Cassandra监控 - OpsCenter手册
2015-12-15 10:54
836 查看
注:本文转自:http://eric100.blog.51cto.com/2535573/1717792
Opscenter用户手册
添加扩展集群
配置nodes
查看性能指标
修复问题
监控集群情况

2 CPU cores
2 GB of RAM available to OpsCenter
权限和软件环境:
如果希望对配置的values加密,需安装pycryptolibrary
安装JRE或JDK。
建议使用最新版本的浏览器。OpsCenter不支持InternetExplorer和 Microsoft Edge。
Python 2.6+
2.2. 安装步骤
1、下载OpsCenter
$ curl -Lhttp://downloads.datastax.com/community/opscenter.tar.gz | tar xz
文件已包含DataStaxagent。
2、进入opscenterversion_number目录
$ cd opscenter-version_number
3、启动OpsCenter
$ bin/opscenter
注意:使用bin/opscenter –f是在前台启动
4、浏览器打开OpsCenter
http://opscenter-host:8888/
OpsCenter会尝试自动安装agents,如果失败需要在每个节点上手动安装。
JMX连接可用在集群节点上。
SSH可用。
OpsCenter诊断tarball特性需要GNU1.16版本以上。CentOS/RHEL需要6以上。
http://1.2.3.4:8888/
当首次开启OpsCenter,会提示你连接集群:
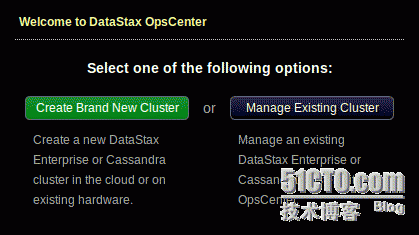
2、点击ManageExisting Cluster,出现Add Cluster对话框。
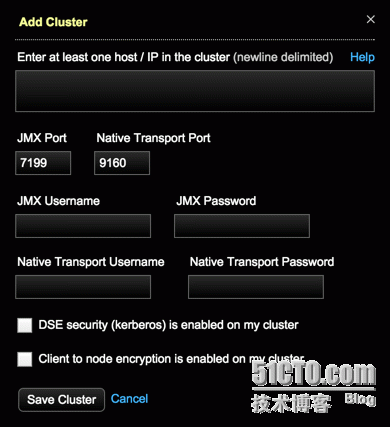
3、在Add Cluster,输入集群节点的Hostnames或IP地址,设置JMX和Native Transport端口号,点击Save Cluster。
OpsCenter连接到集群后,在Dashboard顶部会出现Fix连接。
4、点击Fix连接开始安装agents
5、在Install Node Agent,点击EnterCredentials
6、在Node SSH Credentials,输入username和其他验证信息,点击Done。
7、在Install Node Agent对话框,点击Install on all nodes。
8、如果提示,点击Accept Fingerprint添加节点主机。
如果你不能够通过OpsCenter UI安装agents,请参考手动部署agents。
OpsCenter已经安装。
集群节点JMX可用。
OpsCenter诊断tarball特性需要GNU1.16版本以上。CentOS/RHEL需要6以上。
SYSSTAT工具(用来手机I/O指标,yuminstall –y sysstat)
$ curl -Lhttp://downloads.datastax.com/community/datastax-agent-version_number.tar.gz| tar xz
切入到agent目录
$ cd datastax-agent-version_number
在address.yaml中设置stomp_interface为OpsCenter的IP地址(需要手动创建此文件)
$ echo "stomp_interface:reachable_opscenterd_ip" >> ./conf/address.yaml
如果在opscenterd.conf中开启了SSL,则在address.yaml添加SSL。
$ echo "use_ssl: 1" >>./conf/address.yaml
开启agent
$ bin/datastax-agent
使用-f选项可以运行在前台
安装文件列表如下:
1、启动opscenterd:
$ install_location/bin/opscenter ##使用-f可前台启动
2、停止和重启opscenterd:
找出opscenterd进程ID(pid),kill掉进程
$ ps -ef | grep opscenter
$ sudo kill pid
启动opscenterd:
$ install_location/bin/opscenter ##使用-f可前台启动
1、启动agent:
$ install_location/bin/datastax-agent##使用-f可前台启动
2、停止和重启agent:
l 找出agent进程ID(pid),kill掉进程
$ ps -ef | grep datastax-agent
$ sudo kill pid
启动opscenterd:
$ install_location/bin/ datastax-agent ##使用-f可前台启动
DEBUG (0)
INFO (1)
WARN (2)
ERROR (3)
CRITICAL (4)
ALERT (5)
告警:
可选的,你可以配置OpsCenter发送告警信息对于选中的日志级别。这些告警可以通过邮箱、HTTP提供。默认告警不可用。
告警可以通过OpsCenter API或UI事件促发。比如,nodetool通过命令行执行move操作将不会促发告警,但是通过OpsCenter Nodes > List View > Other Actions > Move将会促发告警
告警包含的信息:
设置enabled为1
提供有效的SMTP的主机、端口号、用户名和密码
提供有效的邮箱地址,to_addr和from_addr。to_addr值为接受告警帐号
可选的:设置发送告警级别。默认为监听所有基本
可选的:自定义发送主题
保存<config_location>/event-plugins/email.conf。重启OpsCenter。
为了发送告警给多个邮箱地址,创建不同的邮箱配置文件,比如email1.conf,email2.conf
注意:OpsCenterconsole是最方便修改配置文件的方式。
opscenterd.conf:配置OpsCenter daemon属性,路径install_location/conf/opscenterd.conf
cluster_name.conf:配置OpsCenter集群监控属性,路径install_location/conf/clusters/cluster_name.conf
address.yaml:配置DataStaxagent属性,路径install_location/conf/address.yaml。
大部分的属性也可以在cluster_name.conf文件中的[agent_config]部分配置。
配置文件优先级:
Opscenter5.2之前版本cluster_name.conf配置优先于address.yaml。Opscenter5.2和之后版本,addresss.yaml优先于cluster_name.conf
[webserver] port
OpsCenter webserver的HTTP连接端口。默认8888。
[webserver] interface
web server监听clientconnections的interface
[webserver] log_path
HTTP交互的日志路径,默认install_location/log/http.log
[logging] level
Opscenter日志级别,可用级别为:TRACE, DEBUG, INFO, WARN, ERROR。默认INFO
[logging] log_path
OpsCenter日志路径,默认install_location/log/opscenterd.log。

从主菜单访问OpsCenter以下功能:
New Cluster – 创建一个新的cluster或添加已经存在的cluster。
Alerts – 配置告警阀值。只有DataStax Enterprise可用
Settings – 访问编辑ClusterConnections和User Roles:
Cluster Connections – 修改集群设置或移除集群
Users & Roles – 管理用户基于角色认证
Help – OpsCenter资源信息
5.1.2. 导航菜单

Overview – 提供OpsCenter实例的集群概览。
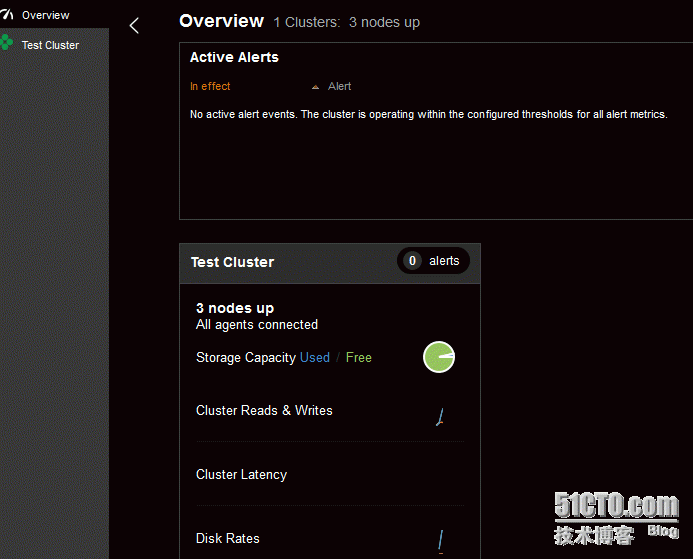
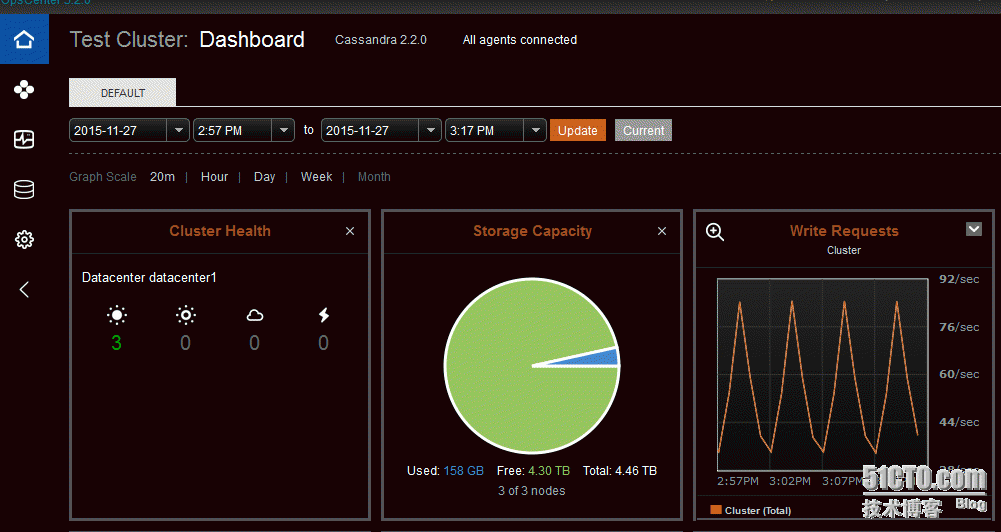
Dashboard –查看OpsCenter集群信息,监控Cassandra集群性能指标。
Nodes – 从不同的角度查看集群(Ring or List View),执行集群节点的维护操作

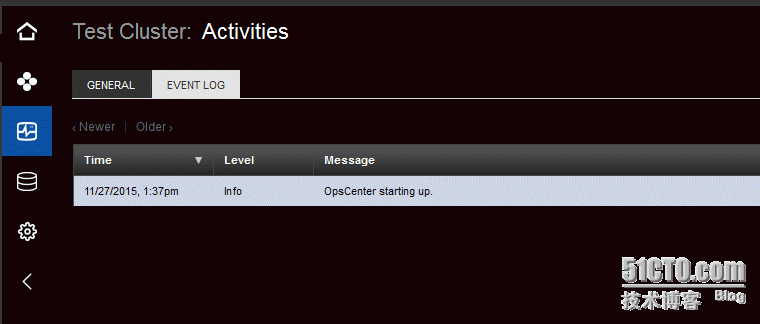
Activities – 展示集群运行的任务,查看OpsCenter日志事件,比如在Eventlog中的OpsCenter启动停止。查看Spark jobs状态。查看那Hadoop Jobs状态。
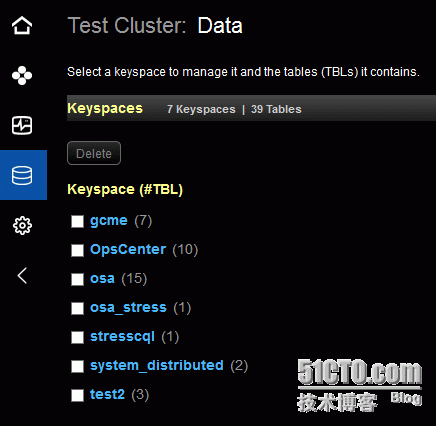
Data – 管理keyspaces和tables
Services - DataStax Enterprise管理服务
5.2. 节点监控和管理
5.2.1. Ring View
Ring View展示了集群节点作为ring的节点,可以从此诊断节点健康,数据分布等。点击cluster > Nodes> Ring,访问Ring View
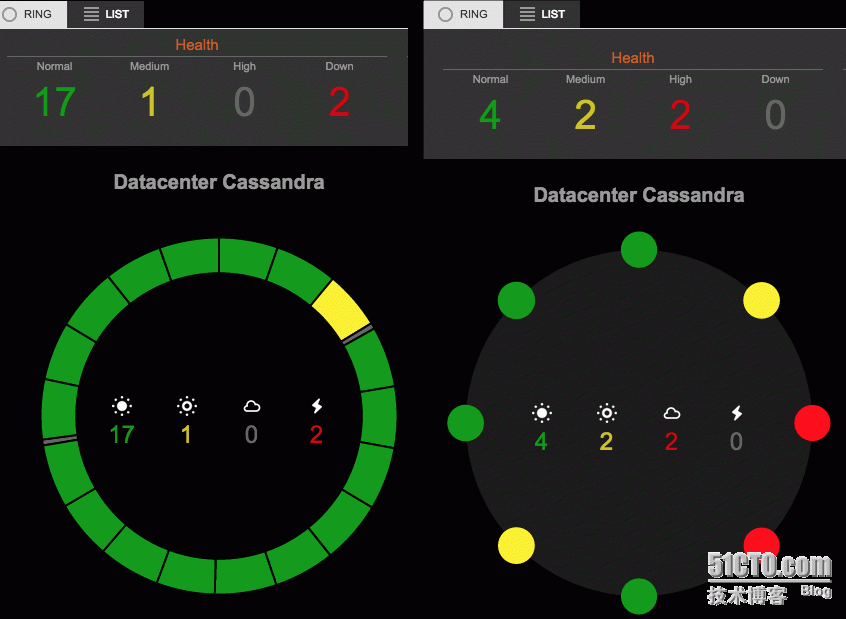
Ring view解释:
健康概览。监控图标从左到右:Normal,Medium,High load,节点down
颜色表示节点健康状态,由系统负载决定。0–0.999为Normal (green),1–5 Medium (yellow),5+ High (red),down(gray)
节点详情:
鼠标悬浮在节点上,将会展示节点详情。详情是实时更新的。
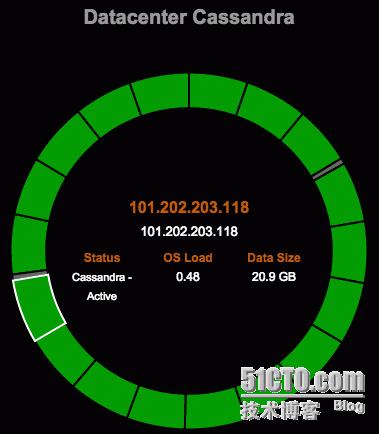
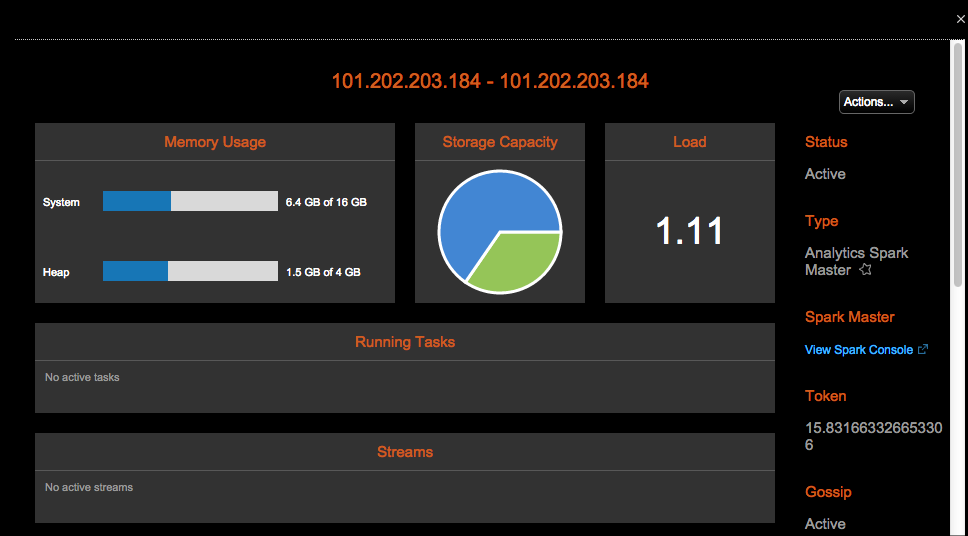
点击节点,将会展示节点详情的对话框,展示更多的信息。使用Actions菜单可以在节点上运行多种操作。
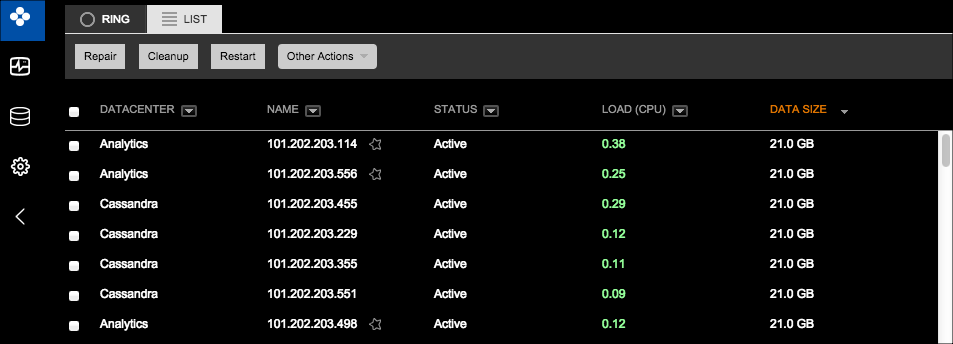
点击cluster > Nodes > Listtab,访问List View
查看节点详情:
点击节点,将会展示节点详情的对话框,展示更多的信息。使用Actions菜单可以在节点上运行多种操作。

可以选择指标,生成监控图形
2、Configure
可以配置修改选中节点的cassandra.yaml文件
3、Start/Stop
启动或停止Cassandra进程。
4、Restart
重启Cassandra进程
5、Cleanup
移除节点的rows
6、Compact
执行压缩操作,在大部分Cassandra集群不建议操作。
7、Flush
将内存中的数据(memtables)flush到磁盘(SSTables)
8、Repair
修复副本数据的不一致性。
9、Perform GC
强制JVM执行GC操作
10、Drain
使当前写操作存储在memtables中的数据flush到SSTables,并使此节点变为只读。节点将不再接受新的写入操作。Drain一般用于升级节点。
1、点击左边导航窗口中的Data。展示Keyspaces列表

2、选择Keyspaces列表中的一个keyspace

3、在keyspace settings中,点击Edit

4、点击Delete Keyspace,删除keyspace
点击左边导航窗口中的Data。展示Keyspaces列表
选中tables列表中的table,将会展示table的CQL statement

3、其他操作:
l Delete:从keyspace中删除此表
l View Metrics:展示table的指标
l Truncate:删除此表的所有数据
从主菜单上,点击Settings >Cluster Connections

2、点击Delete Cluster
点击ClusterActions菜单中的Restart
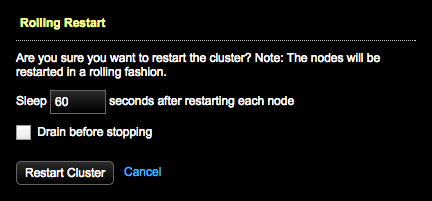
2、设置每个节点重启后等待时间。默认60s
3、可选的:选择是否执行Drain在停止之前。
4、点击Restart Cluster

集群性能指标
Task指标
Table指标
可以展示告警,集群健康和存储容量。
步骤:
1、点击Dashboard
2、点击Add Graph
3、在Add Metric对话框,选择指标
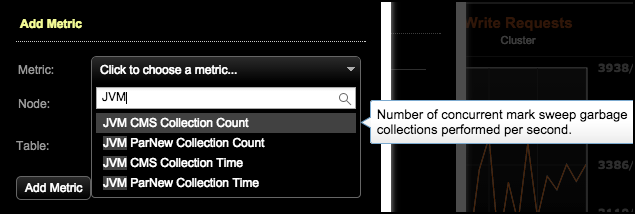
4、选择监控的节点
5、可选的:点击table,选择特定的表
6、点击Add Metric
7、点击Save Graph展示指定的指标图表
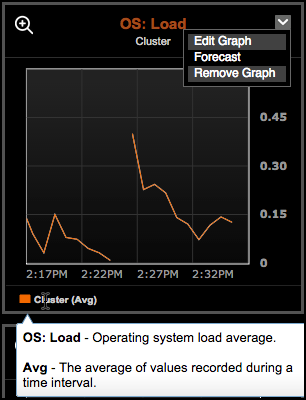
8、点击图标右上角的title,点击Edit Graph可以编辑图表
9、点击Add Widget可以开启和关闭Alerts, Cluster Health和Storage Capacity
1、点击Dashboard
2、点击Clone可以克隆指标图表
3、点击Make Default,设置为默认
4、点击Rename,可以重命名
5、点击Delete,可以删除
编辑opscenterd.conf,重启opscenterd
[labs]
enable_dashboard_preset_import_export = True
步骤:
1、点击Dashboard,点击Export
2、点击Import连接
Cassandra 进程使用Java heapmemory的平均值
WriteRequests
在coordinator节点上每秒的写请求数,类似与client写请求
WriteRequest Latency
Client写响应平均时长(以毫秒为单位)。依赖于consistencylevel和replication factor,也包含了写replicas的网络延迟
Read Requests
在coordinator节点上每秒的读请求数,类似与client读请求
ReadRequest Latency
Client读响应平均时长(以毫秒为单位)。read latency受到硬盘,网络和应用程序读的方式等影响。比如,使用二级索引,读请求数据大小,client需要的consistency level都将影响read latency。I/O的争用也会增加read latency。当SSTables有很多碎片,compaction跟不上写负载则读也会变慢。
JVMCMS Collection Count
JVM每秒并发标记-清除(CMS)垃圾的数量。
JVMCMS Collection Time
CMS垃圾收集时间(ms/sec)
JVMParNew Collection Count
JVM每秒并行执行的新一代垃圾收集的数量
JVMParNew Collection Time
ParNew垃圾收集时间(ms/sec)
DataSize
Cassandra存储数据的大小。建议不超过磁盘的70%,留一些空间维护compaction和repair操作。
Totalbytes compacted
SSTable每秒数据压缩的字节数
Totalcompactions
每秒压缩的数量
Flush进程flush memtables到SSTables。这个指标展示了flushmemtables队列的数量。最优数量为0(或较少数量)。值大于0表示有I/O竞争,降低了磁盘性能
Repl.(Replicate) on Write TasksPending (复制等待任务指标)
当插入或修改一行时,此行将会复制到其他节点。调用的是ReplicateOnWriteStage。这个指标跟踪了写进程阶段。在一个低或适中的写负载时,你应该看到0 pending replicate在写任务上(或比较低的数字)。持续的高值表示需要检查下磁盘I/O或网络连接问题
到达集群等待处理的读请求的数量。在一个低或适中的写负载时,你应该看到0 pending read在写任务上(或比较低的数字)。持续的高值表示需要检查下磁盘I/O或网络连接问题。Pending reads也可能表示应用设计没有以有效的方式来访问数据
ReadRepair Tasks Pending
读修复操作队列,等待系统资源的数量。最优数量为0(或比较低的数字)。值大于0表示读修复操作与其他操作存在I/O竞争。对于表来说,降低此table参数read_repair_chance,你需要容忍一定程度的旧数据。
CompactionsPending
Compactions队列的数量,等待系统资源。最优数量为0(或比较低的数字)。值大于0表示读操作与compaction操作竞争I/O连接,表示读性能下降。这种情况常常是由于执行频繁的small writes和持久的reads。如果一个节点或集群展示了pending compactions,表示你可能需要增大I/O能力,通过添加节点到集群。你也可以减少I/O连接,通过减少插入/更新请求(比如批量写入)。或则减少SSTables创建的数量,通过增大memtable大小,flush频率。
Repair操作数量。Repair是一个资源敏感操作,需要执行:比较副本间的数据,发送改变的row到副本来保证数据的一致性,删除过期的tombstones,重建索引和bloom filters。跟踪这个指标的状态可以帮助你确定repaire操作的过程。它常常不会出现很大的值。
Gossiptasks pending
Cassandra使用gossip协议来发现其他节点的位置和状态信息。每个节点每秒发送一次gossip,与其他节点交换状态信息。Gossip tasks pending表示gossip messages等待发送或接受的数量。最优数量为0(或比较低的数字)。值大于0表示网络可能有问题。
Hintedhandoff pending
当一个节点offline,其他节点在节点不可用期间将会保存rows更新的提示。当节点重新online,它对应的副本将会修复。hinted handoff pending指标表示等待发送给failed节点hints的数量。查看这个指标可以确定failed节点数据是否恢复。Hinted handoff是Cassandra可选的功能。Hints可以配置保存周期(默认1小时)。
Miscellaneoustasks pending
系统修改schema后的等待任务数量。Schema修改需要传播给所有的节点,所以这个指标能够表示schema 不一致的错误。
表的写负载。指标包含所有的写请求到此table,包含来自其他节点的写请求。
TBL:Local Write Latency
成功写入表后的响应事件,单位毫秒。writelatency受到硬盘,网络和写入性质影响(比如consistency levels)
TBL:Write Latency (Stacked)
写数据的响应事件,包含min,median, max, 90%和99%
TBL:Local Reads
读负载
TBL:Local Read Latency
成功读取数据后的响应事件
ReadLatency (Stacked)
读数据的响应事件,包含min, median, max, 90%和99%
TBL:Live Disk Used
存活的SSTables使用的磁盘空间,不包含过时的SSTables
TBL:Total Disk Used
SSTables使用的磁盘空间,包含过时的SSTables
TBL:SSTable Count
SSTables当前数量
TBL:SSTables per Read (Stacked)
读取多少SSTables:包含min,median, max, 90%和99%
TBL:Cell Count
表在分区中存在多少个cells:包含min,median, max, 90%和99%
TBL:Partition Size
表的分区大小:包含min, median,max, 90%和99%
TBL:Pending Reads/Writes
表的读写等待数量。
TBL:Bloom Filter Space Used
bloomfilter文件在磁盘的大小。
TBL:Bloom Filter False Positives
bloom filter误报的数量,比如bloomfilter表示row存在,但实际上不存在的数量
TBL:Bloom Filter False Positive Ratio
bloomfilter误报的百分比
TBL:Bloom Filter Off Heap
bloomfilters使用的heap memory
TBL:Index Summary Off Heap
索引使用的heapmemory
TBL:Compression Metadata Off Heap
compressionmetadata使用的heap memory
TBL:Memtable Off Heap
表当前的memtable使用的heapmemory
TBL:Total Memtable Size
所有的memtables使用内存的空间
TBL:Key Cache Requests
在row key cache读请求的数量
TBL:Key Cache Hits
在row keycache读请求命中的数量
TBL:Key Cache Hit Rate
在row keycache读请求命中的比率
TBL:Row Cache Requests
在row key cache读请求的数量,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:Row Cache Hits
在row key cache读请求命中的数量,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:Row Cache Hit Rate
在row key cache读请求命中的比率,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:SSTable Size
表当前SSTables当前大小
展示系统内存的使用:cached,buffered和free
OS:CPU
系统和用户进程使用CPU的时间
OS:Load
系统work数量
OS:Disk usage (GB)
Cassandra使用磁盘空间
OS:Disk Usage (percentage)
Cassandra使用磁盘空间的百分比
OS:Disk Throughput
读写操作的百分比,通过测量每秒的MB
OS:Disk Rates
磁盘对于读写操作的平均速度
OS:Disk Latency
磁盘查找消耗的平均时间,单位毫秒
OS:Disk Request Size
请求的平均大小
OS:Disk Queue Size
请求队列的平均数量,对于磁盘延迟问题
OS:Disk Utilization
磁盘I/O消耗CPU时间的百分比
Opscenter用户手册
1. OpsCenter简介
DataStaxOpsCenter是一个可视化管理和监控Apache Cassandra和DataStax Enterprise工具。OpsCenter简化了管理任务:添加扩展集群
配置nodes
查看性能指标
修复问题
监控集群情况
主要功能
OpsCenter主要功能如下:1.2. OpsCenter架构概览
通过Cassandra和DataStaxEnterprise安装DataStax agents。Agents使用Java Management Extensions (JMX)来监控管理每个node。2. 安装OpsCenter
2.1. 准备
最小的硬件环境:2 CPU cores
2 GB of RAM available to OpsCenter
权限和软件环境:
如果希望对配置的values加密,需安装pycryptolibrary
安装JRE或JDK。
建议使用最新版本的浏览器。OpsCenter不支持InternetExplorer和 Microsoft Edge。
Python 2.6+
2.2. 安装步骤
1、下载OpsCenter$ curl -Lhttp://downloads.datastax.com/community/opscenter.tar.gz | tar xz
文件已包含DataStaxagent。
2、进入opscenterversion_number目录
$ cd opscenter-version_number
3、启动OpsCenter
$ bin/opscenter
注意:使用bin/opscenter –f是在前台启动
4、浏览器打开OpsCenter
http://opscenter-host:8888/
3. 安装DataStax agents
通过OpsCenter添加完集群之后,会在Dashboard上显示agents状态。OpsCenter会尝试自动安装agents,如果失败需要在每个节点上手动安装。
3.1. 前置条件
Root或sudo安装agents。JMX连接可用在集群节点上。
SSH可用。
OpsCenter诊断tarball特性需要GNU1.16版本以上。CentOS/RHEL需要6以上。
3.2. 步骤
1、打开浏览器,访问http://opscenter_host:8888http://1.2.3.4:8888/
当首次开启OpsCenter,会提示你连接集群:
2、点击ManageExisting Cluster,出现Add Cluster对话框。
3、在Add Cluster,输入集群节点的Hostnames或IP地址,设置JMX和Native Transport端口号,点击Save Cluster。
OpsCenter连接到集群后,在Dashboard顶部会出现Fix连接。
4、点击Fix连接开始安装agents
5、在Install Node Agent,点击EnterCredentials
6、在Node SSH Credentials,输入username和其他验证信息,点击Done。
7、在Install Node Agent对话框,点击Install on all nodes。
8、如果提示,点击Accept Fingerprint添加节点主机。
3.3. 结果
DataStax agents已经被安装部署到集群节点上。如果你不能够通过OpsCenter UI安装agents,请参考手动部署agents。
3.4. 手动部署agents
3.4.1. 前置条件
Cassandra或DataStax Enterprise集群正在运行。OpsCenter已经安装。
集群节点JMX可用。
OpsCenter诊断tarball特性需要GNU1.16版本以上。CentOS/RHEL需要6以上。
SYSSTAT工具(用来手机I/O指标,yuminstall –y sysstat)
3.4.2. 步骤
下载DataStax agent tarball$ curl -Lhttp://downloads.datastax.com/community/datastax-agent-version_number.tar.gz| tar xz
切入到agent目录
$ cd datastax-agent-version_number
在address.yaml中设置stomp_interface为OpsCenter的IP地址(需要手动创建此文件)
$ echo "stomp_interface:reachable_opscenterd_ip" >> ./conf/address.yaml
如果在opscenterd.conf中开启了SSL,则在address.yaml添加SSL。
$ echo "use_ssl: 1" >>./conf/address.yaml
开启agent
$ bin/datastax-agent
使用-f选项可以运行在前台
3.5. OpsCenter 参考
3.5.1. OpsCenter 和DataStax agent端口号
| 端口号 | 描述 |
| OpsCenter端口号 | |
| 8888 | OpsCenter web地址端口。Opscenterd监听来自浏览器的HTTP端口号,在opscenterd.conf中配置。 |
| 50031 | OpsCenter对于Job Tracker的HTTP代理端口。Opscenterd进程监听浏览器查看Hadoop Job Tracker页面的HTTP端口号,在opscenterd.conf中配置(只支持DataStax Enterprise) |
| 61620 | OpsCenter监控端口号。Opscenterd进程监听来自agent的TCP交互。在opscenterd.conf中配置。 |
| DataStax agent端口号 | |
| 7199 | JMX监控端口号。每个agent节点会打开一个JMX连接 |
| 8012 | Hadoop Job Tracker client端口号(只支持DataStax Enterprise) |
| 8012 | Hadoop Job Tracker website端口号(只支持DataStax Enterprise) |
| 8012 | Hadoop Task Tracker website端口号(只支持DataStax Enterprise) |
| 9042 | native transport端口号,在cassandra.yaml中配置的native_transport_port |
| 61621 | DataStax agent端口号 |
| 22 | SSH端口号。在opscenterd.conf中配置。 |
| Solr和Demo applications端口号 | |
| 8983 | Solr端口号和Demo applications端口号 |
| LDAP服务端口号 | |
| 389 | 非SSL LDAP和AD默认端口号。在opscenterd.conf中配置。 |
| 636 | SSL LDAP和AD默认端口号。在opscenterd.conf中配置。 |
3.5.2. 安装配置路径
3.5.2.1. 非服务tarball安装默认文件路径
文件路径与tarball安装路径相同。安装文件列表如下:
| Directory | Location |
| /agent | Agent安装文件 |
| /bin | 启动和配置二进制命令 |
| /content | Web应用文件 |
| /conf | 配置文件 |
| /doc | License文件 |
| /lib and /src | Library文件 |
| /log | OpsCenter日志文件 |
| /ssl | agent交互的SSL文件 |
3.5.3. 启动,停止和重启OpsCenter
非服务tarball步骤:1、启动opscenterd:
$ install_location/bin/opscenter ##使用-f可前台启动
2、停止和重启opscenterd:
找出opscenterd进程ID(pid),kill掉进程
$ ps -ef | grep opscenter
$ sudo kill pid
启动opscenterd:
$ install_location/bin/opscenter ##使用-f可前台启动
3.5.4. 启动和重启DataStax agents
非服务tarball安装方式步骤:1、启动agent:
$ install_location/bin/datastax-agent##使用-f可前台启动
2、停止和重启agent:
l 找出agent进程ID(pid),kill掉进程
$ ps -ef | grep datastax-agent
$ sudo kill pid
启动opscenterd:
$ install_location/bin/ datastax-agent ##使用-f可前台启动
4. 配置
4.1. 配置事件告警
在Activities展示了OpsCenterEvent日志页面,包含事件和告警列表。下面的列表展示了事件日志级别:DEBUG (0)
INFO (1)
WARN (2)
ERROR (3)
CRITICAL (4)
ALERT (5)
告警:
可选的,你可以配置OpsCenter发送告警信息对于选中的日志级别。这些告警可以通过邮箱、HTTP提供。默认告警不可用。
告警可以通过OpsCenter API或UI事件促发。比如,nodetool通过命令行执行move操作将不会促发告警,但是通过OpsCenter Nodes > List View > Other Actions > Move将会促发告警
告警包含的信息:
| Field | Description | Example |
| api_source_ip | 发送请求的原IP地址 | 67.169.50.240 |
| target_node | STREAMING操作的目的地址 | 10.1.1.11 |
| event_source | 事件产生的组件 | OpsCenter (i.e., restart, start) |
| user | 事件产生的OpsCenter user | opscenter_user |
| time | 事件时间 | 1311025650414527 |
| action | 事件类型 | 20 |
| subject | 邮件告警主题 | [WARN] OpsCenter Event - Node reported as being down: 127.0.0.1 |
| message | 事件描述 | Garbage Collecting node 10.1.1.13 |
| level | 日志级别的数值 | 1 |
| source_node | 事件发生的原节点 | 10.1.1.13 |
| level_str | 事件日志级别 | INFO |
4.1.1. 开启邮箱告警
为了启动邮箱告警,需要编辑<config_location>/event-plugins/email.conf文件并提供可用的SMTPserver host和port信息。4.1.1.1. 前置条件
确保你拥有可用的SMTP帐号可以收发告警。4.1.1.2. 步骤
在OpsCenter主机上打开email.conf文件设置enabled为1
提供有效的SMTP的主机、端口号、用户名和密码
提供有效的邮箱地址,to_addr和from_addr。to_addr值为接受告警帐号
可选的:设置发送告警级别。默认为监听所有基本
可选的:自定义发送主题
保存<config_location>/event-plugins/email.conf。重启OpsCenter。
为了发送告警给多个邮箱地址,创建不同的邮箱配置文件,比如email1.conf,email2.conf
4.1.1.3. 案例
[email]
# set to 1 to enable email
enabled=1
# levels can be comma delimited list of any of the following:
# DEBUG,INFO,WARN,ERROR,CRITICAL,ALERT
# If left empty, will listen for all levels
levels=WARN
smtp_host=smtp.gmail.com
smtp_port=465
smtp_user=mercury@gmail.com
smtp_pass=*********
smtp_use_ssl=1
smtp_use_tls=0
smtp_retries=1
smtp_timeout=5
to_addr=cassandra_admin@acme.com
from_addr=mercury@gmail.com
# Customizable subject for email. The key specified in {}'s must map to the items provided in json map at the end of
# the emails. For example, some available keys are:
# node, cluster, datetime, level_str, message, target_node, event_source, success, api_source_ip, user, source_node
# more advanced formatting options explained here: https://docs.python.org/2/library/string.html#formatspec subject=[{level_str}] OpsCenter Event on {cluster} - {message}4.2. 配置文件
配置能力,可以修改opscenterd.conf,cluster_name.conf和address.yaml配置文件。注意:OpsCenterconsole是最方便修改配置文件的方式。
opscenterd.conf:配置OpsCenter daemon属性,路径install_location/conf/opscenterd.conf
cluster_name.conf:配置OpsCenter集群监控属性,路径install_location/conf/clusters/cluster_name.conf
address.yaml:配置DataStaxagent属性,路径install_location/conf/address.yaml。
大部分的属性也可以在cluster_name.conf文件中的[agent_config]部分配置。
配置文件优先级:
Opscenter5.2之前版本cluster_name.conf配置优先于address.yaml。Opscenter5.2和之后版本,addresss.yaml优先于cluster_name.conf
4.2.1. opscenterd.conf配置文件
注意修改文件属性后,需要重启Opscenter才能生效。[webserver] port
OpsCenter webserver的HTTP连接端口。默认8888。
[webserver] interface
web server监听clientconnections的interface
[webserver] log_path
HTTP交互的日志路径,默认install_location/log/http.log
[logging] level
Opscenter日志级别,可用级别为:TRACE, DEBUG, INFO, WARN, ERROR。默认INFO
[logging] log_path
OpsCenter日志路径,默认install_location/log/opscenterd.log。
5. OpsCenter使用
5.1. OpsCenter workspace介绍
5.1.1. 主菜单
从主菜单访问OpsCenter以下功能:
New Cluster – 创建一个新的cluster或添加已经存在的cluster。
Alerts – 配置告警阀值。只有DataStax Enterprise可用
Settings – 访问编辑ClusterConnections和User Roles:
Cluster Connections – 修改集群设置或移除集群
Users & Roles – 管理用户基于角色认证
Help – OpsCenter资源信息
5.1.2. 导航菜单
Overview – 提供OpsCenter实例的集群概览。
Dashboard –查看OpsCenter集群信息,监控Cassandra集群性能指标。
Nodes – 从不同的角度查看集群(Ring or List View),执行集群节点的维护操作
Activities – 展示集群运行的任务,查看OpsCenter日志事件,比如在Eventlog中的OpsCenter启动停止。查看Spark jobs状态。查看那Hadoop Jobs状态。
Data – 管理keyspaces和tables
Services - DataStax Enterprise管理服务
5.2. 节点监控和管理
5.2.1. Ring View
Ring View展示了集群节点作为ring的节点,可以从此诊断节点健康,数据分布等。点击cluster > Nodes> Ring,访问Ring ViewRing view解释:
健康概览。监控图标从左到右:Normal,Medium,High load,节点down
颜色表示节点健康状态,由系统负载决定。0–0.999为Normal (green),1–5 Medium (yellow),5+ High (red),down(gray)
节点详情:
鼠标悬浮在节点上,将会展示节点详情。详情是实时更新的。
点击节点,将会展示节点详情的对话框,展示更多的信息。使用Actions菜单可以在节点上运行多种操作。
5.2.2. List View
List View是RingView另一种展示。List View提供了当查看数据时,更快的访问和更多的灵活性。所有数据都是实时更新的。点击cluster > Nodes > Listtab,访问List View
查看节点详情:
点击节点,将会展示节点详情的对话框,展示更多的信息。使用Actions菜单可以在节点上运行多种操作。
5.2.3. 节点管理操作
5.2.3.1. 管理单个节点
从List View或Ring View点击节点,从Actions菜单中选择action5.2.3.2. 操作详情
1、View Metrics可以选择指标,生成监控图形
2、Configure
可以配置修改选中节点的cassandra.yaml文件
3、Start/Stop
启动或停止Cassandra进程。
4、Restart
重启Cassandra进程
5、Cleanup
移除节点的rows
6、Compact
执行压缩操作,在大部分Cassandra集群不建议操作。
7、Flush
将内存中的数据(memtables)flush到磁盘(SSTables)
8、Repair
修复副本数据的不一致性。
9、Perform GC
强制JVM执行GC操作
10、Drain
使当前写操作存储在memtables中的数据flush到SSTables,并使此节点变为只读。节点将不再接受新的写入操作。Drain一般用于升级节点。
5.3. 管理keyspaces和tables
5.3.1. 管理keyspaces
步骤:1、点击左边导航窗口中的Data。展示Keyspaces列表
2、选择Keyspaces列表中的一个keyspace
3、在keyspace settings中,点击Edit
4、点击Delete Keyspace,删除keyspace
5.3.2. 管理tables
步骤:点击左边导航窗口中的Data。展示Keyspaces列表
选中tables列表中的table,将会展示table的CQL statement
3、其他操作:
l Delete:从keyspace中删除此表
l View Metrics:展示table的指标
l Truncate:删除此表的所有数据
5.4. 集群管理
5.4.1. 删除集群
步骤:从主菜单上,点击Settings >Cluster Connections
2、点击Delete Cluster
5.4.2. 重启集群
步骤:点击ClusterActions菜单中的Restart
2、设置每个节点重启后等待时间。默认60s
3、可选的:选择是否执行Drain在停止之前。
4、点击Restart Cluster
5.4.3. 产生PDF报告
点击Help >Report将产生集群监控PDF报告5.5. 性能指标
5.5.1. 使用性能指标
选择Dashboard查看指标类型:集群性能指标
Task指标
Table指标
5.5.1.1. 创建和编辑性能图
图标可以在一个单元中包含多个指标。比如,一个图标可以包含CPU和磁盘的利用率,读写请求和系统负载。可以展示告警,集群健康和存储容量。
步骤:
1、点击Dashboard
2、点击Add Graph
3、在Add Metric对话框,选择指标
4、选择监控的节点
5、可选的:点击table,选择特定的表
6、点击Add Metric
7、点击Save Graph展示指定的指标图表
8、点击图标右上角的title,点击Edit Graph可以编辑图表
9、点击Add Widget可以开启和关闭Alerts, Cluster Health和Storage Capacity
5.5.1.2. 分组设置性能指标
步骤:1、点击Dashboard
2、点击Clone可以克隆指标图表
3、点击Make Default,设置为默认
4、点击Rename,可以重命名
5、点击Delete,可以删除
5.5.1.3. 导出导出dashboard
Dashboard导出导入为JSON文件编辑opscenterd.conf,重启opscenterd
[labs]
enable_dashboard_preset_import_export = True
步骤:
1、点击Dashboard,点击Export
2、点击Import连接
5.5.2. 集群性能指标
CassandraJVM memory usageCassandra 进程使用Java heapmemory的平均值
WriteRequests
在coordinator节点上每秒的写请求数,类似与client写请求
WriteRequest Latency
Client写响应平均时长(以毫秒为单位)。依赖于consistencylevel和replication factor,也包含了写replicas的网络延迟
Read Requests
在coordinator节点上每秒的读请求数,类似与client读请求
ReadRequest Latency
Client读响应平均时长(以毫秒为单位)。read latency受到硬盘,网络和应用程序读的方式等影响。比如,使用二级索引,读请求数据大小,client需要的consistency level都将影响read latency。I/O的争用也会增加read latency。当SSTables有很多碎片,compaction跟不上写负载则读也会变慢。
JVMCMS Collection Count
JVM每秒并发标记-清除(CMS)垃圾的数量。
JVMCMS Collection Time
CMS垃圾收集时间(ms/sec)
JVMParNew Collection Count
JVM每秒并行执行的新一代垃圾收集的数量
JVMParNew Collection Time
ParNew垃圾收集时间(ms/sec)
DataSize
Cassandra存储数据的大小。建议不超过磁盘的70%,留一些空间维护compaction和repair操作。
Totalbytes compacted
SSTable每秒数据压缩的字节数
Totalcompactions
每秒压缩的数量
5.5.3. Pending任务指标
Pending tasks常常是由缺少集群资源引起,比如磁盘带宽,网络带宽和内存。5.5.3.1. Pending task metrics forwrites(写等待任务指标)
FlushesPendingFlush进程flush memtables到SSTables。这个指标展示了flushmemtables队列的数量。最优数量为0(或较少数量)。值大于0表示有I/O竞争,降低了磁盘性能
Repl.(Replicate) on Write TasksPending (复制等待任务指标)
当插入或修改一行时,此行将会复制到其他节点。调用的是ReplicateOnWriteStage。这个指标跟踪了写进程阶段。在一个低或适中的写负载时,你应该看到0 pending replicate在写任务上(或比较低的数字)。持续的高值表示需要检查下磁盘I/O或网络连接问题
5.5.3.2. Pending task metrics forreads(读等待任务指标)
ReadRequests Pending到达集群等待处理的读请求的数量。在一个低或适中的写负载时,你应该看到0 pending read在写任务上(或比较低的数字)。持续的高值表示需要检查下磁盘I/O或网络连接问题。Pending reads也可能表示应用设计没有以有效的方式来访问数据
ReadRepair Tasks Pending
读修复操作队列,等待系统资源的数量。最优数量为0(或比较低的数字)。值大于0表示读修复操作与其他操作存在I/O竞争。对于表来说,降低此table参数read_repair_chance,你需要容忍一定程度的旧数据。
CompactionsPending
Compactions队列的数量,等待系统资源。最优数量为0(或比较低的数字)。值大于0表示读操作与compaction操作竞争I/O连接,表示读性能下降。这种情况常常是由于执行频繁的small writes和持久的reads。如果一个节点或集群展示了pending compactions,表示你可能需要增大I/O能力,通过添加节点到集群。你也可以减少I/O连接,通过减少插入/更新请求(比如批量写入)。或则减少SSTables创建的数量,通过增大memtable大小,flush频率。
5.5.3.3. Pending task metrics forcluster operations(集群操作等待任务指标)
Manualrepair tasks pendingRepair操作数量。Repair是一个资源敏感操作,需要执行:比较副本间的数据,发送改变的row到副本来保证数据的一致性,删除过期的tombstones,重建索引和bloom filters。跟踪这个指标的状态可以帮助你确定repaire操作的过程。它常常不会出现很大的值。
Gossiptasks pending
Cassandra使用gossip协议来发现其他节点的位置和状态信息。每个节点每秒发送一次gossip,与其他节点交换状态信息。Gossip tasks pending表示gossip messages等待发送或接受的数量。最优数量为0(或比较低的数字)。值大于0表示网络可能有问题。
Hintedhandoff pending
当一个节点offline,其他节点在节点不可用期间将会保存rows更新的提示。当节点重新online,它对应的副本将会修复。hinted handoff pending指标表示等待发送给failed节点hints的数量。查看这个指标可以确定failed节点数据是否恢复。Hinted handoff是Cassandra可选的功能。Hints可以配置保存周期(默认1小时)。
Miscellaneoustasks pending
系统修改schema后的等待任务数量。Schema修改需要传播给所有的节点,所以这个指标能够表示schema 不一致的错误。
5.5.4. Table性能指标
TBL:Local Writes表的写负载。指标包含所有的写请求到此table,包含来自其他节点的写请求。
TBL:Local Write Latency
成功写入表后的响应事件,单位毫秒。writelatency受到硬盘,网络和写入性质影响(比如consistency levels)
TBL:Write Latency (Stacked)
写数据的响应事件,包含min,median, max, 90%和99%
TBL:Local Reads
读负载
TBL:Local Read Latency
成功读取数据后的响应事件
ReadLatency (Stacked)
读数据的响应事件,包含min, median, max, 90%和99%
TBL:Live Disk Used
存活的SSTables使用的磁盘空间,不包含过时的SSTables
TBL:Total Disk Used
SSTables使用的磁盘空间,包含过时的SSTables
TBL:SSTable Count
SSTables当前数量
TBL:SSTables per Read (Stacked)
读取多少SSTables:包含min,median, max, 90%和99%
TBL:Cell Count
表在分区中存在多少个cells:包含min,median, max, 90%和99%
TBL:Partition Size
表的分区大小:包含min, median,max, 90%和99%
TBL:Pending Reads/Writes
表的读写等待数量。
TBL:Bloom Filter Space Used
bloomfilter文件在磁盘的大小。
TBL:Bloom Filter False Positives
bloom filter误报的数量,比如bloomfilter表示row存在,但实际上不存在的数量
TBL:Bloom Filter False Positive Ratio
bloomfilter误报的百分比
TBL:Bloom Filter Off Heap
bloomfilters使用的heap memory
TBL:Index Summary Off Heap
索引使用的heapmemory
TBL:Compression Metadata Off Heap
compressionmetadata使用的heap memory
TBL:Memtable Off Heap
表当前的memtable使用的heapmemory
TBL:Total Memtable Size
所有的memtables使用内存的空间
TBL:Key Cache Requests
在row key cache读请求的数量
TBL:Key Cache Hits
在row keycache读请求命中的数量
TBL:Key Cache Hit Rate
在row keycache读请求命中的比率
TBL:Row Cache Requests
在row key cache读请求的数量,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:Row Cache Hits
在row key cache读请求命中的数量,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:Row Cache Hit Rate
在row key cache读请求命中的比率,这个指标只是展示配置的row caching(row caching默认不可用)
TBL:SSTable Size
表当前SSTables当前大小
5.5.5. 操作系统性能指标
OS:Memory展示系统内存的使用:cached,buffered和free
OS:CPU
系统和用户进程使用CPU的时间
OS:Load
系统work数量
OS:Disk usage (GB)
Cassandra使用磁盘空间
OS:Disk Usage (percentage)
Cassandra使用磁盘空间的百分比
OS:Disk Throughput
读写操作的百分比,通过测量每秒的MB
OS:Disk Rates
磁盘对于读写操作的平均速度
OS:Disk Latency
磁盘查找消耗的平均时间,单位毫秒
OS:Disk Request Size
请求的平均大小
OS:Disk Queue Size
请求队列的平均数量,对于磁盘延迟问题
OS:Disk Utilization
磁盘I/O消耗CPU时间的百分比

相关文章推荐
- 查看linux中某个端口(port)是否被占用(netstat,lsof)
- 网站中使用中文个性字库字体--@font-face解决方案探索 l(转)
- Nginx 优化思路
- e.preventDefault 和 e.stopPropagation
- 在Linux集群上安装和配置Spark
- centos 6.5 x64编译有python的vim7.4 - yantze
- Hadoop及RHadoop的初步尝试
- 实时应用监控平台cat——服务器启动流程(一)
- Tomcat下直接通过ip访问自己的项目
- linux reboot flow
- CentOS学习笔记之<虚拟机能ping通同一网关的其他机器,ping不通主机>
- centos6 安装 docker
- CentOS6.5安装MATLAB
- openoffice转pdf错误
- Linux服务器开发初步
- maven项目使用外部tomcat7并进行远程热部署
- 用vi修改文件,保存文件时,提示“readonly option is set”的解决方法
- Pandas:SettingWithCopyWarning
- linux dup,dup2,dup3 复制一个文件描述符
- 采用dlopen、dlsym、dlclose加载动态链接库