Map-Reduce程序设计
2016-01-02 20:11
399 查看
任务一
现有一批路由日志(有删减),需要提取MAC地址和时间,删去其它内容,利用MapReduce思想设计程序实现。
实验步骤
将hadoop下的output文件夹删除,并建立input文件夹
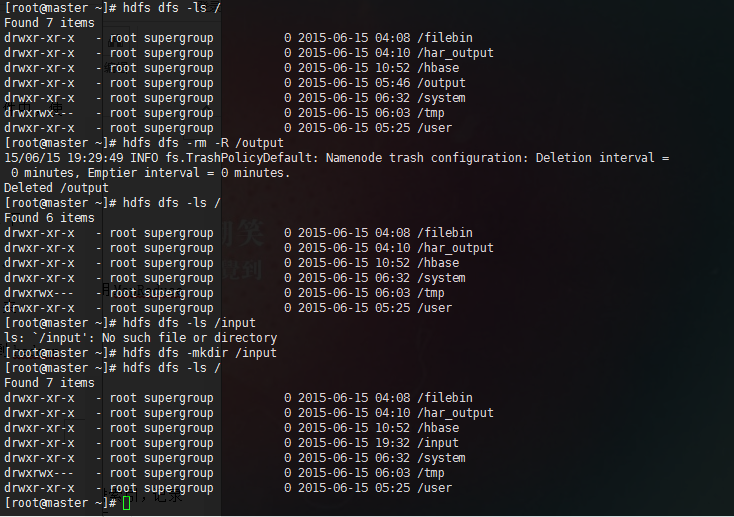
在Centos主机/tmp目录下新建tel_log文件,并将log信息填入此文件,并将此文件上传至hadoop /input文件夹下

通过ssh将写好的代码上传至centos Hadoop主机(tel.java)
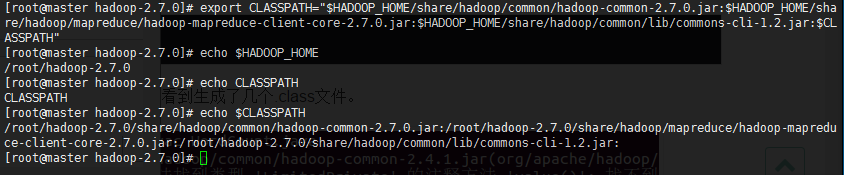
将hadoop-common-2.7.0.jar、hadoop-mapreduce-client-core-2.7.0.jar、commons-cli-1.2.jar加入HADOOP_CLASSPATH
编译TEL.java 并将tel*.class打包为jar
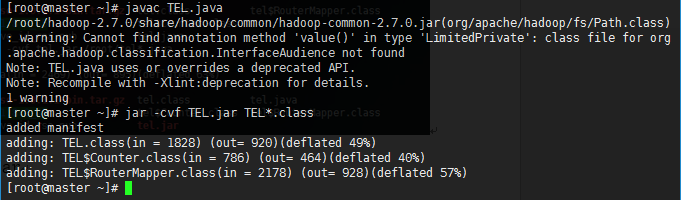
查了一下资料,这个警告并不影响后面的实验,所以不用修改
运行编译好的jar
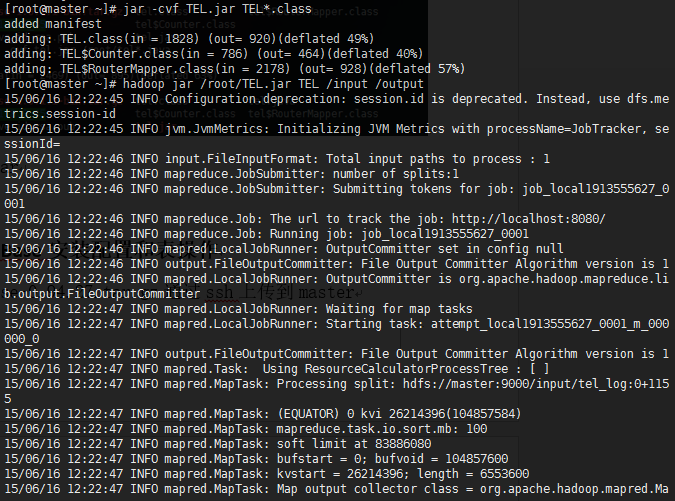
查看/output/part-0000
java代码
任务二
有一批电话通信清单,记录了用户A拨打用户B的记录,现在需要做一个倒排索引,记录打给用户B的所有用户A,安装MapReduce思想,设计程序实现。
实验步骤
将写好的Phone.java代码上传至hadoop centos主机
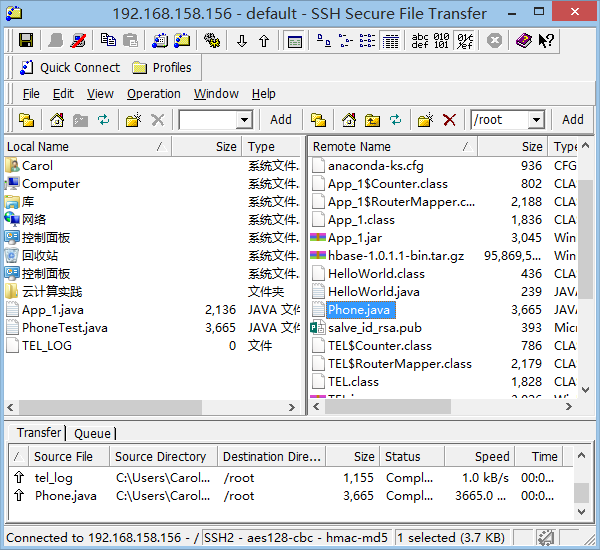
在hadoop上新建/inputPhone文件夹,并将日志文件上传到这个路径
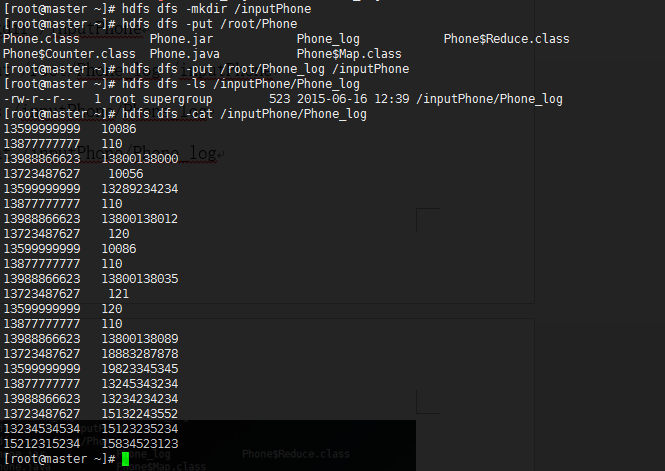
运行jar包中的Phone类
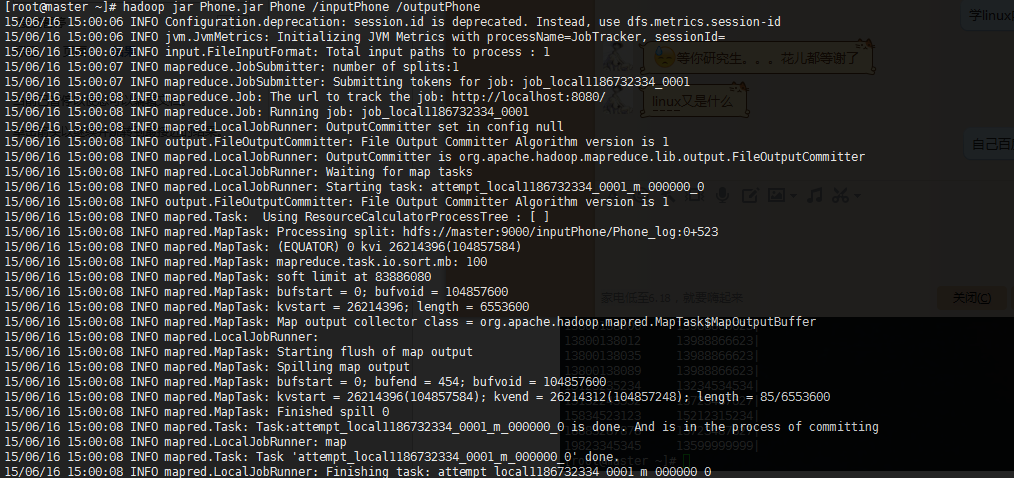
显示程序运行结果
进行编译Phone.java代码
运行生成的jar包
java代码
现有一批路由日志(有删减),需要提取MAC地址和时间,删去其它内容,利用MapReduce思想设计程序实现。
实验步骤
将hadoop下的output文件夹删除,并建立input文件夹
hdfs dfs -rm -R /output hdfs dfs -mkdir /input hdfs dfs -ls /
在Centos主机/tmp目录下新建tel_log文件,并将log信息填入此文件,并将此文件上传至hadoop /input文件夹下
vim /tmp/tel_log
hdfs dfs -put /tmp/tel_log /input hdfs dfs -ls /input
通过ssh将写好的代码上传至centos Hadoop主机(tel.java)
将hadoop-common-2.7.0.jar、hadoop-mapreduce-client-core-2.7.0.jar、commons-cli-1.2.jar加入HADOOP_CLASSPATH
export CLASSPATH="$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.0.jar:$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar:$CLASSPATH"
编译TEL.java 并将tel*.class打包为jar
javac /root/TEL.java
查了一下资料,这个警告并不影响后面的实验,所以不用修改
jar -cvf TEL.jar /root/TEL*.class
运行编译好的jar
查看/output/part-0000
java代码
import java.io.IOException;
//java 工具包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class TEL extends Configured implements Tool{
enum Counter{
LINESKIP,
}
/**
*Mapper<LongWritable,Text,NullWritable,Text>
*
*/
public static class RouterMapper extends Mapper<LongWritable, Text, NullWritable, Text>{
public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException{
String line = value.toString(); //将map得到的一行TEXT转换为字符串
try{
String[] lineSplit = line.split(" ");//对字符串进行分片 (备注;这里输入的文件间隔只能是一个空格,否则会导致统计结果出错,这里没做处理,Phone。java代码做了处理)
String month = lineSplit[0];//得到月份
String day = lineSplit[1];//得到日期
String time = lineSplit[2];//得到时间
String mac = lineSplit[6];//得到mac地址
Text out = new Text(month + " " + day + " " + time + " " + mac); //形成新的输出字符串
context.write(NullWritable.get(), out);//输出
}
catch (ArrayIndexOutOfBoundsException e) {
context.getCounter(Counter.LINESKIP).increment(1);
return;
}
}
}
@Override
public int run(String[] arg0) throws Exception{
Configuration conf = getConf();
Job job = new Job(conf, "TEL");//指定任务名称
job.setJarByClass(TEL.class);//指定任务对应Class
FileInputFormat.addInputPath(job, new Path(arg0[0]));//输入路劲参数
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));//输出路径参数
job.setMapperClass(RouterMapper.class);//调用RouterMapper类作为Mapper的任务代码
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(NullWritable.class);//指定输出的key格式,要和RouterMapper的输出数据格式一致
job.setOutputValueClass(Text.class); //指定输出的value格式,要和RouterMapper的输出数据格式一致
job.waitForCompletion(true);
return job.isSuccessful() ? 0 : 1;
}
//main方法运行的时候需要指定输入路径和输出路径
public static void main(String[] args) throws Exception{
int res = ToolRunner.run(new Configuration(), new TEL(), args);
System.exit(res);
}
}任务二
有一批电话通信清单,记录了用户A拨打用户B的记录,现在需要做一个倒排索引,记录打给用户B的所有用户A,安装MapReduce思想,设计程序实现。
实验步骤
将写好的Phone.java代码上传至hadoop centos主机
在hadoop上新建/inputPhone文件夹,并将日志文件上传到这个路径
hdfs dfs -mkdir /inputPhone hdfs dfs -put /root/Phone_log /inputPhone hdfs dfs -ls /inputPhone/Phone_log hdfs dfs -cat /inputPhone/Phone_log
运行jar包中的Phone类
hadoop jar Phone.jar Phone /inputPhone /outputPhone
显示程序运行结果
hdfs dfs -cat /outputPhone/*
进行编译Phone.java代码
javac Phone.java jar -cvf Phone.jar Phone*.class
运行生成的jar包
hadoop jar /root/Phone.jar Phone /inputPhone /outputPhone
java代码
//导入hadoop接口
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class Phone extends Configured implements Tool {
enum Counter {
LINESKIP;
}
@Override
public int run(String[] args) throws Exception{
Configuration conf = getConf();
Job job = new Job(conf, "Phone");//指定任务名称
job.setJarByClass(Phone.class);//指定对应任务Class
FileInputFormat.addInputPath(job, new Path(args[0]));//输入路径参数
FileOutputFormat.setOutputPath(job, new Path(args[1]));//输出路径参数
job.setMapperClass(Map.class);//调Map类作为Mapper的任务代码
job.setReducerClass(Reduce.class);//调Reduce类作为reducer的任务代码
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);//指定输出的key格式,要和RouterMapper的输出数据格式一致
job.setOutputValueClass(Text.class);//指定输出的value格式,要和RouterMapper的输出数据格式一致
job.waitForCompletion(true);
return job.isSuccessful() ? 0 : 1;
}
public static class Map extends
Mapper<LongWritable, Text, Text, Text> { //<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
try {
String line = value.toString();//将map得到的TEXT转换为String
String[] lineSplit = line.split(" "); //分片处理
String A_user = "";//主叫用户
String B_user = ""; //被叫用户
boolean flag_one = false;//标记是否第一次得到非空字符串
for (String split : lineSplit) {
if (!split.equals("") && flag_one == false){ //将第一个非空字符串赋值给A_user
A_user = split;
flag_one = true;
continue;
}
else if (!split.equals("") && flag_one == true){//将第二个非空字符串赋值给A_user
B_user += split;
}
}
context.write(new Text(B_user), new Text(A_user));//输出
}
catch (java.lang.ArrayIndexOutOfBoundsException e) {
context.getCounter(Counter.LINESKIP).increment(1);
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Context context)
throws IOException, InterruptedException{
String valueStr;
String out = "";
for (Text value : values){ //reduce统计
valueStr = value.toString() + "| "; //将所有对应被叫用户的主叫用户整体合成一个out字符串
out += valueStr;
}
context.write(key, new Text(out)); //输出
}
}
//main方法运行的时候需要指定输入路径和输出路径
public static void main(String[] args) throws Exception{
int res = ToolRunner.run(new Configuration(), new Phone(), args);
System.exit(res);
}
}

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- 一步一步跟我学易语言之第二个易程序菜单设计
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- C#中设计、使用Fluent API
- 基于逻辑运算的简单权限系统(原理,设计,实现) VBS 版
- hadoop常见错误以及处理方法详解
- JavaScript 组件之旅(一)分析和设计
- C# 事件的设计与使用深入理解
- 大型网站设计注意事项大全
- Android中的脑残设计总结
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- 常用的Javascript设计模式小结
- 用户权限管理设计[图文说明]
- MongoDB中的MapReduce简介