Spark shuffle:hash和sort性能对比
2016-01-26 08:26
701 查看
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于hash的。而在最新的Spark
1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发布》):基于sort的。
在Spark 1.1.0文档是这么说的:
Implementation to use for shuffling data. A hash-based shuffle manager is the default, but starting in Spark 1.1 there is an experimental sort-based shuffle manager that is more memory-efficient in environments with small executors, such as YARN. To use that,
change this value to SORT.
从上面说明可以看出,Spark 1.1版本默认的shuffle是基于hash,不过这个版本引入了基于sort的shuffle,在一些环境下使用该shuffle实现会得到更高效的表现;在这个版本中的Shuffle实现还是处于实验阶段,不过大家可以通过spark.shuffle.manager参数进行使用。
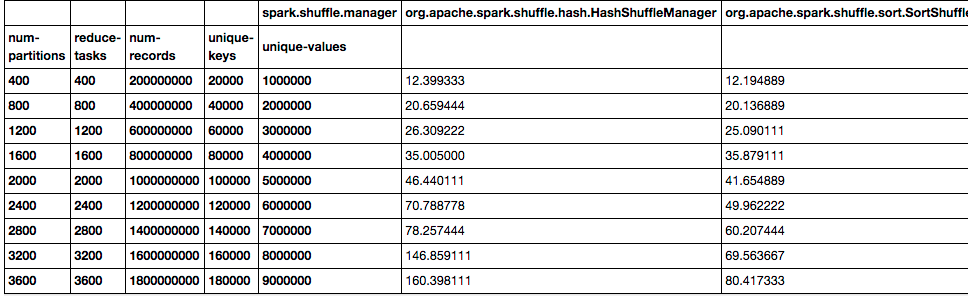
不过随着对基于hash的shuffle实现和基于sort的shuffle实现进行实验对比,如下图所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
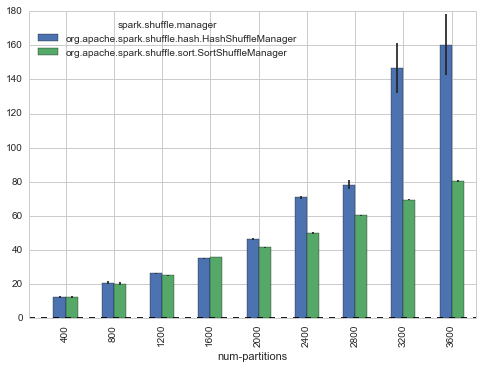
还有下面的实验:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从上面的两幅实验对比我们可以看到,随着mapper数量或者Reduce数量的增加,基于hash的shuffle实现的表现比基于sort的shuffle实现的表现越来越糟糕。
基于这个事实,在Spark 1.2版本,默认的shuffle将选用基于sort的。下面是spark 1.2文档的说明:
Implementation to use for shuffling data. There are two implementations available: sort and hash. Sort-based shuffle is more memory-efficient and is the default option starting in 1.2.
不过从源码中我们可以看出,其实如果有需要的话,完全可以实现自己的shuffle实现:
上述代码我们可以看到基于Hash的shuffle其实是org.apache.spark.shuffle.hash.HashShuffleManager类,而sort的shuffle是org.apache.spark.shuffle.sort.SortShuffleManager。如果我们没有配置spark.shuffle.manager,则默认选用hash,这个大小写没有关系。如果用户配置的spark.shuffle.manager在shortShuffleMgrNames中没有查到,则选用用户自定义的Shuffle。用户自定义的Shuffle必须继承ShuffleManager类,重写里面的一些方法。
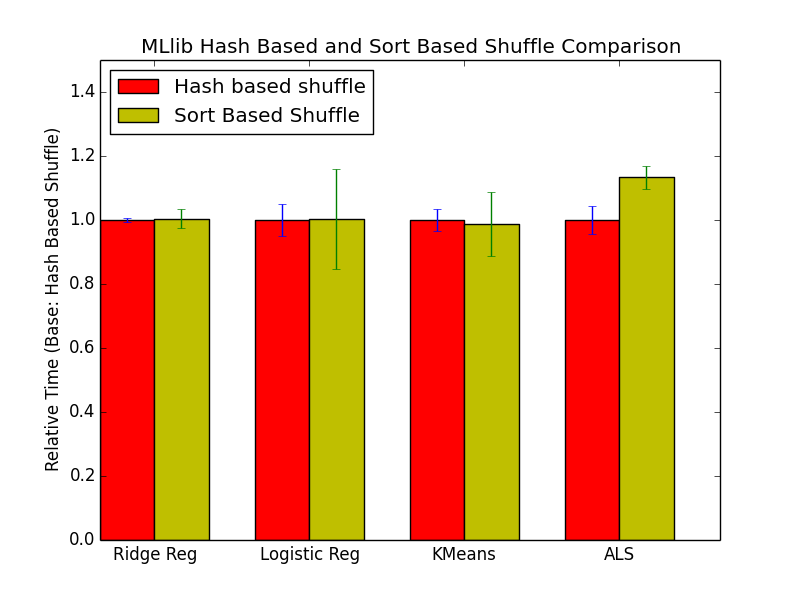
不过,也有人对MLlib中Shuffle进行了对比,实验如下结果:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从这个图可以看出,在MLlib下,基于sort的Shuffle并不一定比基于hash的Shuffle表现好,所以我们程序选择哪个Shuffle实现是需要考虑到具体的场景,如果内置的Shuffle实现不能满足自己的需求,我们完全可以自己实现一个Shuffle。
本文转自http://www.iteblog.com/archives/1138,所有权力归原作者所有。
1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发布》):基于sort的。
在Spark 1.1.0文档是这么说的:
Implementation to use for shuffling data. A hash-based shuffle manager is the default, but starting in Spark 1.1 there is an experimental sort-based shuffle manager that is more memory-efficient in environments with small executors, such as YARN. To use that,
change this value to SORT.
从上面说明可以看出,Spark 1.1版本默认的shuffle是基于hash,不过这个版本引入了基于sort的shuffle,在一些环境下使用该shuffle实现会得到更高效的表现;在这个版本中的Shuffle实现还是处于实验阶段,不过大家可以通过spark.shuffle.manager参数进行使用。
不过随着对基于hash的shuffle实现和基于sort的shuffle实现进行实验对比,如下图所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
还有下面的实验:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从上面的两幅实验对比我们可以看到,随着mapper数量或者Reduce数量的增加,基于hash的shuffle实现的表现比基于sort的shuffle实现的表现越来越糟糕。
基于这个事实,在Spark 1.2版本,默认的shuffle将选用基于sort的。下面是spark 1.2文档的说明:
Implementation to use for shuffling data. There are two implementations available: sort and hash. Sort-based shuffle is more memory-efficient and is the default option starting in 1.2.
不过从源码中我们可以看出,其实如果有需要的话,完全可以实现自己的shuffle实现:
1 | // Let the user specify short names for shuffle managers |
2 | val shortShuffleMgrNames = Map( |
3 | "hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager" , |
4 | "sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager" ) |
5 | val shuffleMgrName = conf.get( "spark.shuffle.manager" , "hash" ) |
6 | val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName) |
7 | val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass) |
不过,也有人对MLlib中Shuffle进行了对比,实验如下结果:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从这个图可以看出,在MLlib下,基于sort的Shuffle并不一定比基于hash的Shuffle表现好,所以我们程序选择哪个Shuffle实现是需要考虑到具体的场景,如果内置的Shuffle实现不能满足自己的需求,我们完全可以自己实现一个Shuffle。
本文转自http://www.iteblog.com/archives/1138,所有权力归原作者所有。

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- c语言实现hashmap(转载)
- Hadoop_2.1.0 MapReduce序列图
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- 选定虚拟主机 性能凸显优势
- 修改一行代码提升 Postgres 性能 100 倍
- 推荐Sql server一些常见性能问题的解决方法
- Ruby中Hash的11个问题解答
- SQL Server误区30日谈 第9天 数据库文件收缩不会影响性能
- 和表值函数连接引发的性能问题分析
- SQLServer 2000 升级到 SQLServer 2008 性能之需要注意的地方之一
- 数据库性能优化三:程序操作优化提升性能
- VBS中的字符串连接的性能问题
- Ruby简明教程之数组和Hash介绍
- mysql 性能的检查和调优方法
- 数据库性能优化二:数据库表优化提升性能
- SQL语句优化提高数据库性能