(2016)[SAS数据处理] 利用二分法思想加速DATA步数据截取操作 [v1.02]
2016-01-30 02:01
387 查看
在使用SAS软件进行大规模数据处理(large-scale data processing)时,我们常常会遇到以下的数据分布场景:
待处理的数据集(dataset)至少具有10亿级别的观测数(N)和若干个字段(常在20个到200个不等);
数据集已经预先根据某个字段(column)排序过(通常在数据生成过程中进行),例如,根据日期、时间字段等进行升序排列;
业务流程只要求获取满足特定(时间)范围条件的局部数据,而非整个数据集。例如,只选取2015-12-01到2015-12-31日期范围内的数据,或者只截取2016-01-01号的数据。
针对此场景,比较容易想到的是使用DATA步中的WHERE语句进行截取数据;但是其在截取大规模数据时,这种方法显得耗时、低效(因为WHERE需要对每一条观测进行条件比较)。如果使用PROC SQL过程,依然涉及到WHERE语句的使用,且效率更低。为此,基于经典的二分法查找(binary search)思想,我们(HXC + DQQ)编写了一段简易的SAS宏(MACRO)程序,以提高SAS程序的运行效率。
现假设我们面对的是一个具有10亿观测数、50个字段的数据集(且数据集已经根据[date]字段升序排列),我们的需求是截取2015-07-31号的数据,以备后期的数据分析使用(整个数据集的时间跨度为2008-01-01到2016-01-07)。如果在DATA步中使用WHERE语句截取以上的数据集,可能至少需要1个小时;而使用这个简易的SAS宏程序,一般在5分钟之内即可完成任务。但为什么能够取得如此显著的提速呢?主要基于以下两点理由:
1、相对于WHERE语句采用的线性搜索,其时间复杂度为θ(N);而二分法的时间复杂度只为θ(〖log〗_2 N)。例如,在具有10亿观测数的数据集中根据条件定位一条记录,二分法在最坏的情况下也只需要大约30次比较操作;而线性搜索在最坏的情况下却需要10亿次比较(性能差异就是如此明显)。一般而言,数据集的观测数(N)越多,二分法的优势就越明显。但特别需要注意的是:对于二分法而言,要求必须预先对数据集的条件字段进行排序!换言之,二分法不能处理没经过排序的数据集。
2、利用DATA步中的FIRSTOBS和OBS语句(需要组合使用),获取大型数据集中的任意一条记录,所需的时间成本基本上可以完全忽略(这类似于RAM随机访问模式,而非耗时的顺序访问模式)。具体的使用方式,可参见下面的SAS宏程序;或者参见图书《SAS编程与数据挖掘商业案例》(作者:姚志勇)中给出的具体原因解释和实践。
与经典二分法不同,这里的宏程序所面对的是略微不同的需求场景:所要搜索的观测可能不唯一(尤其是在大数据集中存在着大量满足搜索条件的观测),需要找出满足搜索条件的观测范围(即开始节点和结束节点);而经典二分法一般只要求返回一条满足搜索条件的观测即可。虽然the deferred detection algorithm也可以近似地处理以上的需求场景;但由于研究较少,本博客将不予讨论。在此,先给出经典二分法的Python极简易版本代码(以对比冗繁的SAS代码):
基于递归的经典二分法Python代码:
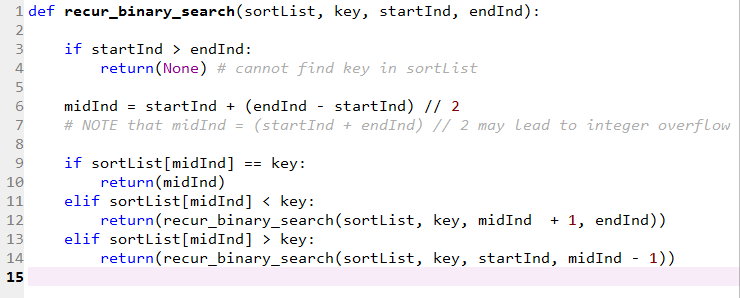
基于循环的经典二分法Python代码:
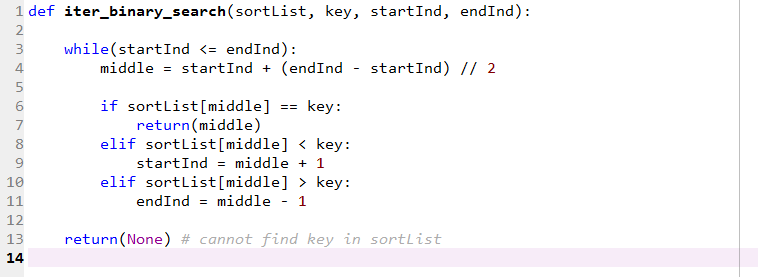
不同于以上简洁的Python代码,SAS宏程序要显得冗余许多(但能够处理更一般的情况),其具体的SAS代码如下所示:
有趣的是:以上的宏程序可以看做是对经典二分法的直接扩充;其整体的时间复杂度依然为θ(log2(N))。以上的SAS宏程序对于特定格式的数据集进行定位、截取操作是非常有效的。这也再次在实践上验证了:算法设计的美妙与意义(即通过时间复杂性理论指导算法设计)。
前路漫漫,上下而求索之!
博客相关信息:
SAS宏程序设计:HXC,修改、规范化:DQQ;
博客编写:DQQ,审阅:GJ、HXC,修改:GJ。
如有任何疑问或交流,欢迎联系:DQQ ( duanqq@jointstarc.com )。本博客所涉及到的所有SAS/Python源程序、以及博客的pdf/word版本,都可通过E-mail联系获取(FREE! JUST FOR FUN!)。
[注]: SAS是美国SAS公司的商业产品和商标;Python为有趣的开源编程语言。
参考资料:
[1]. https://en.wikipedia.org/wiki/Binary_search_algorithm
[2]. http://www.mathmeth.com/wf/files/wf2xx/wf214.pdf
[3]. http://www.codecodex.com/wiki/Binary_search
[4]. http://www.sas.com/en_us/software/enterprise-guide.html
[5]. https://www.python.org/
[6]. http://item.jd.com/1060284.html
待处理的数据集(dataset)至少具有10亿级别的观测数(N)和若干个字段(常在20个到200个不等);
数据集已经预先根据某个字段(column)排序过(通常在数据生成过程中进行),例如,根据日期、时间字段等进行升序排列;
业务流程只要求获取满足特定(时间)范围条件的局部数据,而非整个数据集。例如,只选取2015-12-01到2015-12-31日期范围内的数据,或者只截取2016-01-01号的数据。
针对此场景,比较容易想到的是使用DATA步中的WHERE语句进行截取数据;但是其在截取大规模数据时,这种方法显得耗时、低效(因为WHERE需要对每一条观测进行条件比较)。如果使用PROC SQL过程,依然涉及到WHERE语句的使用,且效率更低。为此,基于经典的二分法查找(binary search)思想,我们(HXC + DQQ)编写了一段简易的SAS宏(MACRO)程序,以提高SAS程序的运行效率。
现假设我们面对的是一个具有10亿观测数、50个字段的数据集(且数据集已经根据[date]字段升序排列),我们的需求是截取2015-07-31号的数据,以备后期的数据分析使用(整个数据集的时间跨度为2008-01-01到2016-01-07)。如果在DATA步中使用WHERE语句截取以上的数据集,可能至少需要1个小时;而使用这个简易的SAS宏程序,一般在5分钟之内即可完成任务。但为什么能够取得如此显著的提速呢?主要基于以下两点理由:
1、相对于WHERE语句采用的线性搜索,其时间复杂度为θ(N);而二分法的时间复杂度只为θ(〖log〗_2 N)。例如,在具有10亿观测数的数据集中根据条件定位一条记录,二分法在最坏的情况下也只需要大约30次比较操作;而线性搜索在最坏的情况下却需要10亿次比较(性能差异就是如此明显)。一般而言,数据集的观测数(N)越多,二分法的优势就越明显。但特别需要注意的是:对于二分法而言,要求必须预先对数据集的条件字段进行排序!换言之,二分法不能处理没经过排序的数据集。
2、利用DATA步中的FIRSTOBS和OBS语句(需要组合使用),获取大型数据集中的任意一条记录,所需的时间成本基本上可以完全忽略(这类似于RAM随机访问模式,而非耗时的顺序访问模式)。具体的使用方式,可参见下面的SAS宏程序;或者参见图书《SAS编程与数据挖掘商业案例》(作者:姚志勇)中给出的具体原因解释和实践。
与经典二分法不同,这里的宏程序所面对的是略微不同的需求场景:所要搜索的观测可能不唯一(尤其是在大数据集中存在着大量满足搜索条件的观测),需要找出满足搜索条件的观测范围(即开始节点和结束节点);而经典二分法一般只要求返回一条满足搜索条件的观测即可。虽然the deferred detection algorithm也可以近似地处理以上的需求场景;但由于研究较少,本博客将不予讨论。在此,先给出经典二分法的Python极简易版本代码(以对比冗繁的SAS代码):
基于递归的经典二分法Python代码:
基于循环的经典二分法Python代码:
不同于以上简洁的Python代码,SAS宏程序要显得冗余许多(但能够处理更一般的情况),其具体的SAS代码如下所示:
/* ******* ******* ******* ******* ******* ******* ******* *
* ******* 满足特定格式数据的定位截取程序 *******
* 执行前提条件:数据集dataset已按key_col列升序排列
* DESIGN BY: HXC
* MODIFY BY: DQQ-077
* VERSION: 29JAN2016
* ******* ******* ******* ******* ******* ******* ******* */
options compress=yes mprint;
%macro sub_dataset(dataset= /* 输入数据集名称 */
, out= /* 输出数据集名称 */
, start= /* 截取开始节点 */
, end= /* 截取结束节点(满足条件:end >= start)*/
, key_col= /* 数据集dataset已按key_col列升序排列 */
, keep_cols=0 /*数据集读取字段,0表示读取所有字段 */
);
/* 获取数据集总观测数n */
data _null_;
set &dataset. nobs=n;
call symput("n", n);
stop;
run;
/* 基于二分法寻找start的最早位置 */
%let range_start = 1;
%let range_end = &n.;
%let pos_start = 0;
%do %while (&range_start. <= &range_end.);
%let range_middle = %eval(&range_start. + (&range_end. - &range_start.) / 2);
data _null_;
set &dataset.(firstobs=&range_middle. obs=&range_middle.);
call symput("range_middle_key", &key_col.);
stop;
run;
%if &range_middle_key. > &start. %then %do;
%let range_end = %eval(&range_middle. - 1);
%end;
%else %if &range_middle_key. < &start. %then %do;
%let range_start = %eval(&range_middle. + 1);
%end;
%else %do;
data _null_;
set &dataset.(firstobs=&range_start. obs=&range_start.);
call symput("range_start_key", &key_col.);
stop;
run;
%if &range_start_key. = &start. %then %do;
%let pos_start = &range_start.;
%let range_end = %eval(&range_start. - 1);
%end;
%else %do;
%let range_end = &range_middle.;
%end;
%end;
%end;
/* 基于二分法寻找end的最后位置 */
%let range_start = 1;
%let range_end = &n.;
%let pos_end = 0;
%do %while (&range_start. <= &range_end.);
%let range_middle = %eval(&range_start. + (&range_end. - &range_start.) / 2);
data _null_;
set &dataset.(firstobs=&range_middle. obs=&range_middle.);
call symput("range_middle_key", &key_col.);
stop;
run;
%if &range_middle_key. > &end. %then %do;
%let range_end = %eval(&range_middle. - 1);
%end;
%else %if &range_middle_key. < &end. %then %do;
%let range_start = %eval(&range_middle. + 1);
%end;
%else %do;
data _null_;
set &dataset.(firstobs=&range_end. obs=&range_end.);
call symput("range_end_key", &key_col.);
stop;
run;
%if &range_end_key. = &end. %then %do;
%let pos_end = &range_end.;
%let range_end = %eval(&range_start. - 1);
%end;
%else %do;
%if (&range_end. = %eval(&range_middle + 1)) %then %do;
%let pos_end = &range_middle.;
%let range_end = %eval(&range_start. - 1);
%end;
%else %do;
%let range_start = &range_middle.;
%end;
%end;
%end;
%end;
/* 截取满足条件的数据 */
%put pos_start=&pos_start.;
%put pos_end=&pos_end.;
%if (&pos_start. = 0) or (&pos_end. = 0) %then %do;
%put "!!!ERROR!!!error!!!ERROR!!!";
%end;
%else %do;
%if &keep_cols. = 0 %then %do;
data &out.;
set &dataset.(firstobs=&pos_start. obs=&pos_end.);
run;
%end;
%else %do;
data &out.;
set &dataset.(keep=&keep_cols. firstobs=&pos_start. obs=&pos_end.);
run;
%end;
%end;
%mend sub_dataset;有趣的是:以上的宏程序可以看做是对经典二分法的直接扩充;其整体的时间复杂度依然为θ(log2(N))。以上的SAS宏程序对于特定格式的数据集进行定位、截取操作是非常有效的。这也再次在实践上验证了:算法设计的美妙与意义(即通过时间复杂性理论指导算法设计)。
前路漫漫,上下而求索之!
博客相关信息:
SAS宏程序设计:HXC,修改、规范化:DQQ;
博客编写:DQQ,审阅:GJ、HXC,修改:GJ。
如有任何疑问或交流,欢迎联系:DQQ ( duanqq@jointstarc.com )。本博客所涉及到的所有SAS/Python源程序、以及博客的pdf/word版本,都可通过E-mail联系获取(FREE! JUST FOR FUN!)。
[注]: SAS是美国SAS公司的商业产品和商标;Python为有趣的开源编程语言。
参考资料:
[1]. https://en.wikipedia.org/wiki/Binary_search_algorithm
[2]. http://www.mathmeth.com/wf/files/wf2xx/wf214.pdf
[3]. http://www.codecodex.com/wiki/Binary_search
[4]. http://www.sas.com/en_us/software/enterprise-guide.html
[5]. https://www.python.org/
[6]. http://item.jd.com/1060284.html

相关文章推荐
- 《Android开发艺术探索》读书笔记 (1) 第1章 Activity的生命周期和启动模式
- dosbox更新加载的文件夹
- 浅析Google Guava中concurrent下的Monitor和Future特性
- (一三五)第十二章编程练习
- 【NYOJ】[113]字符串替换
- 《暗时间》读书笔记(一)
- Nginx配置
- 寄语我的Web 生涯
- epp3 for php5.3之配置Xdebug
- 【NYOJ】[111]分数加减法
- Unity5 GI与PBS渲染从用法到着色代码
- (一三四)第十二章复习题
- BZOJ4068 : [Ctsc2015]app
- ubuntu 安装nginx
- (一三三)队列模拟
- android和javascript之间相互通信实例分析
- swirch语句的应用
- 浅析手机抓包方法实践
- android和javascript之间相互通信实例分析
- (一三二)类的三种常见技术