HDFS 和 YARN 的 HA 故障切换
2016-01-01 11:09
519 查看
一 非 HDFS HA 集群转换成 HA 集群
二 HDFS 的 HA 自动切换命令
1 获得当前 NameNode 的 active 和 standby 状态
2 NameNode 的 active 和 standby 状态切换
3 HDFS HA自动切换比手工切换多出来的步骤
三 ResourceManager 的 HA 自动切换命令
1 获得当前 RM 的 active 和 standby 状态
2 RM 的 active 和 standby 状态切换
3 yarn rmadmin 所支持的命令
4 YARN HA自动切换比手工切换多出来的步骤
四 HDFS HA 故障切换后欲恢复原 active NameNode 步骤
2. 在 NameNode1上对 journalnode 的共享数据进行初始化,然后启动 namenode 进程
3. 在 NameNode2 上同步 journalnode 的共享数据,和 NameNode 上存放的元数据,然后启动 namenode 进程
4. 在其中一台 NameNode 上启动所有的 datanode 进程
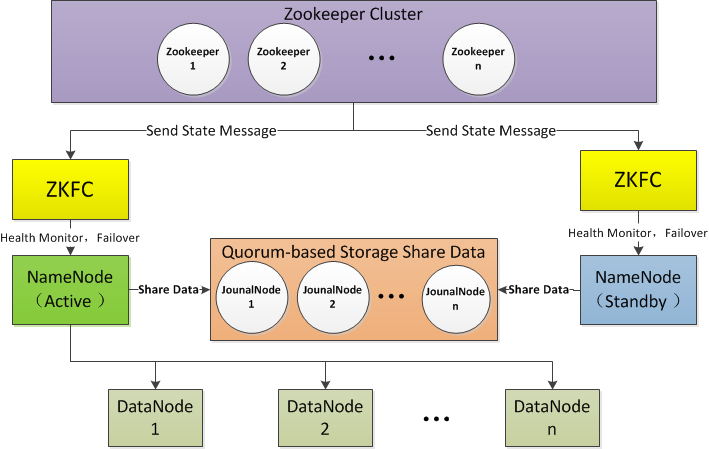
说明: 为了更加通俗的说明,笔者将两台运行 namenode 进程的主机名抽象为 NameNode1 和 NameNode2,笔者更倾向 NameNode1 上的运行的是 active 状态的 namenode 进程,NameNode2 上的运行的是 standby状态的 namenode 进程,而实际操作中,master5 就是这个 NameNode1 ,master52 就是这个 NameNode2。
1. 未设置自动故障切换 (false)
确定要转为 active 状态的主机名,这里将 NameNode1 设为 active,使用命令行工具进行状态切换:
此处 “NameNode2 NameNode1” 的顺序表示 active 状态由 NameNode2 转换到 NameNode1 上(虽然 NameNode2 在转化前也是 standby 状态)。
有时候,当我们系统中 NameNode2 出现故障了,就可以利用上一步中把 NameNode1 的状态切换为active 后,系统自动把 NameNode2 上的 namenode 进程关闭,再把错误原因排除后重启该 namenode进程,启动后该 namenode 状态为 standby,等待下一次 NameNode1 出现故障时即可将 NameNode2 状态切换为 active。
亦或者使用以下命令将 NameNode1 主机上的 namenode 状态切换到 active 或 standby 状态
但是需要注意的是这两个命令不会尝试运行任何的 fence,因此不应该经常使用。应该更倾向于用
2. 设置自动故障切换 (true)
如果执行下面命令,则会报错
错误信息:
forcefence and forceactive flags not supported with auto-failover enabled.
若要手工切换其中一个 NameNode 节点的 Active 状态改变为 Standby 状态,将另一个 NameNode 节点的 Standby 状态改变为 Active 状态,则可以
假设此时 master52 上 namedode 是 active 状态,而 master5 上 namenode 是 standby 状态,下图呈现了该过程:

另外一种方法就是,关闭当前为 active namenode 状态的上的 DFSZKFailoverController 进程(这个方法可靠性有待考察…)
此时,active 状态的 namenode 立刻更变为 standby 状态,另一个 standby 状态的 nameNode 立刻更变为 active 状态,如下图所示:

当继续关闭了另一个 namenode 的 zkfc 服务之后,它依旧是 active 状态,且两个 namenode 仍然正常工作!
在经过上述之后,master5 的 namenode 变为了 standby ,如果通过它提供的命令转化为 active 会怎样?失败了呗,看英文解释吧…

更多命令可以通过 help 查看,更多详细解释请看 管理员命令

其中 checkHealth 检查 NameNode1 的状态。正常就返回 0,否则返回非 0 值。
关键人家官网也说了,这个功能还没有实现,现在将总是返回 success,除非给定的 NameNode 完全关闭。
配置文件 hdfs-site.xml 中把
操作上格式化 zk,执行命令
在两个 NameNode 上启动 zkfc,执行命令
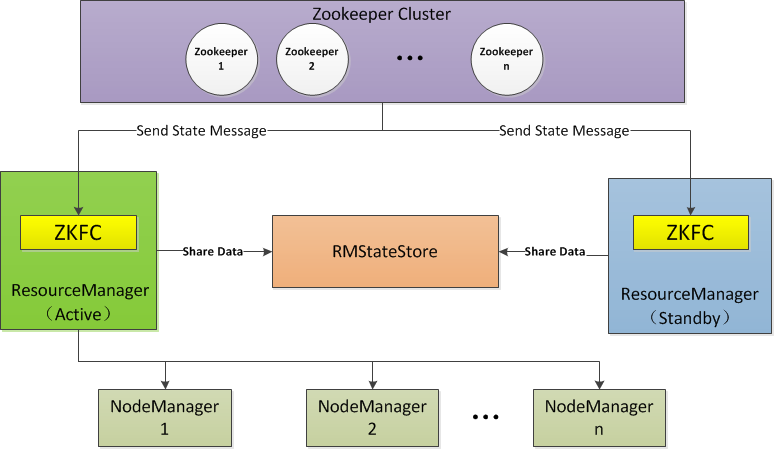
说明: 为了更加通俗的说明,笔者将两台运行 resourcemanager 进程的主机名抽象为 RM1 和 RM2,笔者更倾向 RM1 上的运行的是 active 状态的 resourcemanager 进程,RM2 上的运行的是 standby 状态的 resourcemanager 进程,而实际操作中,master5 就是这个 RM1 ,master52 就是这个 RM2。
其中关于 ha-id 是在 yarn-site.xml 配置文件中设置的。

hadoop也为管理员提供了 CLI 的方式管理 RM HA,但在没有启用 HA 的情况下,也就是在 yarn-site.xml 配置文件中没有设置
1. 未设置自动故障切换 (false)
2. 设置自动故障切换 (true)

显而易见,失败了。如果需要手工切换,这时候可以
或关闭 active 状态的 RM 的 resourcemanager 进程
然后再重启 RM 的 resourcemanager 进程
此时就可以成功切换状态了…

其中列出的 -failover 选项,yarn rmadmin 不支持此选项。更多详细解释请看 使用 yarn rmadmin 管理 ResourceManager HA
配置文件 yarn-site.xml 中把
在 Journal 和 QuorumPeerMain 进程正常启动的情况下
将所有的 datanode 进程关闭,将 master5 上的 namenode 进程也关闭
在 master5 上执行
再将 master52 上重启 namenode 进程, OK 了
二 HDFS 的 HA 自动切换命令
1 获得当前 NameNode 的 active 和 standby 状态
2 NameNode 的 active 和 standby 状态切换
3 HDFS HA自动切换比手工切换多出来的步骤
三 ResourceManager 的 HA 自动切换命令
1 获得当前 RM 的 active 和 standby 状态
2 RM 的 active 和 standby 状态切换
3 yarn rmadmin 所支持的命令
4 YARN HA自动切换比手工切换多出来的步骤
四 HDFS HA 故障切换后欲恢复原 active NameNode 步骤
一. 非 HDFS HA 集群转换成 HA 集群
1. 分别启动所有的 journalnode 进程,在其中一台 NameNode 上完成即可(比如 NameNode1)$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode
2. 在 NameNode1上对 journalnode 的共享数据进行初始化,然后启动 namenode 进程
$HADOOP_HOME/bin/hdfs namenode -initializeSharedEdits $HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
3. 在 NameNode2 上同步 journalnode 的共享数据,和 NameNode 上存放的元数据,然后启动 namenode 进程
$HADOOP_HOME/bin/hdfs namenode -bootstrapStandby $HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
4. 在其中一台 NameNode 上启动所有的 datanode 进程
$HADOOP_HOME/sbin/hadoop-daemon.sh start datanode
二. HDFS 的 HA 自动切换命令
说明: 为了更加通俗的说明,笔者将两台运行 namenode 进程的主机名抽象为 NameNode1 和 NameNode2,笔者更倾向 NameNode1 上的运行的是 active 状态的 namenode 进程,NameNode2 上的运行的是 standby状态的 namenode 进程,而实际操作中,master5 就是这个 NameNode1 ,master52 就是这个 NameNode2。
| 抽象主机名 | 实际操作主机名 | 初始状态 | 理想稳定状态 |
|---|---|---|---|
| NameNode1 | master5 | standby | active |
| NameNode2 | master52 | standby | standby |
2.1 获得当前 NameNode 的 active 和 standby 状态
当未启动 ZK 服务时,发现两个 NameNode 都是 standby 的状态,通过以下命令可以查得:hdfs haadmin -getServiceState master5 hdfs haadmin -getServiceState master52
2.2 NameNode 的 active 和 standby 状态切换
根据集群是否已经在 hdfs-site.xml 中设置了dfs.ha.automatic-failover.enabled为 true (即自动故障状态切换)来分两种情况
1. 未设置自动故障切换 (false)
确定要转为 active 状态的主机名,这里将 NameNode1 设为 active,使用命令行工具进行状态切换:
hdfs haadmin -failover --forcefence --forceactive NameNode2 NameNode1
此处 “NameNode2 NameNode1” 的顺序表示 active 状态由 NameNode2 转换到 NameNode1 上(虽然 NameNode2 在转化前也是 standby 状态)。
有时候,当我们系统中 NameNode2 出现故障了,就可以利用上一步中把 NameNode1 的状态切换为active 后,系统自动把 NameNode2 上的 namenode 进程关闭,再把错误原因排除后重启该 namenode进程,启动后该 namenode 状态为 standby,等待下一次 NameNode1 出现故障时即可将 NameNode2 状态切换为 active。
亦或者使用以下命令将 NameNode1 主机上的 namenode 状态切换到 active 或 standby 状态
hdfs haadmin -transitionToActive NameNode1 hdfs haadmin -transitionToStandby NameNode1
但是需要注意的是这两个命令不会尝试运行任何的 fence,因此不应该经常使用。应该更倾向于用
hdfs haadmin -failover命令。
2. 设置自动故障切换 (true)
如果执行下面命令,则会报错
hdfs haadmin -failover --forcefence --forceactive NameNode2 NameNode1
错误信息:
forcefence and forceactive flags not supported with auto-failover enabled.
若要手工切换其中一个 NameNode 节点的 Active 状态改变为 Standby 状态,将另一个 NameNode 节点的 Standby 状态改变为 Active 状态,则可以
kill -9 <pid of NN>来杀死当前 Active 状态的 NameNode 上的 namenode 进程号,此时发现另一个 NameNode 节点就由 Standby 状态改变为 Active 状态,这个时候在重启被杀死进程的 NameNode 上的 namenode 进程,此时就成为了 Standby 状态,切换成功!
假设此时 master52 上 namedode 是 active 状态,而 master5 上 namenode 是 standby 状态,下图呈现了该过程:
另外一种方法就是,关闭当前为 active namenode 状态的上的 DFSZKFailoverController 进程(这个方法可靠性有待考察…)
hadoop-daemon.sh stop zkfc
此时,active 状态的 namenode 立刻更变为 standby 状态,另一个 standby 状态的 nameNode 立刻更变为 active 状态,如下图所示:
当继续关闭了另一个 namenode 的 zkfc 服务之后,它依旧是 active 状态,且两个 namenode 仍然正常工作!
在经过上述之后,master5 的 namenode 变为了 standby ,如果通过它提供的命令转化为 active 会怎样?失败了呗,看英文解释吧…
hdfs haadmin -transitionToActive master5
更多命令可以通过 help 查看,更多详细解释请看 管理员命令
hdfs haadmin -help
其中 checkHealth 检查 NameNode1 的状态。正常就返回 0,否则返回非 0 值。
hdfs haadmin -checkHealth NameNode1
关键人家官网也说了,这个功能还没有实现,现在将总是返回 success,除非给定的 NameNode 完全关闭。
2.3 HDFS HA自动切换比手工切换多出来的步骤
配置文件 core-site.xml 增加了配置项ha.zookeeper.quorum(zk集群的配置)
配置文件 hdfs-site.xml 中把
dfs.ha.automatic-failover.enabled改为true
操作上格式化 zk,执行命令
bin/hdfs zkfc -formatZK
在两个 NameNode 上启动 zkfc,执行命令
sbin/hadoop-daemon.sh start zkfc
三. ResourceManager 的 HA 自动切换命令
说明: 为了更加通俗的说明,笔者将两台运行 resourcemanager 进程的主机名抽象为 RM1 和 RM2,笔者更倾向 RM1 上的运行的是 active 状态的 resourcemanager 进程,RM2 上的运行的是 standby 状态的 resourcemanager 进程,而实际操作中,master5 就是这个 RM1 ,master52 就是这个 RM2。
| 抽象主机名 | 实际操作主机名 | 初始状态 | 理想稳定状态 | ha-id |
|---|---|---|---|---|
| RM1 | master5 | active | active | rm1 |
| RM2 | master52 | standby | standby | rm2 |
hadoop也为管理员提供了 CLI 的方式管理 RM HA,但在没有启用 HA 的情况下,也就是在 yarn-site.xml 配置文件中没有设置
yarn.resourcemanager.ha.enabled为 true 时 (默认为false,不启用),下面的命令是不可用的。
3.1 获得当前 RM 的 active 和 standby 状态
yarn rmadmin -getServiceState rm1 yarn rmadmin -getServiceState rm2
3.2 RM 的 active 和 standby 状态切换
根据集群是否已经在 yarn-site.xml 中设置了yarn.resourcemanager.ha.automatic-failover.enabled为 true (即自动故障状态切换)来分两种情况
1. 未设置自动故障切换 (false)
yarn rmadmin -transitionToStandby rm1 yarn rmadmin -transitionToActive rm2
2. 设置自动故障切换 (true)
yarn rmadmin -transitionToStandby rm1 yarn rmadmin -transitionToActive rm2
显而易见,失败了。如果需要手工切换,这时候可以
kill -9 <pid of RM>杀掉 active 状态的 RM 的 resourcemanager 进程
或关闭 active 状态的 RM 的 resourcemanager 进程
yarn-daemon.sh stop resourcemanager
然后再重启 RM 的 resourcemanager 进程
yarn-daemon.sh start resourcemanager
此时就可以成功切换状态了…
3.3 yarn rmadmin 所支持的命令
更多命令可以通过 help 查看yarn rmadmin -help
其中列出的 -failover 选项,yarn rmadmin 不支持此选项。更多详细解释请看 使用 yarn rmadmin 管理 ResourceManager HA
3.4 YARN HA自动切换比手工切换多出来的步骤
配置文件 yarn-site.xml 中把yarn.resourcemanager.ha.automatic-failover.enabled改为 true。该属性的含义是:是否启用自动故障转移。默认情况下,在启用 HA 时,启用自动故障转移
配置文件 yarn-site.xml 中把
yarn.resourcemanager.ha.automatic-failover.embedded改为 true。启用内置的自动故障转移。默认情况下,在启用 HA 时,启用内置的自动故障转移
四. HDFS HA 故障切换后欲恢复原 active NameNode 步骤
假设原本是 active NameNode 的 master5 的主机因为某种突发情况而失效了,此时之前处于 standby 的 master52 变为了 active 继续承担 namenode 的责任。 一段时间后, master5 恢复正常了,但只能是 standby 的状态。这时若想将 master5 恢复成 active ,该如何做呢?以下是笔者自己总结的,准确性有待商榷…在 Journal 和 QuorumPeerMain 进程正常启动的情况下
将所有的 datanode 进程关闭,将 master5 上的 namenode 进程也关闭
在 master5 上执行
hdfs namenode -bootstrapStandby
再将 master52 上重启 namenode 进程, OK 了

相关文章推荐
- HDFS 用户手册
- Hive,Hbase,HDFS等之间的关系
- Map[Reduce] 的 setup 中读取 HDFS 文件夹信息
- hadoop2.7.1环境搭建
- Flume HDFS Sink使用及源码分析
- client如何访问HA HDFS
- HDFS初步学习的总结
- hdfs目录创建hive表
- HDFS升级和回滚机制
- HDFS的特性和目标
- 使用webhdfs
- [Hive]使用HDFS文件夹数据创建Hive表分区
- Hadoop集群_WordCount运行详解
- Spark将HDFS数据导入到HBase
- HDFS中block块大小设置问题
- hadoop2.7.1不重启,动态删除节点和新增节点
- Using the command line to manage files on HDFS--转载
- FilesystemReader输出HDFS上的文件内容
- HDFS学习笔记之<技巧>
- 递归打印出HDFS上的所有文件夹