机器学习算法汇总
2016-01-25 16:02
204 查看
摘要: 机器学习
机器学习算法汇总
1. 前言
通过将工作中用到的机器学习算法归纳汇总,方便以后查找,快速应用。2. 推荐算法
交叉最小方差
| 算法名字 | 交叉最小方差, Alternating Least Squares, ALS |
| 算法描述 | Spark上的交替性最小二乘ALS本质是一种协同过滤的算法 |
| 算法原理 | 1. 首先将用户推荐对象交互历史转换为矩阵,行表示用户,列表示推荐对象,矩阵对应 i,j 表示用户 i 在对象 j 上有没有行为 2. 协同过滤就是要像填数独一样,填满1得到的矩阵,采用的方法是矩阵分解 算法原理图 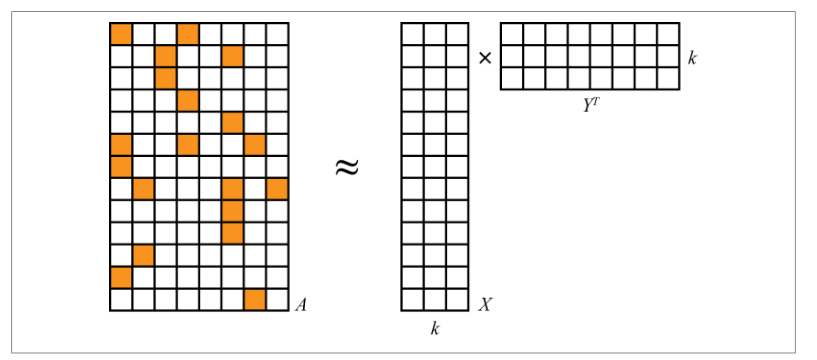 3. 原始矩阵 A 是一个很大的稀疏矩阵,然后利用 ALS 分解成近似两个矩阵 B 和 C 的乘,另外两个矩阵就比较密集,而且 B 矩阵的列可以解释为一个事物的几个方面。 4. 用户 k 对对象 h 的喜好程度就可以通过矩阵 B 的 k 行乘 矩阵 C 的 h 列得到 |
| 使用场景 | 当用户和推荐的对象本身属性数据没有,只存在用户和推荐对象历史交互数据的时候,当提炼出用户推荐对象的关系矩阵可以发现是一个大型的稀疏矩阵 |
| 算法优缺点 | 优点: 1. 此算法可伸缩 2. 速度很快 3. 适合大数据 4.新异兴趣发现、不需要领域知识 5. 随着时间推移性能提高 6. 推荐个性化、自动化程度高 7. 能处理复杂的非结构化对象 缺点: 1. 稀疏问题 2. 可扩展性问题 3. 新用户问题 4. 质量取决于历史数据集 5. 系统开始时推荐质量差 |
| 参考资料 | 1. 算法原理 Large-scale Parallel Collaborative Filtering for the Netflix Prize 2. MLlib实现 MLlib - Collaborative Filtering |

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- 用Python从零实现贝叶斯分类器的机器学习的教程
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- ClassNotFoundException:scala.PreDef$
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- My Machine Learning
- 机器学习---学习首页 3ff0
- Spark初探
- Spark Streaming初探
- Spark本地开发环境搭建
- 搭建hadoop/spark集群环境
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- spark内存概述
- Spark Shuffle之Hash Shuffle