HashMap多线程死循环问题
2015-12-16 22:26
357 查看
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
Put一个Key,Value对到Hash表中:
检查容量是否超标
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
迁移的源代码,注意高亮处:
好了,这个代码算是比较正常的。而且没有什么问题。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
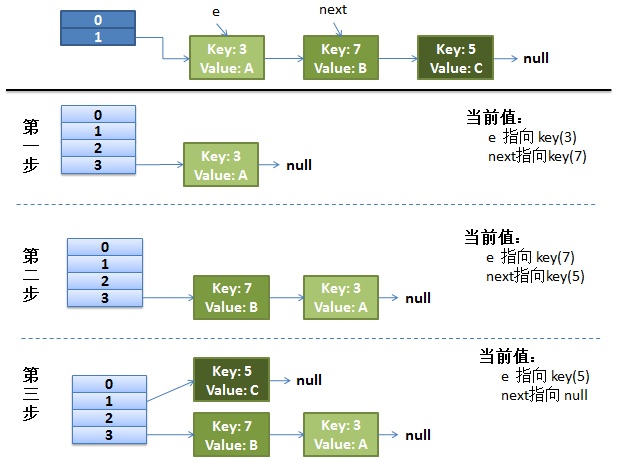
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
我们再回头看一下我们的 transfer代码中的这个细节:
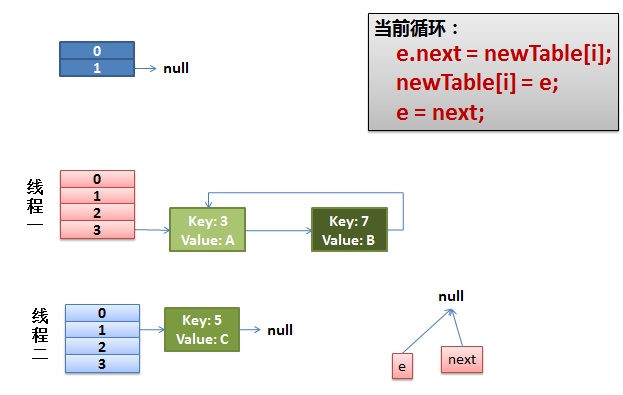
而我们的线程二执行完成了。于是我们有下面的这个样子。
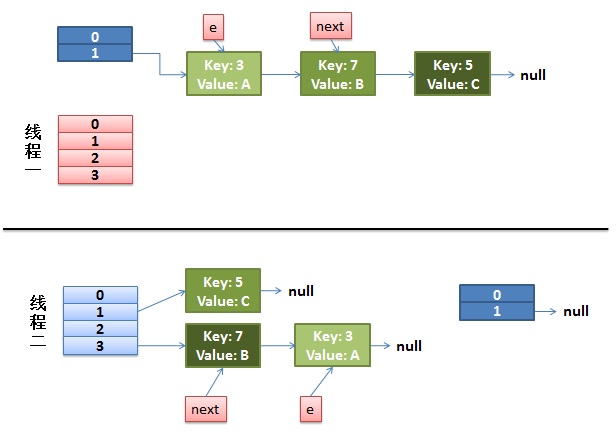
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
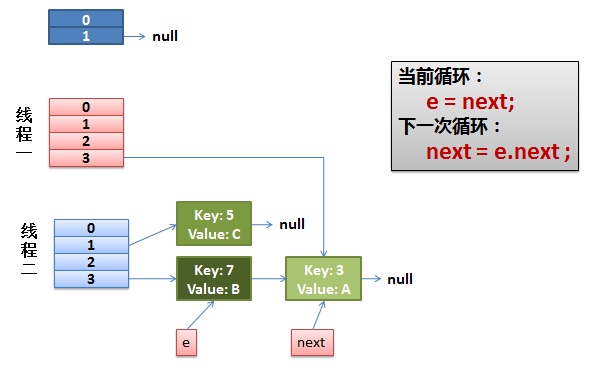
2)线程一被调度回来执行。
先是执行 newTalbe[i] = e;
然后是e = next,导致了e指向了key(7),
而下一次循环的next = e.next导致了next指向了key(3)
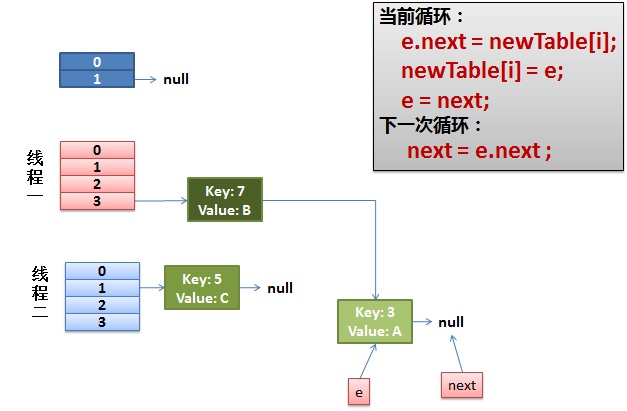
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
HashMap死循环图如下所示:

参见:http://blog.csdn.net/xuefeng0707/article/details/40797085
http://my.oschina.net/xianggao/blog/393990?fromerr=L1pbCT6K
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
正常的ReHash的过程
画了个图做了个演示。我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
先是执行 newTalbe[i] = e;
然后是e = next,导致了e指向了key(7),
而下一次循环的next = e.next导致了next指向了key(3)
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
HashMap死循环图如下所示:
参见:http://blog.csdn.net/xuefeng0707/article/details/40797085
http://my.oschina.net/xianggao/blog/393990?fromerr=L1pbCT6K

相关文章推荐
- Centos 之find详解
- py环境安装
- 几道很有趣的面试题
- 十大最佳PS3游戏推荐
- 【图像处理】颜色空间
- Java并发之(1):volatile关键字(TIJ21-21.3.3 21.3.4)
- C++ 11: function,bind和lambda表达式
- CCF201403-2 窗口
- Java中String为什么被设计成immutable(不可修改的)/final
- 我的代码日志1
- d3力学图(force layout)更新
- mac中使用终端生成RSA私钥和公钥文件
- 插件XAlign的使用
- 兼容性问题
- android 启动界面广告的显示
- JSP复习(一) 基础
- 比较时间和日期大小
- Linux kernel -页高速缓存和页回写 初探
- Stucts应用引起的OutOfMemoryError
- C++中mutable关键的学习