Linux运维 第三阶段 (十九) varnish(1)
2016-01-27 16:47
344 查看
Linux运维 第三阶段 (十九) varnish
一、相关概念:
http/1.0-->http/1.1(重大改进:对缓存功能实现了更精细化的设计)
RFC(request file comment,每一种协议都有请求注解文档,讲协议规范)
http页面由众多的web object组成,有些是静态,有些是通过程序执行后生成的;为加速web的访问,browser中引入了缓存机制,能将访问的静态内容或可缓存的动态内容缓存到本地,而后client再次到原始server上请求之前相同的内容时,如果原始server上的内容没发生改变,就直接使用本地已缓存的数据,而非从原始server上再次下载,这整个过程是如何完成的,http是如何支持缓存机制的(server上的缓存,并非所有内容都能缓存,如登录时的账号密码、向用户返回的cookie,缓存有失效时间)
缓存的类型:
public cache(如nginx,varnish)
private cache(用户browser的本地缓存,一般用户本地的缓存是安全的,但若这个电脑是公共部门的,很多人使用,相对来说也不安全)
一般能缓存的前提是原始server上的内容没发生改变的,client怎么知道他请求的内容在自己本地缓存中有没失效,从而不用去原始server上获取数据,解决方案:
(1)服务器在第一次响应用户的请求时,在http首部中明确告诉client此资源可以缓存的有效时长为10min,使用expires指明过期时间,如Expires: Fri , 12 May 2006 18:53:33 GMT;
(2)server将数据响应给client时没设置缓存期限,但client觉得这是个静态内容可以缓存(client自己设置了一些缓存策略,如只要是静态内容我就缓存),缓存下来之后并不知道远程server中是否改变,当再次请求之前请求的内容时,告诉server我这存的有一份它的上一次修改时间是什么时候,server一对比发现同一对象的修改时间一致,由此可知server上的内容没改变,于是server给client响应码304(Not Modified),告诉client此前内容没改变你可以继续使用,于是client的browser直接整合本地缓存的资源得以显示
以上是基于时间来实现缓存机制控制的(http/1.0的缓存机制是靠prog来标记能否缓存,并使用Expires定义某资源到什么时候过期);http/1.1 对缓存机制引入了很多首部,有些首部专用于client,有些首部专用于server,让双方基于某种功能进行协商,判定缓存对象是否能进一步使用的机制)
缓存相关的http首部:
(1)Expires(绝对时间计时法,绝对日期时间,GMT格式,如Expires: Fri , 12 May 2006 18:53:33 GMT,它返回给client的时间是明确的时间,client的browser缓存了这个资源后,若再次发起请求同样内容时,只要在这个时间内就不去server请求了直接从本地取,Expires的缺陷(若client和server上的时间不一致就无法比较了),这种机制在http/1.0上常用,而在http/1.1上使用时长来定义max-age)
(2)cache-control中的max-age(max-age在http/1.1中使用,用于定义时长,明确告诉client某个资源可缓存多长时间,从server发送这个资源开始倒计时,只要倒计时结束,缓存资源立即失效,如Cache-Control:max-age=600)
注:如果既指定Expires又在cache-control中指定max-age,那Expires的设定将被忽略
注:cache-control是http中重要的首部,用于定义所有的缓存机制都必须遵循缓存指示,无论时间有无过期或有没有给最长缓存时间都要接受cache-control的控制,就算某个资源定义可缓存两天,但同时又使用了cache-control指令告诉你不能进行缓存,那结果就是不能缓存,指令包括有:public、private、no-cache、no-store、max-age、s-maxage、must-reval-idate
public(放在public cache上,所有人都能获取,不涉及隐私泄露)
private(只能缓存在用户的私有缓存区域,像nginx、varnish这样的public cache server是不能缓存的)
no-cache(表示可以缓存,但每次都要向server发起原始资源验证,没有标记no-cache时只要在过期时间内,直接从本地获取不用向server验证这个资源能否用,而标记了no-cache不论在不在过期时间内都要向server验证)
s-maxage(主要控制私有缓存的过期期限)
(3)Etag(响应首部,某些站点,数据变化频率很高,如client在1s里发起好几次请求index.html这个资源(Expires: Fri , 12 May2006 18:53:33 GMT),但在server上1s内更新了好几次页面(主页动态生成),对于这个对象client和server时间的比较结果还是之前的时间,但实际server上的资源已经改变了,所以时间戳这种方法过于粗糙,这种按秒计时不足以描述页面文件的变化频率,有可能让已失效的缓存继续使用,因此引入Etag,extended tag扩展标记,给页面定义版本号(版本号是随机生成的,每次生成一个页面都会自动加版本号),Etag是个响应首部,用于在响应报文中为某web资源定义版本标识符,这样client过来验证不是基于时间戳而是对比Etag,就算更新频率在秒级以下也能验证资源是否发生改变)
注:(1)(2)都是绝对判定法,http/1.1引入条件判断,每次验证资源时是向server发起询问条件,如Last-Modified、If-Modified-Since
(4)Last-Modified(响应首部,某资源在server上最后修改的时间,当client第一次请求某资源时,server返回状态200,内容是client请求的内容,同时有Last-Modified属性标记此文件在server上最后被修改的时间,如Last-Modified : Fri , 12 May 2006 18:53:33 GMT)
(5)If-Modified-Since(条件式请求首部,当client第二次请求相同的内容时询问server此对象Last-Modified是否发生了改变,若没改变server响应给client304(Not Modified),若改变了则响应改变的内容与第一次请求类似,从而保证不向client重复发出资源,也保证当server有变化时client能得到最新的资源)
(6)If-None-Match(条件式请求首部,这是个否定请求,clinet第二次请求相同内容时会询问server之前发的某个资源的Etag是否不匹配,server若回答是则不匹配,响应新资源,若server回答否则client使用之前的缓存)
注:If-Modified-Since与Last-Modified有关,If-None-Match与Etag有关,这整个过程:
client请求一个页面A;
server返回页面A,并给A加上Last-Modified、Etag;
client展示页面A,并将页面和Last-Modified、Etag一同缓存;
client再次请求页面A,将Last-Modified、Etag一同传给server(在首部使用If-Modified-Since、If-None-Match分别询问Last-Modified、Etag是否修改);
server检查Last-Modified、Etag判断出是否修改,若未修改则响应304和一个空的响应体
(7)Vary(响应首部,原始server根据请求来源的不同响应不同的首部,Vary通知缓存机制client获取页面是如何得到页面的,常用的有:Vary:Accept-Encoding,client若支持压缩功能在请求时将请求报文压缩,那server在响应时也使用压缩返回,Vary根据client的编码机制(文本或gzip压缩或deflate压缩)server采用相应的机制返回)
(8)Age(缓存server可发送一个额外的响应首部,用于指定响应的有效期限,browser通常根据此首部决定内容的缓存时长,如果响应报文首部还使用了max-age指令,那缓存的有效时长为max-age减去Age的结果)
假设我们的reverse proxy上提供缓存,后端是RS(原始server),client向reverse proxy请求某页面,reverse proxy中有该页面的缓存则直接响应给client(client于是在本地缓存),若reverse proxy中没该页面的缓存,则reverse proxy向原始server发起请求,原始server响应资源给reverse proxy,同时一并给一个首部,如Cache-Control:max-age=600,reverse proxy将资源缓存下来在600s内都有效,reverse proxy于是重新构建首部并响应给client(reverse proxy构建首部时可以自定义告诉client什么时候过期,如告诉client可以缓存1年,也可告诉client缓存1min),假设reverse proxy给client的过期时长是1min,当同一client再次请求同样内容时(若在缓存过期时间内(1min内)则从本地缓存中直接取;若过了过期时间(1min)client不会立即清除缓存,而是使用条件式请求首部请求,reverse proxy比较两次时间,若时间一样则向client返回304,reverse proxy于是再给client一个缓存过期时间(1min),所以就算过了过期时间也不一定从reverse proxy上重复获取数据;若是强制刷新ctrl+F5则仍会到reverse proxy上请求)
若client在第11min时向reverse proxy请求同一页面,reverse proxy发现本地缓存已失效(reverse proxy不会使用已失效内容响应的),它向原始server发起条件式请求(If-Modified-Since、If-None-Match),若原始server发现没修改则返回304(Not Modified),这样reverse proxy的本地缓存时间就更新了,于是使用本地缓存响应给client
举例:
第一次请求时:
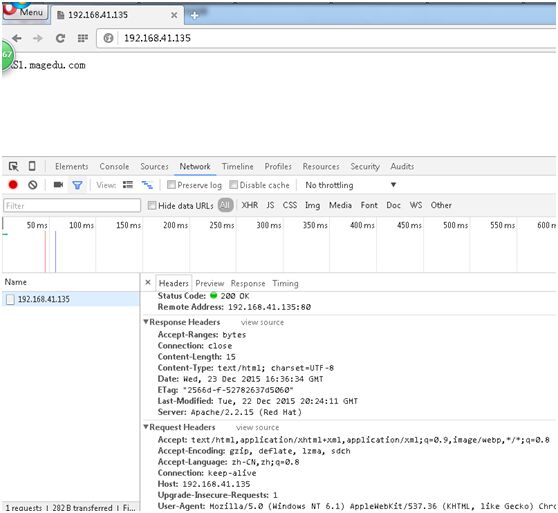
再次刷新后:
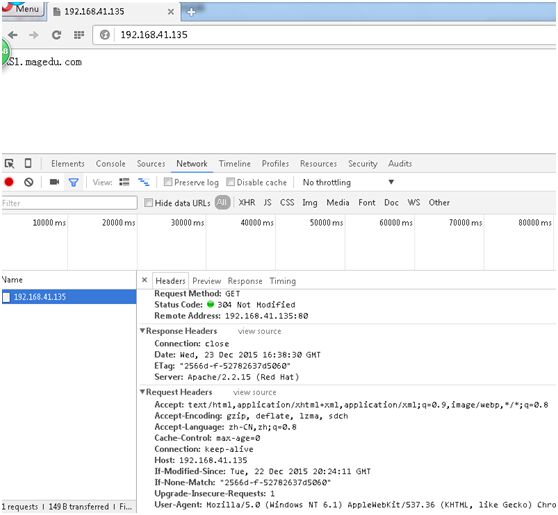
cache server并不是缓存任意数据(不允许缓存某些数据),如不能缓存用户的cookie信息,如果用户请求的内容中有变化的cookie信息的话,缓存是命中不了的,缓存中是key:value,若key中包含经常变化的内容,命中率是很低的,很多时候缓存时都把cookie信息去掉,以提高命中率;不能缓存某些动态生成的资源,如表单中填入的账号密码;若请求方法是PUT或POST写操作,也不能缓存,一般缓存的都是GET操作的数据(就算是GET操作若包含用户的认证授权类信息也不能缓存)
可在cache server上自定义缓存策略(把某些资源根据我们自己的理解从原始server上剥离出来自己定义这些资源的缓存时间),如cache server到原始server上请求数据,若请求的是站点的LOGO图片,虽原始server告诉cache server可缓存10min,但cache server(管理者)觉得该内容是静态的而且很长时间都不会变,于是cache server响应时告诉client可缓存半年,client在自己本地私有缓存中保存的内容越多,那向server发起请求的或获取的数据就越少,资源发送少了,带宽占用率就小了,client从本地缓存直接拿数据会很快,这样用户体验度就好
cache server放到离client越近越好(最好放在家门口),尽量将资源丢到用户的缓存中,我们电脑上或手机上使用时间长了会缓存一些数据,这样使得上网速度更快并节省流量,某些软件会提示清理垃圾,若清理了下次请求将占用带宽重新获取
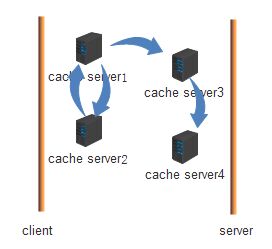
缓存扩展结构:CDN(cache delivery network,内容分发网络),如图:
client到server这之间可定义N层缓存(n个cache server,cache server之间是分层次的),client请求到cache server1,1号发现自己没有要响应的内容时它不会去找原始server,它会先找它的兄弟服务器(cache server2)2若没有再去找它的父cache server3,3没有找它的父cache server4,父cache server中没有,由父缓存找原始server(1和2是兄弟服务器(sibling),3是1的父(parent),4是3的父),这些cache server之间通过内容缓存协议且能共享缓存对象共同组成的网络叫CDN,由此client请求时在中间这个网络上就可取得所有内容,同时这些cache server可定义一些策略,如定期到原始server上获取数据无论client有无请求
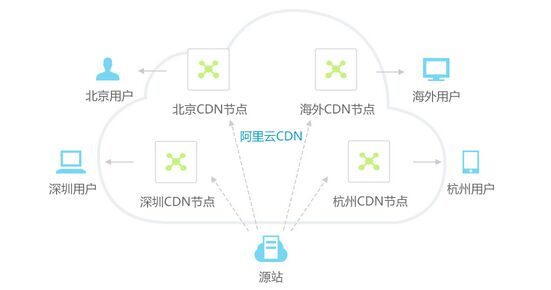
为使用户体验好同时又减轻server压力使用CDN,如下图四个区域组成的CDN
未用CDN前,DNS解析:www.magedu.com in A 1.1.1.1
使用CDN,DNS要解析成别名,指向cache server上的某一个,如指向杭州CDN节点(www.magedu.com in CNAME hz.cdn.com),这样杭州用户访问会很快,其它区域的用户访问还是很慢,用智能DNS解决(根据client来源判定它属于哪个区域网络,于是DNS解析时不是四个都返回,而是仅返回离它最近最快的那个cache server的域名)
智能DNS+CDN这才是真正意义的CDN,当client请求时由该区域的CDN节点响应内容,若该节点没相应内容,它不去找源站而是找离它近的节点,兄弟服务器和父服务器都没有才找源站
这些cache server能根据内容缓存协议来实现缓存对象共享,高级CDN还能实现内容路由(某个cache server上没有内容时自动找有内容的cache server),使得尽可能不去找原始server,这并不能完全避免找原始server(如动态内容),就算缓存的内容是静态的,也不会把整站的内容都缓存上去,只能缓存一部分,若缓存策略定义的好,将站点的热区数据都拉到cache server上实现尽可能多的在cache server上缓存
CDN通常是按流量收费,视频站点和图片站点都要用CDN否则流量大了很容易垮掉
对于中小型电子商务站点可自建CDN,前提要使用智能DNS(可自建智能DNS,也可使用公共的智能DNS server如dnspod)
注:dnspod在防DDOS方面很强,每秒解析达到数百万,还可达到秒级的更新,更新后随时生效,还有监控原始server的功能,原始server还可通过它做LB完成health check
DNS本身也要分区域(如北方电信、南方联通等),访问网站不只是获取网页的时间还有DNS解析返回,再请求资源,若DNS很慢也影响用户体验
bind dlz+{mysql,pgsql,oracke,DB4},http://bind-dlz.sourceforge.net/,将用户的资源放到数据库中会很慢,如果不是做公共dns server仅为自己公司解析可放在file中,dns启动时会直接加载至内存中;一般使用bind即可(bind本身就提供了智能解析(view))
注:DB4,基于hash编码的数据库
varnish(https://www.varnish-cache.org/):
互联网早期的cache server是squid(乌贼,章鱼,八爪鱼)
varnish本身是reverse proxy server同时又提供cache功能,配置简单、接口简单、监控接口丰富,由于采用新架构设计,之后扩展要比squid容易,功能与nginx近似,但varnish在创建连接、维持连接的能力比nginx差远了,通常使用nginx+varnish(nginx处理连接,varnish专门负责缓存),也可nginx+squid(squid功能很强大,支持正向代理、反向代理、ACL、支持内容分发协议,特性非常丰富,配置复杂)
varnish尽可能利用时下最新的技术,时下最好的软件设计结构,时下安全体系的诸多经验,站在前人的基础上设计的,但squid也宝刀未老,早期淘宝在前端的cache server就使用100多台server创建的squid cache cluster,优化后的命中率达到97%(纯静态内容),做到这地步要对站点的静态资源做好筛选(要将哪些内容放到cache server上)
squid VS varnish(同httpd VS nginx)
varnish architecture(与nginx类似,是master/slave架构):
主进程(管理进程management,负责配置文件分析、装载新配置文件、启动子进程;Management进程主要实现应用新的配置(若检测到VCL配置文件有语法错误则拒绝编译,避免子进程加载错误配置导致缓存崩溃)、编译VCL、监控varnish、初始化varnish以及提供一个命令行接口等。Management进程会每隔几秒钟探测一下Child进程以判断其是否正常运行,如果在指定的时长内未得到Child进程的回应,Management将会重启此Child进程):
CLI interface(通过命令行接口与命令行的控制指令进行交互)
telnet interface(为安全这种方式已很少用,可用专用的client工具varnishadm连到管理进程完成启动停止等)
web interface(GUI接口)
子进程(child|cache进程,child提供服务、发送至后端并响应用户请求;cache缓存管理的进程,缓存清理、缓存有效期限检查等):
command line
storage/hashing(存储缓存,用key定义查找标准,将key放在某个backet中实现O(1)的查找,查找到的内容即是value)
log/stats(varnish的日志不是保存在file中,有磁盘IO,而是在内存中,启动服务时就明确说明用多大空间保存日志,空间占完后将覆盖之前的文件继续使用,一圈圈轮着使用,日志记录有client的请求数、client请求命中数、没命中数、server运行多长时间等;可用工具将日志导出查看,如varnishlog等)
accept(接收用户请求并将请求转至workerthreads上)
backend communication(后端主机通信)
worker threads(一个线程响应多个请求,child进程会为每个会话启动一个worker线程,因此,在高并发的场景中可能会出现数百个worker线程甚至更多)
object expiry(从缓存中清理过期内容)
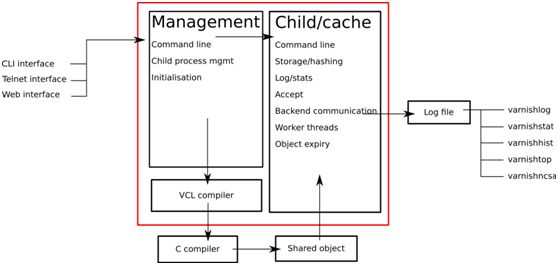
varnish的主进程management只有一个,child进程由多个不同的线程组成,varnish总体连接数在大于5000时性能会下降,一般不会让工作线程接受太多连接,性能有上限,假设有10个varnish server每个平均接受5000个连接,那10个就能接受5W个了,前端nignx已处理一些请求再将多个请求转到varnish server上,这种架构已达到亿级或十亿级PV
VCL(varnish configuration language),底层用C开发,完全兼容C语言,提供编程接口,要写程序提供配置文件,用VCL开发程序时指明varnish怎么工作(哪些内容缓存、哪些内容不缓存、哪些内容不通过缓存来取等),为使VCL开发出的程序更加高效,要将其编译为二进制格式(使用VCL编写好配置文件后,使用gcc编译)
配置文件编译完后生成共享模块,child/cache如何工作就取决于共享模块中的定义,二进制格式的配置文件被子进程child/cache读取,child从后端server取得内容后要缓存在本地,由storage/hashing子模块将缓存内容存下来
VCL工作在varnish的状态引擎state engine上,在varnish内部有多个state engine(同iptables的netfilter框架中的几个接口类似(勾子函数),若某个报文不经过这几个勾子函数将检测不到,所以这几个勾子要放在报文必经的路口,使得报文必须要经过这其中1个或几个勾子,在这些勾子上就能实现管理)
如图:椭圆表示state engine(又叫domain),菱形表示检查机制(条件判断)
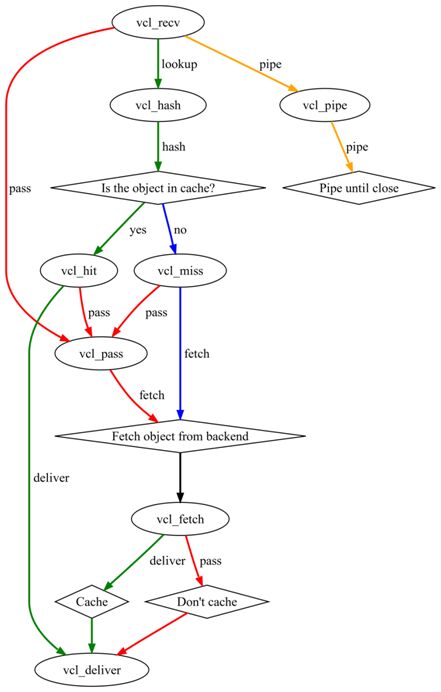
vcl_recv(第一个入口的state engine,请求报文接进来)
vcl_recv-->vcl_pass(例如是动态内容或用户的私有内容直接到后端去取)
vcl_recv-->vcl_hash(根据key来查找本地缓存)
vcl_recv-->vcl_pipe(不对client进行检查或做出任何操作,而是在client和后端server之间建立专用pipe,并直接将数据在二者之间传送;keep-alive连接中后续传送的数据也都通过此管道进行直接传送,并不会出现在任何日志中)
vcl_hit-->vcl_deliver(命中后交给vcl_deliver再投递给client)
vcl_hit-->vcl_pass(在管理的CLI下,命中后将缓存清除)
vcl_pass(可对三个state engine(domain)过来的报文统一处理(vcl_recv、vcl_hit、vcl_miss),统一到一个反向操作上(例如命中后不去找缓存而是找vcl_fetch继而找后端server))
vcl_fetch(到这个domain上就要联系后端server,这个域上会定义一些语句来判定哪些内容缓存哪些不缓存(如auth或cookie有关的字串就不缓存))
路线:
vcl_recv-->vcl_hash-->vcl_hit-->vcl_deliver
vcl_recv-->vcl_hash-->vcl_miss-->vcl_fetch-->vcl_deliver
vcl_recv-->vcl_pass-->vcl_fetch-->vcl_vcl_deliver
每个state engine中定义一堆条件判断(如定义vcl_recv在什么情况下去找vcl_hash,在什么情况下找vcl_pass,例如某些client不允许访问、某些client查找哪些资源、哪些资源不允许缓存等,通过定义各种条件判断指挥着到下一个数据流或state engine)
每个state engine又被叫作domain,每个domain都有可执行的指令(如netfilter上各种链上的规则,每个链所接受的规则是不一样的,处理完成有可能还要经过下个链,有可能直接返回),而对varnish的每个state engine都要走向下一步(除vcl_deliver)
VCL编程,所写的代码,只对当前state engine生效(可理解为函数,函数执行完有返回值),返回的是什么就决定下一步怎么走,若return返回hash就找vcl_hash,若return pass则找vcl_pass,到底返回哪个要做写一大堆的if语句做出判断
以上涉及到编程,程序中策略写的好,缓存命中率就高
VCL语法:
(1)注释://和/*(单选注释);*/(多行注释)
(2)sub $name(定义函数,subroutine子例程)
(3)不支持循环,有内置变量(内置变量应用位置独特,有的变量应用在前半段(请求报文首部),有的变量应用在后半段(响应报文首部))
(4)使用终止语句,没有返回值
(5)域专用(每个state engine定义自己的程序)
(6)操作符(=赋值、==等值比较、~模式匹配、!、&&、||)
VCL的函数不接受参数且没有返回值,因此并非真正意义的函数,这也限定了VCL内部的数据传递只能隐藏在http首部内部进行,VCL的return语句用于将控制权从VCL状态引擎返回给varnish,而非默认函数,这就是VCL只有终止语句没有返回值的原因;同时对于每个域来说,可定义一个或多个终止语句,告诉varnish下一步采取何种操作(如查询缓存或不查询缓存等)
VCL的内置函数:
regsub(str,regex,sub)
regsuball(str,regex,sub)
以上两项实现替换(substituend,用于将regexp匹配到的str替换为sub,相当于nginx的rewrite,而regsuball相当于加了修饰符/g的替换)
ban(expression)
ban_url(regex)
purge
以上三项实现缓存清理,给某个缓存对象设置栅栏,阻止对其使用,先放到禁止列表中再禁止使用,purge仅允许有权限经过认证的管理员使用
hash_data(str)(取得一个字符串的hash值,若这个字符串是缓存中的某个key,则可判定缓存中是否有)
return()(当某个域运行结束时将控制权返回给varnish,并指示下一步的动作,可以返回的指令有:lookup,pass,pipe,hit_for_pass,fetch,deliver,hash等),特定域只能返回特定的指令)
return(restart)(重新运行整个VCL,即从vcl_recv开始进行处理,每一次重启都会增加req.restarts变量中的值,而max_restarts参数则用于限定最大重启次数,例如vcl_recv-->vcl_hash-->vcl_miss-->vcl_pass-->restart-->vcl_recv……,未命中可不让去vcl_fetch,让重启,在vcl_pass中写入regsub(……)将url重写rewrite,再在vcl_recv上跑一遍,有可能就命中了,若写了错误的rewrite将导致死循环,restart判定若超过5次就退出直接向client返回error)
注:vcl_deliver要能在client请求内容不存在时或restart超过5次退出时,返回错误页面,varnish-server要能生成错误响应页(如404,502等)
以上是学习《马哥运维课程》做的笔记。
本文出自 “Linux运维重难点学习笔记” 博客,请务必保留此出处http://jowin.blog.51cto.com/10090021/1739282
一、相关概念:
http/1.0-->http/1.1(重大改进:对缓存功能实现了更精细化的设计)
RFC(request file comment,每一种协议都有请求注解文档,讲协议规范)
http页面由众多的web object组成,有些是静态,有些是通过程序执行后生成的;为加速web的访问,browser中引入了缓存机制,能将访问的静态内容或可缓存的动态内容缓存到本地,而后client再次到原始server上请求之前相同的内容时,如果原始server上的内容没发生改变,就直接使用本地已缓存的数据,而非从原始server上再次下载,这整个过程是如何完成的,http是如何支持缓存机制的(server上的缓存,并非所有内容都能缓存,如登录时的账号密码、向用户返回的cookie,缓存有失效时间)
缓存的类型:
public cache(如nginx,varnish)
private cache(用户browser的本地缓存,一般用户本地的缓存是安全的,但若这个电脑是公共部门的,很多人使用,相对来说也不安全)
一般能缓存的前提是原始server上的内容没发生改变的,client怎么知道他请求的内容在自己本地缓存中有没失效,从而不用去原始server上获取数据,解决方案:
(1)服务器在第一次响应用户的请求时,在http首部中明确告诉client此资源可以缓存的有效时长为10min,使用expires指明过期时间,如Expires: Fri , 12 May 2006 18:53:33 GMT;
(2)server将数据响应给client时没设置缓存期限,但client觉得这是个静态内容可以缓存(client自己设置了一些缓存策略,如只要是静态内容我就缓存),缓存下来之后并不知道远程server中是否改变,当再次请求之前请求的内容时,告诉server我这存的有一份它的上一次修改时间是什么时候,server一对比发现同一对象的修改时间一致,由此可知server上的内容没改变,于是server给client响应码304(Not Modified),告诉client此前内容没改变你可以继续使用,于是client的browser直接整合本地缓存的资源得以显示
以上是基于时间来实现缓存机制控制的(http/1.0的缓存机制是靠prog来标记能否缓存,并使用Expires定义某资源到什么时候过期);http/1.1 对缓存机制引入了很多首部,有些首部专用于client,有些首部专用于server,让双方基于某种功能进行协商,判定缓存对象是否能进一步使用的机制)
缓存相关的http首部:
(1)Expires(绝对时间计时法,绝对日期时间,GMT格式,如Expires: Fri , 12 May 2006 18:53:33 GMT,它返回给client的时间是明确的时间,client的browser缓存了这个资源后,若再次发起请求同样内容时,只要在这个时间内就不去server请求了直接从本地取,Expires的缺陷(若client和server上的时间不一致就无法比较了),这种机制在http/1.0上常用,而在http/1.1上使用时长来定义max-age)
(2)cache-control中的max-age(max-age在http/1.1中使用,用于定义时长,明确告诉client某个资源可缓存多长时间,从server发送这个资源开始倒计时,只要倒计时结束,缓存资源立即失效,如Cache-Control:max-age=600)
注:如果既指定Expires又在cache-control中指定max-age,那Expires的设定将被忽略
注:cache-control是http中重要的首部,用于定义所有的缓存机制都必须遵循缓存指示,无论时间有无过期或有没有给最长缓存时间都要接受cache-control的控制,就算某个资源定义可缓存两天,但同时又使用了cache-control指令告诉你不能进行缓存,那结果就是不能缓存,指令包括有:public、private、no-cache、no-store、max-age、s-maxage、must-reval-idate
public(放在public cache上,所有人都能获取,不涉及隐私泄露)
private(只能缓存在用户的私有缓存区域,像nginx、varnish这样的public cache server是不能缓存的)
no-cache(表示可以缓存,但每次都要向server发起原始资源验证,没有标记no-cache时只要在过期时间内,直接从本地获取不用向server验证这个资源能否用,而标记了no-cache不论在不在过期时间内都要向server验证)
s-maxage(主要控制私有缓存的过期期限)
(3)Etag(响应首部,某些站点,数据变化频率很高,如client在1s里发起好几次请求index.html这个资源(Expires: Fri , 12 May2006 18:53:33 GMT),但在server上1s内更新了好几次页面(主页动态生成),对于这个对象client和server时间的比较结果还是之前的时间,但实际server上的资源已经改变了,所以时间戳这种方法过于粗糙,这种按秒计时不足以描述页面文件的变化频率,有可能让已失效的缓存继续使用,因此引入Etag,extended tag扩展标记,给页面定义版本号(版本号是随机生成的,每次生成一个页面都会自动加版本号),Etag是个响应首部,用于在响应报文中为某web资源定义版本标识符,这样client过来验证不是基于时间戳而是对比Etag,就算更新频率在秒级以下也能验证资源是否发生改变)
注:(1)(2)都是绝对判定法,http/1.1引入条件判断,每次验证资源时是向server发起询问条件,如Last-Modified、If-Modified-Since
(4)Last-Modified(响应首部,某资源在server上最后修改的时间,当client第一次请求某资源时,server返回状态200,内容是client请求的内容,同时有Last-Modified属性标记此文件在server上最后被修改的时间,如Last-Modified : Fri , 12 May 2006 18:53:33 GMT)
(5)If-Modified-Since(条件式请求首部,当client第二次请求相同的内容时询问server此对象Last-Modified是否发生了改变,若没改变server响应给client304(Not Modified),若改变了则响应改变的内容与第一次请求类似,从而保证不向client重复发出资源,也保证当server有变化时client能得到最新的资源)
(6)If-None-Match(条件式请求首部,这是个否定请求,clinet第二次请求相同内容时会询问server之前发的某个资源的Etag是否不匹配,server若回答是则不匹配,响应新资源,若server回答否则client使用之前的缓存)
注:If-Modified-Since与Last-Modified有关,If-None-Match与Etag有关,这整个过程:
client请求一个页面A;
server返回页面A,并给A加上Last-Modified、Etag;
client展示页面A,并将页面和Last-Modified、Etag一同缓存;
client再次请求页面A,将Last-Modified、Etag一同传给server(在首部使用If-Modified-Since、If-None-Match分别询问Last-Modified、Etag是否修改);
server检查Last-Modified、Etag判断出是否修改,若未修改则响应304和一个空的响应体
(7)Vary(响应首部,原始server根据请求来源的不同响应不同的首部,Vary通知缓存机制client获取页面是如何得到页面的,常用的有:Vary:Accept-Encoding,client若支持压缩功能在请求时将请求报文压缩,那server在响应时也使用压缩返回,Vary根据client的编码机制(文本或gzip压缩或deflate压缩)server采用相应的机制返回)
(8)Age(缓存server可发送一个额外的响应首部,用于指定响应的有效期限,browser通常根据此首部决定内容的缓存时长,如果响应报文首部还使用了max-age指令,那缓存的有效时长为max-age减去Age的结果)
假设我们的reverse proxy上提供缓存,后端是RS(原始server),client向reverse proxy请求某页面,reverse proxy中有该页面的缓存则直接响应给client(client于是在本地缓存),若reverse proxy中没该页面的缓存,则reverse proxy向原始server发起请求,原始server响应资源给reverse proxy,同时一并给一个首部,如Cache-Control:max-age=600,reverse proxy将资源缓存下来在600s内都有效,reverse proxy于是重新构建首部并响应给client(reverse proxy构建首部时可以自定义告诉client什么时候过期,如告诉client可以缓存1年,也可告诉client缓存1min),假设reverse proxy给client的过期时长是1min,当同一client再次请求同样内容时(若在缓存过期时间内(1min内)则从本地缓存中直接取;若过了过期时间(1min)client不会立即清除缓存,而是使用条件式请求首部请求,reverse proxy比较两次时间,若时间一样则向client返回304,reverse proxy于是再给client一个缓存过期时间(1min),所以就算过了过期时间也不一定从reverse proxy上重复获取数据;若是强制刷新ctrl+F5则仍会到reverse proxy上请求)
若client在第11min时向reverse proxy请求同一页面,reverse proxy发现本地缓存已失效(reverse proxy不会使用已失效内容响应的),它向原始server发起条件式请求(If-Modified-Since、If-None-Match),若原始server发现没修改则返回304(Not Modified),这样reverse proxy的本地缓存时间就更新了,于是使用本地缓存响应给client
举例:
第一次请求时:
再次刷新后:
cache server并不是缓存任意数据(不允许缓存某些数据),如不能缓存用户的cookie信息,如果用户请求的内容中有变化的cookie信息的话,缓存是命中不了的,缓存中是key:value,若key中包含经常变化的内容,命中率是很低的,很多时候缓存时都把cookie信息去掉,以提高命中率;不能缓存某些动态生成的资源,如表单中填入的账号密码;若请求方法是PUT或POST写操作,也不能缓存,一般缓存的都是GET操作的数据(就算是GET操作若包含用户的认证授权类信息也不能缓存)
可在cache server上自定义缓存策略(把某些资源根据我们自己的理解从原始server上剥离出来自己定义这些资源的缓存时间),如cache server到原始server上请求数据,若请求的是站点的LOGO图片,虽原始server告诉cache server可缓存10min,但cache server(管理者)觉得该内容是静态的而且很长时间都不会变,于是cache server响应时告诉client可缓存半年,client在自己本地私有缓存中保存的内容越多,那向server发起请求的或获取的数据就越少,资源发送少了,带宽占用率就小了,client从本地缓存直接拿数据会很快,这样用户体验度就好
cache server放到离client越近越好(最好放在家门口),尽量将资源丢到用户的缓存中,我们电脑上或手机上使用时间长了会缓存一些数据,这样使得上网速度更快并节省流量,某些软件会提示清理垃圾,若清理了下次请求将占用带宽重新获取
缓存扩展结构:CDN(cache delivery network,内容分发网络),如图:
client到server这之间可定义N层缓存(n个cache server,cache server之间是分层次的),client请求到cache server1,1号发现自己没有要响应的内容时它不会去找原始server,它会先找它的兄弟服务器(cache server2)2若没有再去找它的父cache server3,3没有找它的父cache server4,父cache server中没有,由父缓存找原始server(1和2是兄弟服务器(sibling),3是1的父(parent),4是3的父),这些cache server之间通过内容缓存协议且能共享缓存对象共同组成的网络叫CDN,由此client请求时在中间这个网络上就可取得所有内容,同时这些cache server可定义一些策略,如定期到原始server上获取数据无论client有无请求
为使用户体验好同时又减轻server压力使用CDN,如下图四个区域组成的CDN
未用CDN前,DNS解析:www.magedu.com in A 1.1.1.1
使用CDN,DNS要解析成别名,指向cache server上的某一个,如指向杭州CDN节点(www.magedu.com in CNAME hz.cdn.com),这样杭州用户访问会很快,其它区域的用户访问还是很慢,用智能DNS解决(根据client来源判定它属于哪个区域网络,于是DNS解析时不是四个都返回,而是仅返回离它最近最快的那个cache server的域名)
智能DNS+CDN这才是真正意义的CDN,当client请求时由该区域的CDN节点响应内容,若该节点没相应内容,它不去找源站而是找离它近的节点,兄弟服务器和父服务器都没有才找源站
这些cache server能根据内容缓存协议来实现缓存对象共享,高级CDN还能实现内容路由(某个cache server上没有内容时自动找有内容的cache server),使得尽可能不去找原始server,这并不能完全避免找原始server(如动态内容),就算缓存的内容是静态的,也不会把整站的内容都缓存上去,只能缓存一部分,若缓存策略定义的好,将站点的热区数据都拉到cache server上实现尽可能多的在cache server上缓存
CDN通常是按流量收费,视频站点和图片站点都要用CDN否则流量大了很容易垮掉
对于中小型电子商务站点可自建CDN,前提要使用智能DNS(可自建智能DNS,也可使用公共的智能DNS server如dnspod)
注:dnspod在防DDOS方面很强,每秒解析达到数百万,还可达到秒级的更新,更新后随时生效,还有监控原始server的功能,原始server还可通过它做LB完成health check
DNS本身也要分区域(如北方电信、南方联通等),访问网站不只是获取网页的时间还有DNS解析返回,再请求资源,若DNS很慢也影响用户体验
bind dlz+{mysql,pgsql,oracke,DB4},http://bind-dlz.sourceforge.net/,将用户的资源放到数据库中会很慢,如果不是做公共dns server仅为自己公司解析可放在file中,dns启动时会直接加载至内存中;一般使用bind即可(bind本身就提供了智能解析(view))
注:DB4,基于hash编码的数据库
varnish(https://www.varnish-cache.org/):
互联网早期的cache server是squid(乌贼,章鱼,八爪鱼)
varnish本身是reverse proxy server同时又提供cache功能,配置简单、接口简单、监控接口丰富,由于采用新架构设计,之后扩展要比squid容易,功能与nginx近似,但varnish在创建连接、维持连接的能力比nginx差远了,通常使用nginx+varnish(nginx处理连接,varnish专门负责缓存),也可nginx+squid(squid功能很强大,支持正向代理、反向代理、ACL、支持内容分发协议,特性非常丰富,配置复杂)
varnish尽可能利用时下最新的技术,时下最好的软件设计结构,时下安全体系的诸多经验,站在前人的基础上设计的,但squid也宝刀未老,早期淘宝在前端的cache server就使用100多台server创建的squid cache cluster,优化后的命中率达到97%(纯静态内容),做到这地步要对站点的静态资源做好筛选(要将哪些内容放到cache server上)
squid VS varnish(同httpd VS nginx)
varnish architecture(与nginx类似,是master/slave架构):
主进程(管理进程management,负责配置文件分析、装载新配置文件、启动子进程;Management进程主要实现应用新的配置(若检测到VCL配置文件有语法错误则拒绝编译,避免子进程加载错误配置导致缓存崩溃)、编译VCL、监控varnish、初始化varnish以及提供一个命令行接口等。Management进程会每隔几秒钟探测一下Child进程以判断其是否正常运行,如果在指定的时长内未得到Child进程的回应,Management将会重启此Child进程):
CLI interface(通过命令行接口与命令行的控制指令进行交互)
telnet interface(为安全这种方式已很少用,可用专用的client工具varnishadm连到管理进程完成启动停止等)
web interface(GUI接口)
子进程(child|cache进程,child提供服务、发送至后端并响应用户请求;cache缓存管理的进程,缓存清理、缓存有效期限检查等):
command line
storage/hashing(存储缓存,用key定义查找标准,将key放在某个backet中实现O(1)的查找,查找到的内容即是value)
log/stats(varnish的日志不是保存在file中,有磁盘IO,而是在内存中,启动服务时就明确说明用多大空间保存日志,空间占完后将覆盖之前的文件继续使用,一圈圈轮着使用,日志记录有client的请求数、client请求命中数、没命中数、server运行多长时间等;可用工具将日志导出查看,如varnishlog等)
accept(接收用户请求并将请求转至workerthreads上)
backend communication(后端主机通信)
worker threads(一个线程响应多个请求,child进程会为每个会话启动一个worker线程,因此,在高并发的场景中可能会出现数百个worker线程甚至更多)
object expiry(从缓存中清理过期内容)
varnish的主进程management只有一个,child进程由多个不同的线程组成,varnish总体连接数在大于5000时性能会下降,一般不会让工作线程接受太多连接,性能有上限,假设有10个varnish server每个平均接受5000个连接,那10个就能接受5W个了,前端nignx已处理一些请求再将多个请求转到varnish server上,这种架构已达到亿级或十亿级PV
VCL(varnish configuration language),底层用C开发,完全兼容C语言,提供编程接口,要写程序提供配置文件,用VCL开发程序时指明varnish怎么工作(哪些内容缓存、哪些内容不缓存、哪些内容不通过缓存来取等),为使VCL开发出的程序更加高效,要将其编译为二进制格式(使用VCL编写好配置文件后,使用gcc编译)
配置文件编译完后生成共享模块,child/cache如何工作就取决于共享模块中的定义,二进制格式的配置文件被子进程child/cache读取,child从后端server取得内容后要缓存在本地,由storage/hashing子模块将缓存内容存下来
VCL工作在varnish的状态引擎state engine上,在varnish内部有多个state engine(同iptables的netfilter框架中的几个接口类似(勾子函数),若某个报文不经过这几个勾子函数将检测不到,所以这几个勾子要放在报文必经的路口,使得报文必须要经过这其中1个或几个勾子,在这些勾子上就能实现管理)
如图:椭圆表示state engine(又叫domain),菱形表示检查机制(条件判断)
vcl_recv(第一个入口的state engine,请求报文接进来)
vcl_recv-->vcl_pass(例如是动态内容或用户的私有内容直接到后端去取)
vcl_recv-->vcl_hash(根据key来查找本地缓存)
vcl_recv-->vcl_pipe(不对client进行检查或做出任何操作,而是在client和后端server之间建立专用pipe,并直接将数据在二者之间传送;keep-alive连接中后续传送的数据也都通过此管道进行直接传送,并不会出现在任何日志中)
vcl_hit-->vcl_deliver(命中后交给vcl_deliver再投递给client)
vcl_hit-->vcl_pass(在管理的CLI下,命中后将缓存清除)
vcl_pass(可对三个state engine(domain)过来的报文统一处理(vcl_recv、vcl_hit、vcl_miss),统一到一个反向操作上(例如命中后不去找缓存而是找vcl_fetch继而找后端server))
vcl_fetch(到这个domain上就要联系后端server,这个域上会定义一些语句来判定哪些内容缓存哪些不缓存(如auth或cookie有关的字串就不缓存))
路线:
vcl_recv-->vcl_hash-->vcl_hit-->vcl_deliver
vcl_recv-->vcl_hash-->vcl_miss-->vcl_fetch-->vcl_deliver
vcl_recv-->vcl_pass-->vcl_fetch-->vcl_vcl_deliver
每个state engine中定义一堆条件判断(如定义vcl_recv在什么情况下去找vcl_hash,在什么情况下找vcl_pass,例如某些client不允许访问、某些client查找哪些资源、哪些资源不允许缓存等,通过定义各种条件判断指挥着到下一个数据流或state engine)
每个state engine又被叫作domain,每个domain都有可执行的指令(如netfilter上各种链上的规则,每个链所接受的规则是不一样的,处理完成有可能还要经过下个链,有可能直接返回),而对varnish的每个state engine都要走向下一步(除vcl_deliver)
VCL编程,所写的代码,只对当前state engine生效(可理解为函数,函数执行完有返回值),返回的是什么就决定下一步怎么走,若return返回hash就找vcl_hash,若return pass则找vcl_pass,到底返回哪个要做写一大堆的if语句做出判断
以上涉及到编程,程序中策略写的好,缓存命中率就高
VCL语法:
(1)注释://和/*(单选注释);*/(多行注释)
(2)sub $name(定义函数,subroutine子例程)
(3)不支持循环,有内置变量(内置变量应用位置独特,有的变量应用在前半段(请求报文首部),有的变量应用在后半段(响应报文首部))
(4)使用终止语句,没有返回值
(5)域专用(每个state engine定义自己的程序)
(6)操作符(=赋值、==等值比较、~模式匹配、!、&&、||)
VCL的函数不接受参数且没有返回值,因此并非真正意义的函数,这也限定了VCL内部的数据传递只能隐藏在http首部内部进行,VCL的return语句用于将控制权从VCL状态引擎返回给varnish,而非默认函数,这就是VCL只有终止语句没有返回值的原因;同时对于每个域来说,可定义一个或多个终止语句,告诉varnish下一步采取何种操作(如查询缓存或不查询缓存等)
VCL的内置函数:
regsub(str,regex,sub)
regsuball(str,regex,sub)
以上两项实现替换(substituend,用于将regexp匹配到的str替换为sub,相当于nginx的rewrite,而regsuball相当于加了修饰符/g的替换)
ban(expression)
ban_url(regex)
purge
以上三项实现缓存清理,给某个缓存对象设置栅栏,阻止对其使用,先放到禁止列表中再禁止使用,purge仅允许有权限经过认证的管理员使用
hash_data(str)(取得一个字符串的hash值,若这个字符串是缓存中的某个key,则可判定缓存中是否有)
return()(当某个域运行结束时将控制权返回给varnish,并指示下一步的动作,可以返回的指令有:lookup,pass,pipe,hit_for_pass,fetch,deliver,hash等),特定域只能返回特定的指令)
return(restart)(重新运行整个VCL,即从vcl_recv开始进行处理,每一次重启都会增加req.restarts变量中的值,而max_restarts参数则用于限定最大重启次数,例如vcl_recv-->vcl_hash-->vcl_miss-->vcl_pass-->restart-->vcl_recv……,未命中可不让去vcl_fetch,让重启,在vcl_pass中写入regsub(……)将url重写rewrite,再在vcl_recv上跑一遍,有可能就命中了,若写了错误的rewrite将导致死循环,restart判定若超过5次就退出直接向client返回error)
注:vcl_deliver要能在client请求内容不存在时或restart超过5次退出时,返回错误页面,varnish-server要能生成错误响应页(如404,502等)
以上是学习《马哥运维课程》做的笔记。
本文出自 “Linux运维重难点学习笔记” 博客,请务必保留此出处http://jowin.blog.51cto.com/10090021/1739282

相关文章推荐
- linux实践-lvm
- 什么是EPEL 及 Centos上安装EPEL
- Linux crontab 定时任务详解
- Linux周期性自动发送邮件
- centos(7) 使用yum进行安装lamp环境
- linux 中的rime 输入法 自定义 新世纪五笔输入法
- Linux 常用命令
- linux实现针对文本统计字母出现的次数(所有的可打印的字符)
- Centos6.x系统下安装telnet命令及使用
- linux下查看程序占用多少内存
- Linux 环境下搭建DDNS
- linux发行版和内核的关系
- linux磁盘空间清理
- Linux进程通信 -- 共享内存实战
- linux实践-弱密码导致服务器被黑
- VMware建立一个裸机linux
- Linux Centos 6.6安装Mysql
- linux与windows之间传输文件工具rz上传大文件失败问题解决方案
- linux下ssh上传下载文件到服务器
- linux kernel 从入口到start_kernel 的代码分析