ArrayList源码解析
2016-01-28 00:46
260 查看
ok,在我们写程序的时候常常要对大量的对象进行管理,比如查询,遍历,修改等。jdk为我们提供的容器位于java.util包,也是我们平时用的最多的包之一。
但是为什么不用数组(其实也不是不用,只是不直接用)呢,因为数组的长度需要提前确定,而且不能改变大小,用起来手脚受限嘛。
下面步入正题,首先我们想,一个对象管理容器需要哪些功能?增加,删除,修改,查询(crud对不对?)还有呢?遍历,容量,是否包含某个元素。。。
功能是有了,如果让你自己实现一个这样的容器该怎么实现呢?
我们看看ArrayList是怎么实现这些功能的。
1.定义
首先先来看下顶级接口Collection的定义,
然后是接口List的定义,
再看下ArrayList的定义,
可以看出ArrayList继承AbstractList(这是一个抽象类,对一些基础的list操作进行封装),实现List,RandomAccess,Cloneable,Serializable几个接口,RandomAccess是一个标记接口,用来表明其支持快速随机访问。
2.底层存储
顾名思义哈,ArrayList就是用数组实现的List容器,既然是用数组实现,当然底层用数组来保存数据啦。。。
可以看到用一个Object数组来存储数据,用一个int值来计数,记录当前容器的数据大小。
另外,细心的人会发现elementData数组是使用transient修饰的,关于transient关键字的作用简单说就是java自带默认机制进行序列化的时候,被其修饰的属性不需要维持。
会不会产生一点疑问?elementData不需要维持,那么怎么进行反序列化,又怎么保证序列化和反序列化数据的正确性?难道不需要存储?用大腿想一下那当然是不可以的嘛,既然需要存储,它是怎么实现的呢?注意上面红色加粗的地方,默认序列化机制,嗯哼想明白了ArrayList一定是使用了自定义的序列化方式,到底是不是这样的呢?看下面两个方法:
[align=left] [/align]
英语注释很详细,也很容易读懂,就不进行翻译了。那么想一下为什么要这样设计呢,岂不是很麻烦。下面简单进行解释下:
elementData 是一个数据存储数组,而数组是定长的,它会初始化一个容量,等容量不足时再扩充容量(扩容方式为数据拷贝,后面会详细解释),再通俗一点说就是比如elementData 的长度是10,而里面只保存了3个对象,那么数组中其余的7个元素(null)是没有意义的,所以也就不需要保存,以节省序列化后的内存容量,好了到这里就明白了这样设计的初衷和好处,顺便好像也明白了长度单独用一个int变量保存,而不是直接使用elementData.length的原因。
[align=left] [/align]
[align=left]3.构造方法[/align]
[align=left] [/align]
构造方法看完了,想一下指定容量的构造方法的意义,既然默认为10就可以那么为什么还要提供一个可以指定容量大小的构造方法呢?在这里说好像有点太早,那就卖个关子,下面再说。。。
4.增加
[align=left] [/align]
[align=left]5.删除[/align]
PS:看到了这个方法,便可jdk源码有些地方写的也不是那么精巧,比如这里remove时将数组越界检查封装成了一个单独方法,可是往前翻一下add方法中的数组越界就没有进行封装,需要检查的时候都是写一遍一样的代码,why啊。。。
增加和删除方法到这里就解释完了,代码是很简单,主要需要特别关心的就两个地方:1.数组扩容,2.数组复制,这两个操作都是极费效率的,最惨的情况下(添加到list第一个位置,删除list最后一个元素或删除list第一个索引位置的元素)时间复杂度可达O(n)。
还记得上面那个坑吗(为什么提供一个可以指定容量大小的构造方法 )?看到这里是不是有点明白了呢,简单解释下:如果数组初试容量过小,假设默认的10个大小,而我们使用ArrayList的主要操作时增加元素,不断的增加,一直增加,不停的增加,会出现上面后果?那就是数组容量不断的受挑衅,数组需要不断的进行扩容,扩容的过程就是数组拷贝System.arraycopy的过程,每一次扩容就会开辟一块新的内存空间和数据的复制移动,这样势必对性能造成影响。那么在这种以写为主(写会扩容,删不会缩容)场景下,提前预知性的设置一个大容量,便可减少扩容的次数,提高了性能。
图1.
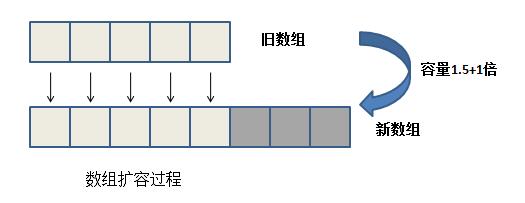
[align=left]图2.[/align]

[align=left] [/align]
上面两张图分别是数组扩容和数组复制的过程,需要注意的是,数组扩容伴随着开辟新建的内存空间以创建新数组然后进行数据复制,而数组复制不需要开辟新内存空间,只需将数据进行复制。
上面讲增加元素可能会进行扩容,而删除元素却不会进行缩容,如果在已删除为主的场景下使用list,一直不停的删除而很少进行增加,那么会出现什么情况?再或者数组进行一次大扩容后,我们后续只使用了几个空间,会出现上面情况?当然是空间浪费啦啦啦,怎么办呢?
[align=left] [/align]
[align=left]6.更新 [/align]
[align=left] [/align]
[align=left]7.查找[/align]
由于ArrayList使用数组实现,更新和查找直接基于下标操作,变得十分简单。
8.是否包含
[align=left]contains主要是检查indexOf,也就是元素在list中出现的索引位置也就是数组下标,再看indexOf和lastIndexOf代码是不是很熟悉,没错,和public booleanremove(Object o) 的代码一样,都是元素null判断,都是循环比较,不多说了。。。但是要知道,最差的情况(要找的元素是最后一个)也是很惨的。。。[/align]
[align=left]9.容量判断[/align]
由于使用了size进行计数,发现list大小获取和判断真的好容易。。。
好了,至此ArrayList的分析和注释就基本完成了。什么还差些什么?对,modCount 是干什么的,怎么到处都在操作这个变量,还有遍历呢,为啥不讲?由于iterator遍历相对比较复杂,而且iterator 是GoF经典设计模式比较重要的一个,之后会对iterator单独分析,这里就不啰嗦了。。。
ArrayList,完!
但是为什么不用数组(其实也不是不用,只是不直接用)呢,因为数组的长度需要提前确定,而且不能改变大小,用起来手脚受限嘛。
下面步入正题,首先我们想,一个对象管理容器需要哪些功能?增加,删除,修改,查询(crud对不对?)还有呢?遍历,容量,是否包含某个元素。。。
功能是有了,如果让你自己实现一个这样的容器该怎么实现呢?
我们看看ArrayList是怎么实现这些功能的。
1.定义
首先先来看下顶级接口Collection的定义,
2.底层存储
顾名思义哈,ArrayList就是用数组实现的List容器,既然是用数组实现,当然底层用数组来保存数据啦。。。
另外,细心的人会发现elementData数组是使用transient修饰的,关于transient关键字的作用简单说就是java自带默认机制进行序列化的时候,被其修饰的属性不需要维持。
会不会产生一点疑问?elementData不需要维持,那么怎么进行反序列化,又怎么保证序列化和反序列化数据的正确性?难道不需要存储?用大腿想一下那当然是不可以的嘛,既然需要存储,它是怎么实现的呢?注意上面红色加粗的地方,默认序列化机制,嗯哼想明白了ArrayList一定是使用了自定义的序列化方式,到底是不是这样的呢?看下面两个方法:
[align=left] [/align]
elementData 是一个数据存储数组,而数组是定长的,它会初始化一个容量,等容量不足时再扩充容量(扩容方式为数据拷贝,后面会详细解释),再通俗一点说就是比如elementData 的长度是10,而里面只保存了3个对象,那么数组中其余的7个元素(null)是没有意义的,所以也就不需要保存,以节省序列化后的内存容量,好了到这里就明白了这样设计的初衷和好处,顺便好像也明白了长度单独用一个int变量保存,而不是直接使用elementData.length的原因。
[align=left] [/align]
[align=left]3.构造方法[/align]
构造方法看完了,想一下指定容量的构造方法的意义,既然默认为10就可以那么为什么还要提供一个可以指定容量大小的构造方法呢?在这里说好像有点太早,那就卖个关子,下面再说。。。
4.增加
[align=left]5.删除[/align]
增加和删除方法到这里就解释完了,代码是很简单,主要需要特别关心的就两个地方:1.数组扩容,2.数组复制,这两个操作都是极费效率的,最惨的情况下(添加到list第一个位置,删除list最后一个元素或删除list第一个索引位置的元素)时间复杂度可达O(n)。
还记得上面那个坑吗(为什么提供一个可以指定容量大小的构造方法 )?看到这里是不是有点明白了呢,简单解释下:如果数组初试容量过小,假设默认的10个大小,而我们使用ArrayList的主要操作时增加元素,不断的增加,一直增加,不停的增加,会出现上面后果?那就是数组容量不断的受挑衅,数组需要不断的进行扩容,扩容的过程就是数组拷贝System.arraycopy的过程,每一次扩容就会开辟一块新的内存空间和数据的复制移动,这样势必对性能造成影响。那么在这种以写为主(写会扩容,删不会缩容)场景下,提前预知性的设置一个大容量,便可减少扩容的次数,提高了性能。
图1.
[align=left]图2.[/align]
[align=left] [/align]
上面两张图分别是数组扩容和数组复制的过程,需要注意的是,数组扩容伴随着开辟新建的内存空间以创建新数组然后进行数据复制,而数组复制不需要开辟新内存空间,只需将数据进行复制。
上面讲增加元素可能会进行扩容,而删除元素却不会进行缩容,如果在已删除为主的场景下使用list,一直不停的删除而很少进行增加,那么会出现什么情况?再或者数组进行一次大扩容后,我们后续只使用了几个空间,会出现上面情况?当然是空间浪费啦啦啦,怎么办呢?
[align=left]6.更新 [/align]
[align=left]7.查找[/align]
8.是否包含
[align=left]9.容量判断[/align]
好了,至此ArrayList的分析和注释就基本完成了。什么还差些什么?对,modCount 是干什么的,怎么到处都在操作这个变量,还有遍历呢,为啥不讲?由于iterator遍历相对比较复杂,而且iterator 是GoF经典设计模式比较重要的一个,之后会对iterator单独分析,这里就不啰嗦了。。。
ArrayList,完!

相关文章推荐
- 基于物品的协同过滤中,余弦相似度、皮尔森系数、修正余弦相似度三者的区别
- HTTP返回码中301与302的区别(转)
- HDU 2074 叠筐
- 用JS将指定时间转化成用户当地时区的时间
- iOS图片的伪裁剪(改变图片的像素值)
- 关于Javascript中的复制
- HDU 2076 夹角有多大
- sprintf和sscanf
- HDU 2073 无限的路
- JavaScript contains
- hdu 5606 tree(并查集)
- mongodb中最为简单的一种安装方法
- 介绍在Swift2面向协议编程(译文)
- 关于正则
- 汇聚点滴精彩
- SQL Server ->> 时间函数: EOMONTH, DATEFROMPARTS, TIMEFROMPARTS, DATETIMEFROMPARTS, DATETIMEOFFSETFROMPARTS
- Game of Sum(动态规划)
- Could not open file ..\output\core_cm3.o: No such file or directory
- Mac 创建.txt文件
- [工作中的设计模式]原型模式prototype