tns cluster 简介
2016-01-11 11:57
661 查看
tns(thrift name server)是我在700Bike开发的一个thrift rpc分布式组件,可以实现高可靠、负载均衡、动态水平扩展等.
相比haproxy、zookeeper等有什么优势?我们知道网络程序唯一保证可靠的方式就是心跳包,同haproxy方式有什么区别,可以阅读wiki why
使用方式wiki上都有,这里简单说说tns cluster的特性,及设计结构。
cluster结构图

tns cluster 采用无中心化设计,也就是cluster中每个node都是均等的,在任一节点执行命令都等效,集群组件类似于redis,在节点上执行meet <other host>即可,满足传递性,例如: 1 meet 2;2 meet 3 等效于1 meet 3; 1 meet 2
每个node均有一个ID,ID唯一,根据hostname+port生成,在集群中cluster按ID排序,组成一个环,如上图绿色环,其中ID较小的会负责检查比其稍大的ID的节点健康状态,并将自己知道的cluster list及健康状态和service list(不包含健康状态)传输到对方,实现集群信息同步,假如2节点Down了,1会标记2节点状态为down,并将自己的信息以后同步给3,因为2一旦down掉,是不可自动恢复的,只能手动恢复(重启2,并执行meet 重新上线).
如上,这种做法,一个节点有且仅有一个节点会同步信息给它,并且它也只同步信息给一个节点,集群增加节点不会增加单个node的压力。service list只会同步列表,不会同步service节点状态,避免1节点状态传递到6延迟比较高,每个tns节点自行维护service 状态,这样客户端不论从那个cluster node中同步service列表均比较实时。
tns内部结构图
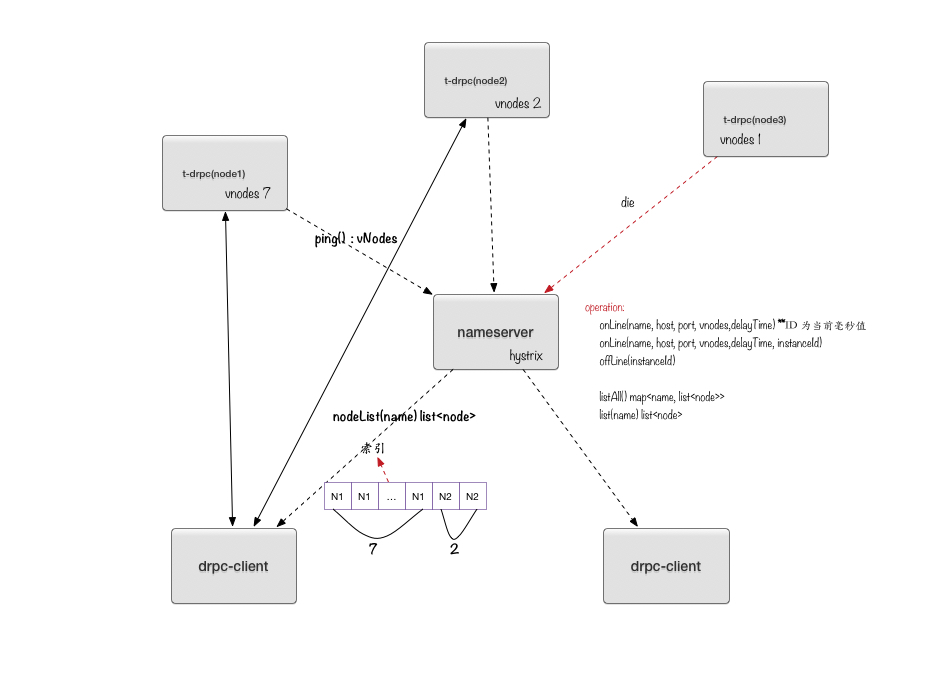
如图,在nameserver中添加三个rpc server节点,service名称定义为drpc,每增加一个节点时,可以指定ping的周期,nameserver会定时调用drpc的ping方法,ping方法返回vNodes,含义为虚拟节点,用于客户端对请求负载均衡,另外nameserver也根据每次ping返回的vNodes值来判断service server是否可用,若vNodes<0,nameserver会标记service node为down,nameserver只会同步UP状态的service节点列表给客户端,增加或下线一个节点,一个周期后(客户端设定周期)也会被客户端同步到。
单个的vNodes没什么含义,在一个service下有多个node时才有含义,例如上图中drpc包含三个节点,并且每个节点vNodes分别为7、2、1,客户端负载均衡后,其中7/10的流量会流向node1,1/10会流向node3,从而实现负载均衡,客户端默认提供一个随机选择器,大家可以按自己的意愿自己实现。
线上不论是tns node还是service node均可随时增加或减少,从而实现水平动态可扩展。
详细使用帮助文档,朋友们可以参考thriftnameserver 的WIKI。

jerry 于北京
2016-1-11
相比haproxy、zookeeper等有什么优势?我们知道网络程序唯一保证可靠的方式就是心跳包,同haproxy方式有什么区别,可以阅读wiki why
使用方式wiki上都有,这里简单说说tns cluster的特性,及设计结构。
cluster结构图
tns cluster 采用无中心化设计,也就是cluster中每个node都是均等的,在任一节点执行命令都等效,集群组件类似于redis,在节点上执行meet <other host>即可,满足传递性,例如: 1 meet 2;2 meet 3 等效于1 meet 3; 1 meet 2
每个node均有一个ID,ID唯一,根据hostname+port生成,在集群中cluster按ID排序,组成一个环,如上图绿色环,其中ID较小的会负责检查比其稍大的ID的节点健康状态,并将自己知道的cluster list及健康状态和service list(不包含健康状态)传输到对方,实现集群信息同步,假如2节点Down了,1会标记2节点状态为down,并将自己的信息以后同步给3,因为2一旦down掉,是不可自动恢复的,只能手动恢复(重启2,并执行meet 重新上线).
如上,这种做法,一个节点有且仅有一个节点会同步信息给它,并且它也只同步信息给一个节点,集群增加节点不会增加单个node的压力。service list只会同步列表,不会同步service节点状态,避免1节点状态传递到6延迟比较高,每个tns节点自行维护service 状态,这样客户端不论从那个cluster node中同步service列表均比较实时。
tns内部结构图
如图,在nameserver中添加三个rpc server节点,service名称定义为drpc,每增加一个节点时,可以指定ping的周期,nameserver会定时调用drpc的ping方法,ping方法返回vNodes,含义为虚拟节点,用于客户端对请求负载均衡,另外nameserver也根据每次ping返回的vNodes值来判断service server是否可用,若vNodes<0,nameserver会标记service node为down,nameserver只会同步UP状态的service节点列表给客户端,增加或下线一个节点,一个周期后(客户端设定周期)也会被客户端同步到。
单个的vNodes没什么含义,在一个service下有多个node时才有含义,例如上图中drpc包含三个节点,并且每个节点vNodes分别为7、2、1,客户端负载均衡后,其中7/10的流量会流向node1,1/10会流向node3,从而实现负载均衡,客户端默认提供一个随机选择器,大家可以按自己的意愿自己实现。
线上不论是tns node还是service node均可随时增加或减少,从而实现水平动态可扩展。
详细使用帮助文档,朋友们可以参考thriftnameserver 的WIKI。
jerry 于北京
2016-1-11

相关文章推荐
- RPC failed; result=22, HTTP code = 411
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- Rabbitmq集群搭建笔记
- MySQL Cluster如何创建磁盘表方法解读
- C#分布式事务的超时处理实例分析
- Erlang分布式节点中的注册进程使用实例
- 通过 Redis 实现 RPC 远程方法调用(支持多种编程语言)
- 基于HBase Thrift接口的一些使用问题及相关注意事项的详解
- IIS提示出现RPC服务器不可用的解决方法
- Windows Server 2003 下配置 MySQL 集群(Cluster)教程
- RPC、RMI、SOAP的区别详解
- C++实现的分布式游戏服务端引擎KBEngine详解
- 使用cluster 将自己的Node服务器扩展为多线程服务器
- node.js中RPC(远程过程调用)的实现原理介绍
- ASP.NET通过分布式Session提升性能
- Spring+Mybatis+Mysql搭建分布式数据库访问框架的方法
- Python XML RPC服务器端和客户端实例
- 分享一个简单易用的RPC开源项目—Tatala