过拟合现象
2016-01-14 20:44
525 查看
过拟合现象
为了得到一致假设而使假设变得过度复杂称为过拟合。想像某种学习算法产生了一个过拟合的分类器,这个分类器能够百分之百的正确分类样本数据(即再拿样本中的文档来给它,它绝对不会分错),但也就为了能够对样本完全正确的分类,使得它的构造如此精细复杂,规则如此严格,以至于任何与样本数据稍有不同的文档它全都认为不属于这个类别。简言之,就是与样本拟合的很好,但是不能很好的预测实际的情况。线性回归的过拟合现象:
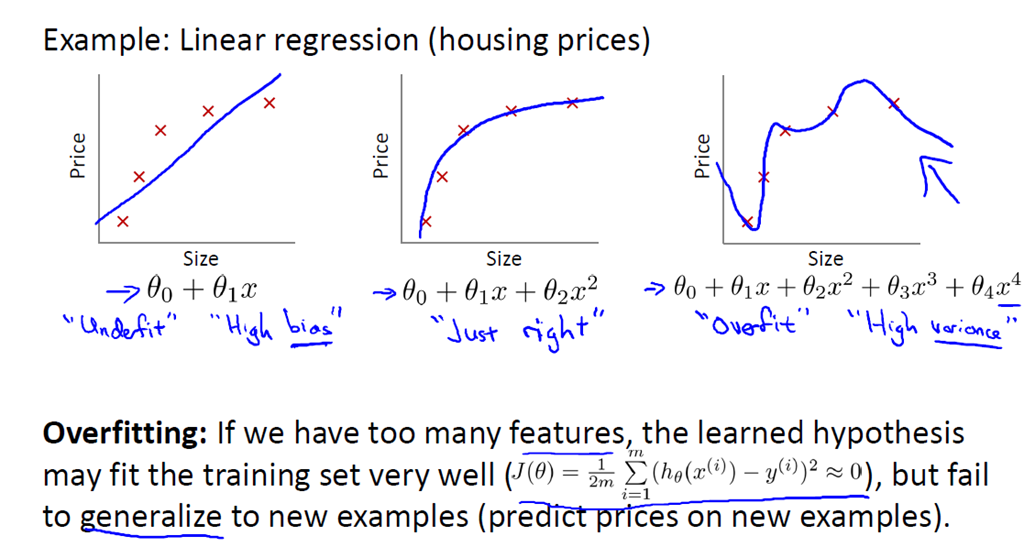
逻辑回归的过拟合现象:
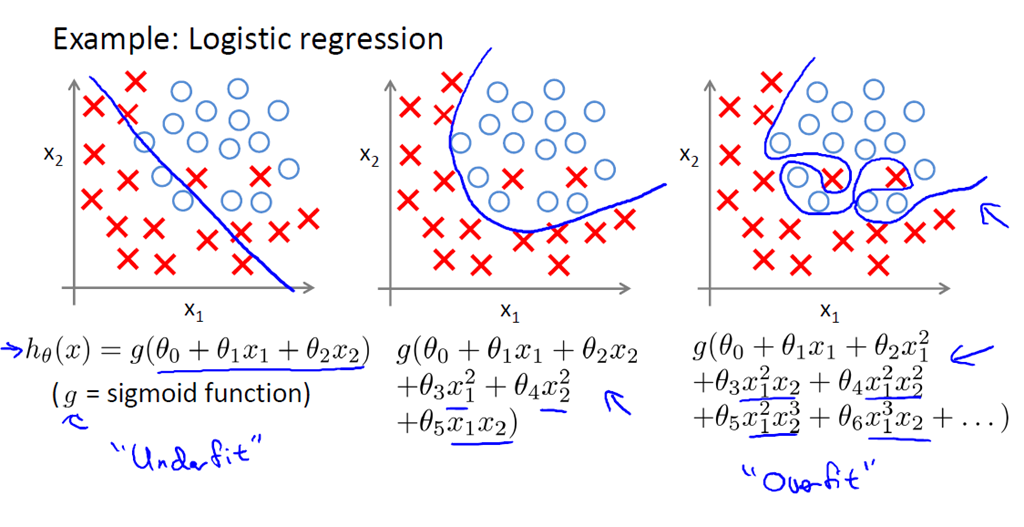
解决方案
减少特征量
人工检查变量,决定哪些更加重要,哪些应该舍弃。模型选择算法:为了自动的完成“人工检查变量”
正则化
正则化思想是保留所有的特征量,只改变参数θ的大小,通过惩罚一些参数得到更为简单的假设函数。以线性回归为例:
我们可以把代价函数写成这样:
J(θ)=12mΣmi=1(hθ(x(i)−y(i))2)+λΣnj=1θ2j
注:θj的序号从1开始而不是从0开始,λ叫做正则化参数是一个整数。λ的目的是为了平衡两个目标。
第一个目标就是我们想要训练,使假设更好地拟合训练数据。
第二个目标是我们想要保持参数值较小
求解
仍然有两种方法:梯度下降
代数方法:θ=(XτX+λX)−1XτY(E为单位矩阵)

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 初识机器学习算法有哪些?
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 自动编程体系设想(一)
- 自动编程体系设想(一)
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 常用的分类评估--基于R语言
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念