列式存储
2015-12-26 13:18
211 查看
一.列式数据库基本概念
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据,以此类推,现在很多数据仓库都是列式数据库,比如infobright,Sybase IQ等
列式存储
=========>
二.与传统数据库的区别
相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理(OLTP)。侧重于联机分析处理的系统(OLAP)就必须在行数据库和列数据库中找到适当得平衡
传统的RDBMS对OLTP的支持,主要是提供数据的增加、删除、修改、查询4种操作,并且保证事务运行的完整性和数据更新优先,这可以视为“写优化”,并非为查询数据而设计的。随着数据量的增大,由于传统RDBMS已经变得无法及时提供查询,因此才有了OLAP的存在。OLAP是面向分析和查询而创建的,专门为了数据读取而设计了“读优化”
三.列式数据库特点
1.高效的存储空间利用率
列式数据库由于其针对不同列的数据特征而发明的不同算法使其往往比行式数据库高的多的压缩率,普通行式3:1到5:1左右,列式是8:1到30:1左右
列式数据库由于其特殊的IO模型所以其数据执行引擎一般不需要索引来完成大量的数据过滤任务,这又额外的减少了数据存储的空间消耗。
列式数据库不需要物化视图,行式数据库为了减少IO 一般会有两种物化视图,常用列的不聚合物化视图和聚合的物化视图。列式数据库本身列是分散储存所以不需要第一种,而由于其他特性使其极为适合做普通聚合操作。
Ps: 物化视图和视图类似,反映的是某个查询的结果。但是和视图仅保存SQL定义不同,物化视图本身会存储数据,因此是物化了的视图。
2.不可见索引
列式数据库由于其数据的每一列都按照选择性进行排序,所以并不需要行式数据库里面的索引来减少IO和更快的查找值的分布情况。
如下图所示: 当数据库执行引擎进行where 条件过滤的时候。只要它发现任何一列的数据不满足特定条件,整个block 的数据就都被丢弃。最后初步的过滤只会扫描可能满足条件的数据块。
3.数据迭代 (Tuple Iteration)
现在的多核CPU 提供的L2缓存在短时间执行同一个函数很多次的时候能更好的利用CPU的二级缓存和多核并发的特性。而行式数据库由于其数据混在一起没法对一个数组进行同一个简单函数的调用,所以其执行效率没有列式数据库高。
Ps:L2缓存位于CPU与内存之间的临时存储器,容量比内存小但交换速度快,二级缓存容量大小决定了cpu的性能。
4.压缩算法
由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。列式数据库由于其每一列都是分开储存的。所以很容易针对每一列的特征运用不同的压缩算法。常见的列式数据库压缩算法有Run Length Encoding , Data Dictionary , Delta Compression , BitMap Index , LZO , Null Compression 等等。根据不同的特征进行的压缩效率从10W:1 到10:1 不等。而且数据越大其压缩效率的提升越为明显。
5.延迟物化
列式数据库由于其特殊的执行引擎,在数据中间过程运算的时候一般不需要解压数据而是以指针代替运算,直到最后需要输出完整的数据时。
Ps:列式数据库是将同一个数据列的各个值存放在一起。插入某个数据行时,该行的各个数据列的值也会存放到不同的地方。列式数据库不是万能的,每次读取某个数据行时,需要分别从不同的地方读取各个数据列的值,然后合并在一起形成数据行。因此,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列式数据库并不适用。
四.列式数据库的优缺点
1.列式数据库优点
极高的装载速度(最高可以等于所有硬盘IO的总和,基本是极限了)
适合大量的数据而不是小数据
实时加载数据仅限于增加(删除和更新需要解压缩Block 然后计算然后重新压缩储存)
高效的压缩率,不仅节省储存空间也节省计算内存和CPU。
非常适合做聚合操作。
2.列式数据库缺点
不适合扫描小量数据
不适合随机的更新
批量更新情况各异,有的优化的比较好的列式数据库(比如Vertica)表现比较好有些没有针对更新的数据库表现比较差。
不适合做含有删除和更新的实时操作。
五.列式数据库中使用的索引
1.块级粗粒度索引(infobright)
顾名思义,就是把数据分块,对块建立索引而不是对条目建立.块级索引一般都是粗粒度的.下图就是infobright的块级索引示意图.
可以看出,它每个数据块的块索引记录该块数据的最大值和最小值,这样查询时,根据条件,就可以判断符合条件的数据是否命中该数据块,而且,如果进行max,sum等聚合操作,可以直接从块索引读取数据而不用读取块内数据.
2.reduced B+树
在OLTP数据库中的B+树,因为数据需要频繁更新插入,在B+树数据块中往往需要留有冗余空间,用来防止B+树的节点空间不足导致B+树的分裂.而列式数据库因为一般都是批量导入数据,数据插入更新操作少,所以可以在导入数据时用自底向上的方法创建B+树,同时可以缩小B+树数据块中的冗余空间,使得B+树更加紧凑.
3. 位图索引
位图索引一般建立在列的cardinality(基数)比较低的情况下.比如性别属性只有男和女,那么这个列的cardinality就是2.这样的列适合用来建立位图索引
4.sybase的一种位图索引
从上面可以看出,位图索引一般用来存储cardinality比较小的数据,而且往往不能进行范围查找,比如大于小于之类.不过sybase有一项专利,用位向量存储索引,仍然可以支持大于运算符
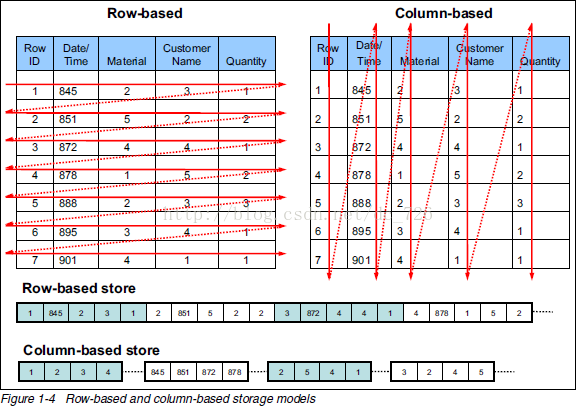
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。
所以它们就有了如下这些优缺点:
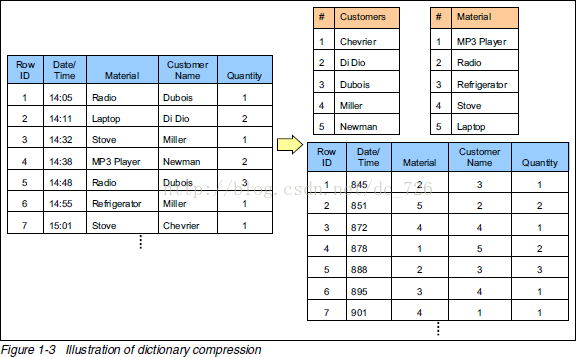
下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化Normalize和Denomalize)
下面就是最牛的图了,通过一条查询的执行过程说明列式存储(以及数据压缩)的优点:
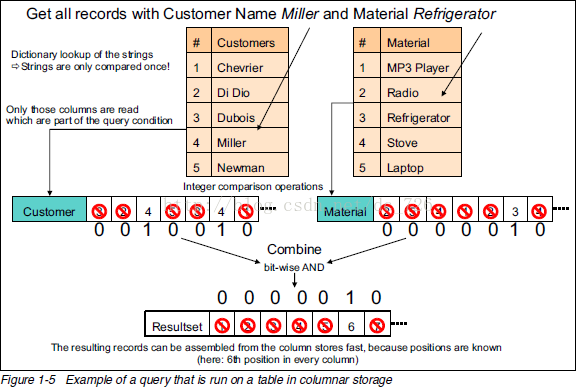
关键步骤如下:
1. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
2. 用数字去列表里匹配,匹配上的位置设为1。
3. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
4. 使用这个下标组装出最终的结果集。
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据,以此类推,现在很多数据仓库都是列式数据库,比如infobright,Sybase IQ等
列式存储
=========>
二.与传统数据库的区别
相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理(OLTP)。侧重于联机分析处理的系统(OLAP)就必须在行数据库和列数据库中找到适当得平衡
传统的RDBMS对OLTP的支持,主要是提供数据的增加、删除、修改、查询4种操作,并且保证事务运行的完整性和数据更新优先,这可以视为“写优化”,并非为查询数据而设计的。随着数据量的增大,由于传统RDBMS已经变得无法及时提供查询,因此才有了OLAP的存在。OLAP是面向分析和查询而创建的,专门为了数据读取而设计了“读优化”
三.列式数据库特点
1.高效的存储空间利用率
列式数据库由于其针对不同列的数据特征而发明的不同算法使其往往比行式数据库高的多的压缩率,普通行式3:1到5:1左右,列式是8:1到30:1左右
列式数据库由于其特殊的IO模型所以其数据执行引擎一般不需要索引来完成大量的数据过滤任务,这又额外的减少了数据存储的空间消耗。
列式数据库不需要物化视图,行式数据库为了减少IO 一般会有两种物化视图,常用列的不聚合物化视图和聚合的物化视图。列式数据库本身列是分散储存所以不需要第一种,而由于其他特性使其极为适合做普通聚合操作。
Ps: 物化视图和视图类似,反映的是某个查询的结果。但是和视图仅保存SQL定义不同,物化视图本身会存储数据,因此是物化了的视图。
2.不可见索引
列式数据库由于其数据的每一列都按照选择性进行排序,所以并不需要行式数据库里面的索引来减少IO和更快的查找值的分布情况。
如下图所示: 当数据库执行引擎进行where 条件过滤的时候。只要它发现任何一列的数据不满足特定条件,整个block 的数据就都被丢弃。最后初步的过滤只会扫描可能满足条件的数据块。
3.数据迭代 (Tuple Iteration)
现在的多核CPU 提供的L2缓存在短时间执行同一个函数很多次的时候能更好的利用CPU的二级缓存和多核并发的特性。而行式数据库由于其数据混在一起没法对一个数组进行同一个简单函数的调用,所以其执行效率没有列式数据库高。
Ps:L2缓存位于CPU与内存之间的临时存储器,容量比内存小但交换速度快,二级缓存容量大小决定了cpu的性能。
4.压缩算法
由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。列式数据库由于其每一列都是分开储存的。所以很容易针对每一列的特征运用不同的压缩算法。常见的列式数据库压缩算法有Run Length Encoding , Data Dictionary , Delta Compression , BitMap Index , LZO , Null Compression 等等。根据不同的特征进行的压缩效率从10W:1 到10:1 不等。而且数据越大其压缩效率的提升越为明显。
5.延迟物化
列式数据库由于其特殊的执行引擎,在数据中间过程运算的时候一般不需要解压数据而是以指针代替运算,直到最后需要输出完整的数据时。
Ps:列式数据库是将同一个数据列的各个值存放在一起。插入某个数据行时,该行的各个数据列的值也会存放到不同的地方。列式数据库不是万能的,每次读取某个数据行时,需要分别从不同的地方读取各个数据列的值,然后合并在一起形成数据行。因此,如果每次查询涉及的数据量较小或者大部分查询都需要整行的数据,列式数据库并不适用。
四.列式数据库的优缺点
1.列式数据库优点
极高的装载速度(最高可以等于所有硬盘IO的总和,基本是极限了)
适合大量的数据而不是小数据
实时加载数据仅限于增加(删除和更新需要解压缩Block 然后计算然后重新压缩储存)
高效的压缩率,不仅节省储存空间也节省计算内存和CPU。
非常适合做聚合操作。
2.列式数据库缺点
不适合扫描小量数据
不适合随机的更新
批量更新情况各异,有的优化的比较好的列式数据库(比如Vertica)表现比较好有些没有针对更新的数据库表现比较差。
不适合做含有删除和更新的实时操作。
五.列式数据库中使用的索引
1.块级粗粒度索引(infobright)
顾名思义,就是把数据分块,对块建立索引而不是对条目建立.块级索引一般都是粗粒度的.下图就是infobright的块级索引示意图.
可以看出,它每个数据块的块索引记录该块数据的最大值和最小值,这样查询时,根据条件,就可以判断符合条件的数据是否命中该数据块,而且,如果进行max,sum等聚合操作,可以直接从块索引读取数据而不用读取块内数据.
2.reduced B+树
在OLTP数据库中的B+树,因为数据需要频繁更新插入,在B+树数据块中往往需要留有冗余空间,用来防止B+树的节点空间不足导致B+树的分裂.而列式数据库因为一般都是批量导入数据,数据插入更新操作少,所以可以在导入数据时用自底向上的方法创建B+树,同时可以缩小B+树数据块中的冗余空间,使得B+树更加紧凑.
3. 位图索引
位图索引一般建立在列的cardinality(基数)比较低的情况下.比如性别属性只有男和女,那么这个列的cardinality就是2.这样的列适合用来建立位图索引
4.sybase的一种位图索引
从上面可以看出,位图索引一般用来存储cardinality比较小的数据,而且往往不能进行范围查找,比如大于小于之类.不过sybase有一项专利,用位向量存储索引,仍然可以支持大于运算符
从上图可以很清楚地看到,行式存储下一张表的数据都是放在一起的,但列式存储下都被分开保存了。
所以它们就有了如下这些优缺点:
| | 行式存储 | 列式存储 |
| 优点 | Ø 数据被保存在一起 Ø INSERT/UPDATE容易 | Ø 查询时只有涉及到的列会被读取 Ø 投影(projection)很高效 Ø 任何列都能作为索引 |
| 缺点 | Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 | Ø 选择完成时,被选择的列要重新组装 Ø INSERT/UPDATE比较麻烦 |
数据压缩
下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化Normalize和Denomalize)下面就是最牛的图了,通过一条查询的执行过程说明列式存储(以及数据压缩)的优点:
关键步骤如下:
1. 去字典表里找到字符串对应数字(只进行一次字符串比较)。
2. 用数字去列表里匹配,匹配上的位置设为1。
3. 把不同列的匹配结果进行位运算得到符合所有条件的记录下标。
4. 使用这个下标组装出最终的结果集。

相关文章推荐
- 自定义圆角点击变色TextView
- 2015年总结
- 感想之二
- 利用Service完成桌面的悬浮窗口
- Fragment使用总结
- leetcode98---Validate Binary Search Tree
- SVN使用教程说明
- 马哥linux学习笔记:centos7.x中rpm命令详解
- [EN] TensorFlow Examples
- 3083: 遥远的国度
- Java基础学习总结(1)——equals方法
- Java基础学习总结(1)——equals方法
- 一种开放平台代理访问方法及装置
- [BZOJ1006]神奇的国度
- Leetcode: Walls and Gates
- 25个Java机器学习工具&库
- 线程池相关
- [Hadoop] Hadoop 链式任务 : ChainMapper and ChainReducer的使用
- 个人博客作业week1
- sudo找不到命令:修改sudo的PATH路径