Pike学习笔记
2015-12-22 11:41
323 查看
Pike的安装(Ubuntu环境)
pike的语法非常像C++,但是它也是脚本语言,所以具有一般脚本语言的特性。一个简单的pike程序,hello world:
string的用法,及命令行参数的例子:
再看看下面段小代码,会觉得更加熟悉:
不过map就不是C++中的map了,而是一个用于简单地代替for的函数,类似于python中的map。
值得注意的是,0在pike中代表NULL,None,也代表int 0。所有没有初始化的变量都将被置为0,这点需要特别注意。当然,也可以将只声明,未初始化的变量看成是一个值未确定的变量。
可以看到,H前面的0并不是我们需要的。
pike的内置类型有:int, float, string ,mapping ,multiset ,array (数组) ,mixed (表任意类型) 。
有点奇怪的是,在声明变量时还可以使变量是某几种数据类型,比如声明:
表示的是,x可以是这3种类型中的一种,但不允许是其他的类型。此时不用mixed的原因是,解释器会对x作参数类型的检查。
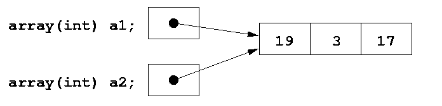
普通变量的赋值通常是a1=a2,但是array的赋值就不能这样了,这倒是和python的list的赋值一样,其实是一个引用,而不是一份拷贝。
正确的做法是:
另一种是:
这种复制是递归式的,连array内的任何数据都能copy到一份独立的出来。
其实只有这三种情况下,赋值才是真的作拷贝工作,那就是:
int
float
string
其他大部分情况都是以引用的方式来解决的。
类的定义也很有不同,首先是构造函数,是以create为函数名的,且最多只能有一个构造函数,当然,也可以没有构造函数。
成员函数中不允许有同名函数的出现,即不能以参数的个数或类型来区别方法,比如只能有一个称为eat的函数存在。
析构函数也是可以存在的,必须称为destroy。destroy比较少用,因为pike是自带垃圾回收的,所以析不析构意义不大。
很不幸,pike中并没有如struct关键字,而仅有class。用class同样也能代替struct的,只要不在class中定义方法即可。
继承 - - 关键字inherit的用法:
在pike中,一个文件其实就是一个类class,全局变量就是类的成员变量,而函数就是成员函数。可以想想成pike解释器自动为每个文件加上了class{}的符号。
导入一个类(即文件)也是很方便的,只需要在函数外引入这句:
其中constant是常量的类型,(program)也可以称为class, 双引号中的内容是文件名。这样子,类名就暂时为constant常量animal,其他的操作就很操作class对象一样了。
pike创建类对象和C++有些不同,还有调用方面,一直是用 -> 符号来取成员变量的。假设fish继承了animal类,看如下代码:
此代码段中创建的是一个fish对象,而指针是基类animal类型的,那么成员函数eat会优先调用fish类中的eat,如果没有定义的话,才调用animal中的eat。如果要调用父类中的成员函数,可以使用::符号来索引出父类,类似于C++中的 "super->" 。
pike称其为dynamic binding,即指针时刻会依赖于具体的对象是什么,而不是仅仅看指针是什么。
注意animal中并没有定义swim,那如果是这样的代码呢:
这里创建的是一个animal,而指针却是派生类的fish指针。虽然这样写前两行并没有错,但在第三行会出错,因为animal中并没有找到这个函数。
更新奇的用法:
因为一个文件就是一个类,而inherit可以用于继承其他类,然后就能直接调用父类的函数了。不过一般不推荐这么作,其实可以创建一个类对象,再调用其中的函数,像这样:
类中的关键字:
整型 int 默认为10进制,理论上支持无限大的数,且保证精确。有几种进制也很重要:
int也有几个常用的操作方法:
浮点型 float 的功能就很有限,支持的精度也比较小,超出的部分自动就被裁剪了,具体怎样裁剪未知。以下有3个比较常用的方法:
pike的内置容器有array,mapping,multiset 。array也是支持切片操作的:
array的 == 操作判断的是是否为同一个array,而不是判断是否内容相等。同理!=符号。
同时,array也有一些常用的操作:
pike的语法非常像C++,但是它也是脚本语言,所以具有一般脚本语言的特性。一个简单的pike程序,hello world:
int main()
{
write("Hello world!\n");
return 0;
}string的用法,及命令行参数的例子:
#! /usr/local/bin/pike //下次直接打文件名就可以了
int main(int argc, array(string) argv)
{
write("Welcome to the Very Simple WWW Browser!\n");
string url;
if(argc == 2)
url = argv[1]; //命令行参数
else
{
write("Type the address of the web page:\n");
url = Stdio.stdin->gets(); //从标准输入中读取一行字符串
}
write("URL: " + url + "\n");
return 0;
}再看看下面段小代码,会觉得更加熟悉:
do
{
write("Type the address of the web page:\n");
url = Stdio.stdin->gets();
} while(sizeof(url) == 0); //简直和C++无差不过map就不是C++中的map了,而是一个用于简单地代替for的函数,类似于python中的map。
void write_one(int x)
{
write("Number: " + x + "\n");
}
int main()
{
array(int) all_of_them = ({ 1, 5, -1, 17, 17 });
map(all_of_them, write_one);
return 0;
}
输出:
Number: 1
Number: 5
Number: -1
Number: 17
Number: 17值得注意的是,0在pike中代表NULL,None,也代表int 0。所有没有初始化的变量都将被置为0,这点需要特别注意。当然,也可以将只声明,未初始化的变量看成是一个值未确定的变量。
string accumulate_answer()
{
string result;
// Probably some code here
result += "Hi!\n";
// More code goes here
return result;
}
输出:
0Hi!可以看到,H前面的0并不是我们需要的。
pike的内置类型有:int, float, string ,mapping ,multiset ,array (数组) ,mixed (表任意类型) 。
有点奇怪的是,在声明变量时还可以使变量是某几种数据类型,比如声明:
int|string|float x
表示的是,x可以是这3种类型中的一种,但不允许是其他的类型。此时不用mixed的原因是,解释器会对x作参数类型的检查。
普通变量的赋值通常是a1=a2,但是array的赋值就不能这样了,这倒是和python的list的赋值一样,其实是一个引用,而不是一份拷贝。
正确的做法是:
a2 = copy_value(a1);
另一种是:
a2 = a1 + ({ });这种复制是递归式的,连array内的任何数据都能copy到一份独立的出来。
其实只有这三种情况下,赋值才是真的作拷贝工作,那就是:
int
float
string
其他大部分情况都是以引用的方式来解决的。
类的定义也很有不同,首先是构造函数,是以create为函数名的,且最多只能有一个构造函数,当然,也可以没有构造函数。
成员函数中不允许有同名函数的出现,即不能以参数的个数或类型来区别方法,比如只能有一个称为eat的函数存在。
析构函数也是可以存在的,必须称为destroy。destroy比较少用,因为pike是自带垃圾回收的,所以析不析构意义不大。
很不幸,pike中并没有如struct关键字,而仅有class。用class同样也能代替struct的,只要不在class中定义方法即可。
class animal
{
string name;
float weight;
void create(string n, float w)
{
name = n;
weight = w;
}
void eat(string food)
{
write(name + " eats some " + food + ".\n");
weight += 0.5;
}
}继承 - - 关键字inherit的用法:
class hamster
{
inherit friend;
void dance()
{
write(name + " dances.\n");
}
}在pike中,一个文件其实就是一个类class,全局变量就是类的成员变量,而函数就是成员函数。可以想想成pike解释器自动为每个文件加上了class{}的符号。
导入一个类(即文件)也是很方便的,只需要在函数外引入这句:
constant animal = (program)"animal.pike";
其中constant是常量的类型,(program)也可以称为class, 双引号中的内容是文件名。这样子,类名就暂时为constant常量animal,其他的操作就很操作class对象一样了。
pike创建类对象和C++有些不同,还有调用方面,一直是用 -> 符号来取成员变量的。假设fish继承了animal类,看如下代码:
animal w = fish("Willy", 4000.0);
w->eat("tourists");
w->swim();此代码段中创建的是一个fish对象,而指针是基类animal类型的,那么成员函数eat会优先调用fish类中的eat,如果没有定义的话,才调用animal中的eat。如果要调用父类中的成员函数,可以使用::符号来索引出父类,类似于C++中的 "super->" 。
pike称其为dynamic binding,即指针时刻会依赖于具体的对象是什么,而不是仅仅看指针是什么。
注意animal中并没有定义swim,那如果是这样的代码呢:
fish f=animal("willy", 300.0);
f->eat("bug");
f->swim();这里创建的是一个animal,而指针却是派生类的fish指针。虽然这样写前两行并没有错,但在第三行会出错,因为animal中并没有找到这个函数。
更新奇的用法:
inherit Stdio.File; read(); //这是Stdio.File中的一个函数
因为一个文件就是一个类,而inherit可以用于继承其他类,然后就能直接调用父类的函数了。不过一般不推荐这么作,其实可以创建一个类对象,再调用其中的函数,像这样:
Stdio.File the_file; the_file->read();
类中的关键字:
public //同C++,在pike中是默认的 private //同C++ static //不同与C++。类似于C++中的protected,能让子类访问。 local //暂没有理解其真实用处 final //禁止子类重定义同样的函数名
整型 int 默认为10进制,理论上支持无限大的数,且保证精确。有几种进制也很重要:
1 十进制: 5 2 二进制: 0b101 3 八进制: 05 4 十六进制: 0x5
int也有几个常用的操作方法:
intp(int x) 判断x是否为int,返回值为0或1 random(int limit) 产生一个[0, limit)的随机整数 reverse(int x) 将x的二进制按位取反
浮点型 float 的功能就很有限,支持的精度也比较小,超出的部分自动就被裁剪了,具体怎样裁剪未知。以下有3个比较常用的方法:
floatp(float x) 判断是否是一个浮点数 floor(float x) 去除x的小数部分,并返回该浮点型 ceil(float x) 向上取整,同样返回的是浮点数
pike的内置容器有array,mapping,multiset 。array也是支持切片操作的:
({ 1, 7, 3, 3, 7 })[ 1..3 ] 相当于 ({ 7, 3, 3 }).array的 == 操作判断的是是否为同一个array,而不是判断是否内容相等。同理!=符号。
array(int) a = ({ 7, 1 });
a==a
true //他们相同
({ 7, 1 }) == ({ 7, 1 })
false //不相同,但相等同时,array也有一些常用的操作:
equal(({7,1}), ({7,1})); 判断两个array是否相等
({ 7, 1, 1 }) + ({ 1, 3 }) 结果为 ({ 7, 1, 1, 1, 3 }). 求并集操作
({ 7, 1 }) | ({ 3, 1 }) 结果为 ({ 7, 3, 1 }). 合并且去重,每个元素的存在个数等于之前某一方数量最多的个数
({ 7, 1 }) & ({ 3, 1 }) 结果为 ({ 1 }). 求交集操作
({ 7, 1 }) - ({ 3, 1 }) 结果为 ({ 7 }). 求差集操作,左边存在的,而右边不存在的
({ 7, 1 }) ^ ({ 3, 1 }) 结果为 ({ 7, 3 }). 求异或集操作
({ 7, 1, 2, 3, 4, 1, 2, 1, 2, 77 }) / ({ 1, 2 }) 结果为 ({ ({ 7 }), ({ 3, 4 }), ({ }), ({ 77 }) }). 求切分操作,就是出现一个({1,2})的话就会出现多一个子数组。
({ 7, 1, 2, 3, 4, 1, 2 }) / 3 结果为 ({ ({ 7, 1, 2 }), ({ 3, 4, 1 }) }). 求切分操作,将array按照每3个为一个新的array来创建一个二重数组,最后如果不足3个就被忽略掉了。
({ 7, 1, 2, 3, 4, 1, 2 }) % 3 结果为 ({ 2 }). 就是上一种切分方法所不足3个的,都给装到一块,所以数量不会超过3的
sizeof(array) 求数组中的元素个数
allocate(size) 一次性创建size个值为0的array
reverse(array) 反转数组
search(haystack, needle) 在haystack中找到第一个出现needle的元素并返回其下标
has_value(haystack, needle) 判断在haystack中谁否有元素needle的存在
replace(array, old, new) 将数组中所有的值为old的元素替换为new

相关文章推荐
- spring-mvc环境搭建及helloworld的demo实现
- JS控制按钮10秒钟后可用的方法
- Unity3D导入MAX文件的一些问题。不断更新。。。
- ZSTUOJ 4212 String Game
- ssh2的整合
- Oracle11g数据库导入Oracle10g问题
- Think In Java 读后感
- HTML5 预览预加载文件,图片
- Hive的那些事儿?
- Xcode7.1以上版本的第三方库的导入解决问号问题
- Mac上eclipse安装SVN+JavaHL
- Linux聊天室项目 -- ChatRome(select实现)
- fusioncharts一个同事使用的饼图包
- 最近遇到的一些错误,以解决,进行记录
- HDU ACM 2586 How far away ?LCA->并查集+Tarjan(离线)算法
- 手机模拟位置实现精准位置营销效果分析
- mysql自定义循环函数
- iOS开发系列--通讯录、蓝牙、内购、GameCenter、iCloud、Passbook系统服务开发汇总
- 分享Android微信红包插件
- mysql数据表中文乱码解决方案