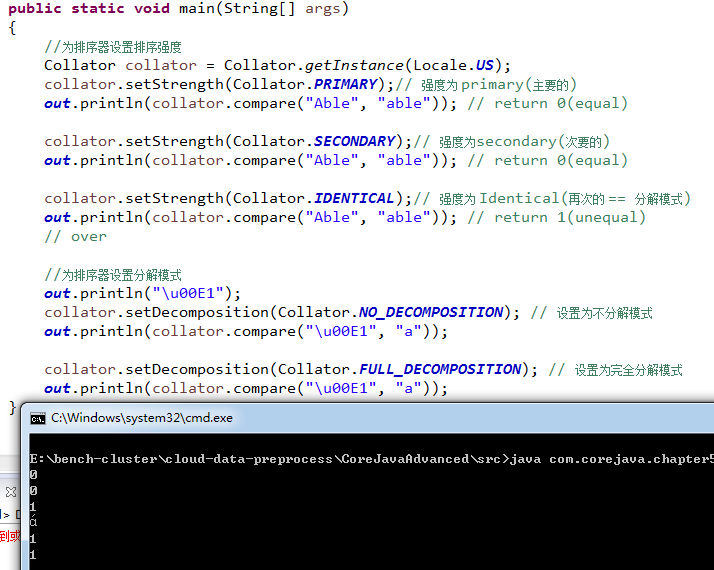
6)看个荔枝(为排序器设置排序强度和为排序器设置分解模式):
public static void main(String[] args)
{
//为排序器设置排序强度
Collator collator = Collator.getInstance(Locale.US);
collator.setStrength(Collator.PRIMARY);// 强度为 primary(主要的)
out.println(collator.compare("Able", "able")); // return 0(equal)
collator.setStrength(Collator.SECONDARY);// 强度为secondary(次要的)
out.println(collator.compare("Able", "able")); // return 0(equal)
collator.setStrength(Collator.IDENTICAL);// 强度为 Identical(再次的 == 分解模式)
out.println(collator.compare("Able", "able")); // return 1(unequal)
// over
//为排序器设置分解模式
out.println("\u00E1");
collator.setDecomposition(Collator.NO_DECOMPOSITION); // 设置为不分解模式
out.println(collator.compare("\u00E1", "a"));
collator.setDecomposition(Collator.FULL_DECOMPOSITION); // 设置为完全分解模式
out.println(collator.compare("\u00E1", "a"));
}

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- c++11 + SDL2 + ffmpeg +OpenAL + java = Android播放器
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树