1、NASA Super Cloud Library(SCL)
2016-01-13 16:49
295 查看
Empowering Data Management, Diagnosis, and Visualization of Cloud-Resolving Models (CRM) by Cloud Library upon Spark and Hadoop
使用
Spark and Hadoop建立数据管理、诊断、可视化的一套云判识模型(CRM)
主要有用的有以下几块:1、Develop Super Cloud Library (SCL) supporting Cloud Resolving Model using Spark on Hadoop.
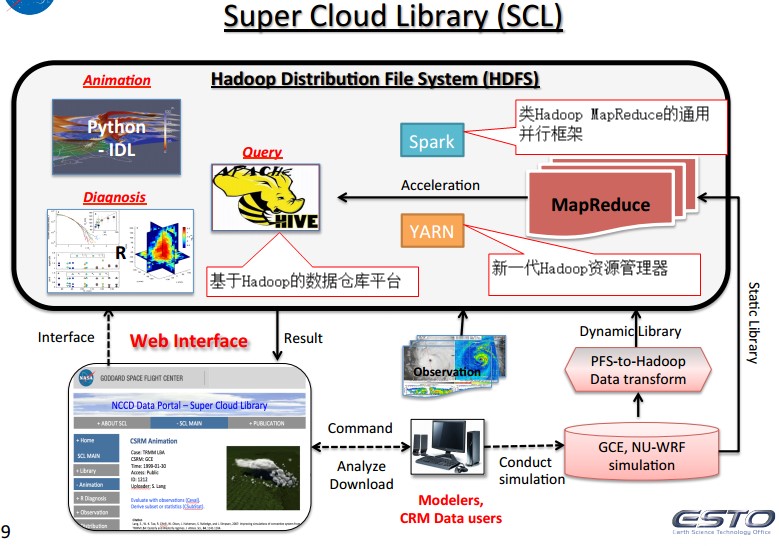
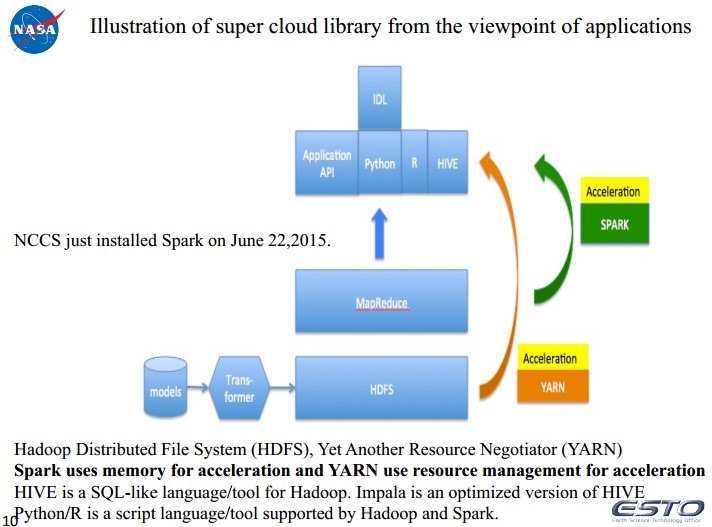
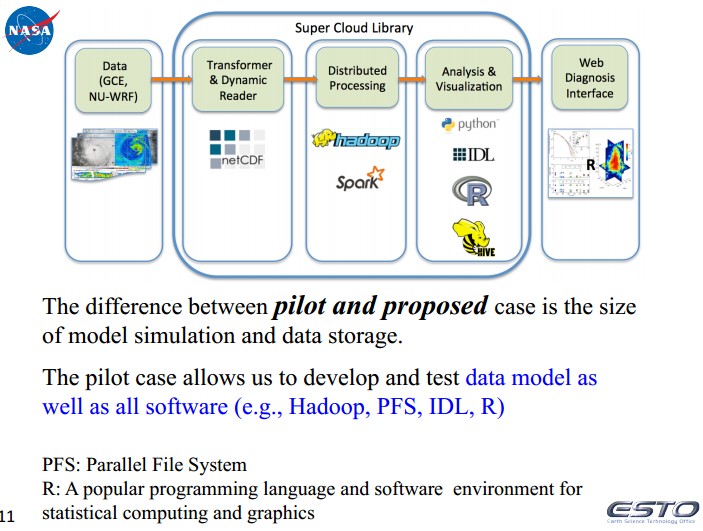
2、数据模型将NU-WRF的netcdf数据和GCE的二进制数据输出为CSV格式。例如:NU-WRF (1 km and 48 h simulation): IPHEX; 10 output variables. Hourly output in a text (CSV) format has 465GBGIGALES, 4096x4096x104, 2-3 day simulation: Single output data size ~2.5TB; Total output data size ~125TB
3、IDL+Hadoop 48个1GB大小的WRF模拟数据的动画生成,能够从原来的17分钟改进为14分钟。Developed an animation/movie of 48 text files from NU-WRF Pilot simulations. Each file has ~1GB

Job trackers and task trackers run on the master node, and task trackers and map tasks run on slave nodes. Virtual blocks are managed in the virtual block table in namenode. A task tracker initiates the PFS prefetcher thread to get data directly from a remote PFS. Map tasks initiate the PFS reader threads to import data directly from the remote PFS.
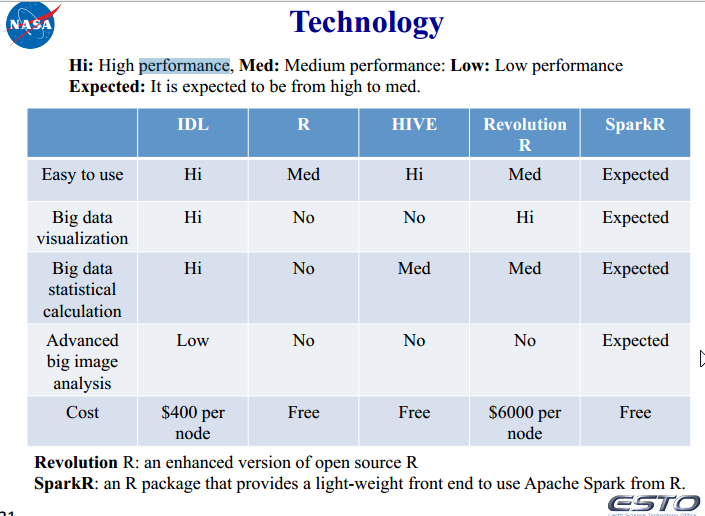
5、 各个技术使用场景的统计
来自为知笔记(Wiz)
使用
Spark and Hadoop建立数据管理、诊断、可视化的一套云判识模型(CRM)
主要有用的有以下几块:1、Develop Super Cloud Library (SCL) supporting Cloud Resolving Model using Spark on Hadoop.
• Create cloud data files• Develop data model and Hadoop format transformer• Develop dynamic transfer tool to Hadoop• Develop subset and visualization APIs (Application Programming Interfaces)• Develop Web User Interface
2、数据模型将NU-WRF的netcdf数据和GCE的二进制数据输出为CSV格式。例如:NU-WRF (1 km and 48 h simulation): IPHEX; 10 output variables. Hourly output in a text (CSV) format has 465GBGIGALES, 4096x4096x104, 2-3 day simulation: Single output data size ~2.5TB; Total output data size ~125TB
3、IDL+Hadoop 48个1GB大小的WRF模拟数据的动画生成,能够从原来的17分钟改进为14分钟。Developed an animation/movie of 48 text files from NU-WRF Pilot simulations. Each file has ~1GB
– 14 minutes for IDL with Hadoop streaming• NCCS Hadoop cluster has 34 nodes• IDL is on one Hadoop node and can run with multiple instances simultaneously• Files stored in Hadoop file system (HDFS)• 15 seconds for reading each file out of HDFS– 17 minutes for IDL with NCCS Discover GPFS file system• IDL is on one NCCS Dali compute node• Files stored in NCCS GPFS file system



4、基于Hadoop的动态读取系统。Job trackers and task trackers run on the master node, and task trackers and map tasks run on slave nodes. Virtual blocks are managed in the virtual block table in namenode. A task tracker initiates the PFS prefetcher thread to get data directly from a remote PFS. Map tasks initiate the PFS reader threads to import data directly from the remote PFS.
5、 各个技术使用场景的统计
来自为知笔记(Wiz)

相关文章推荐
- maven-使用myeclipse创建maven项目
- 【NOIP2010】【tyvj1409】数字统计加强版
- IntelliJ IDEA 智能集成开发环境使用指南
- 限制linux 用户使用su命令转化root权限
- Invalid bean definition with name ‘dataSource’ definition in class path resource [applicationContext
- Android中自定义View的研究 -- 在XML中引用自定义View
- iOS设置圆角及圆形图片
- xp开机提示找不到配置文件同时桌面文件被删除的解决办法
- UIView animateWithDuration: delay: options: animations: completion:
- C# 进制转换 进制互转
- C++按值传递对象和传递引用的选择
- android 在xml文件中引用自定义View
- mysql import upzip *.sql at same time
- java socket编程
- 搭建一个免费的,无限流量的Blog----github Pages和Jekyll入门
- 皕杰报表配置Demoserver数据源
- 分页page,关于form表单的控制范围问题。哪些数据会随着form表单提交?图文详解
- 使用数据泵导入导出dmp文件
- php.ini配置与中国间隔12小时间设置方法
- IOS极光推送