机器学习--K-means算法(聚类,无监督学习)
2015-12-15 10:35
323 查看
一、基本思想
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集
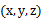
。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
二、算法步骤
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
三、代码实现(matlab)
四、k-means 和EM 的关系思考
K-means来说就是我们一开始不知道每个样例
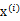
对应隐含变量也就是最佳类别

。最开始可以随便指定一个

给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的
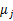
(前面提到的其他未知参数),然而此时发现,可以有更好的
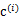
(质心与样例

距离最小的类别)指定给样例
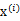
,那么
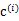
得到重新调整,上述过程就开始重复了,直到没有更好的

指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量

,M步更新其他参数
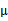
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集

。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
二、算法步骤
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为 。 2、 重复下面过程直到收敛 { 对于每一个样例i,计算其应该属于的类  对于每一个类j,重新计算该类的质心  } |
四、k-means 和EM 的关系思考
K-means来说就是我们一开始不知道每个样例

对应隐含变量也就是最佳类别

。最开始可以随便指定一个

给它,然后为了让P(x,y)最大(这里是要让J最小),我们求出在给定c情况下,J最小时的

(前面提到的其他未知参数),然而此时发现,可以有更好的

(质心与样例

距离最小的类别)指定给样例

,那么

得到重新调整,上述过程就开始重复了,直到没有更好的

指定。这样从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量

,M步更新其他参数

来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。

相关文章推荐
- accept是又产生一个Socket端口吗?
- 多线程
- 在CMD下用java命令出现“找不到或无法加载主类”问题
- [SQL] 1153 – Got a packet bigger than ‘max_allowed_packet’ bytes
- 最简单的cxf restful webservice Demo(包括与spring集成)
- why use aftermarket parts
- (十一)swift 使用SQLite
- 你得知道这3个最基础的APP技术框架
- 如何在Spring容器中加载自定义的配置文件
- [转]"由于这台计算机没有远程桌面客户端访问许可证,远程会话被中断"的解决方案
- 动态分配内存补充 realloc
- 【转】eclipse luna 无法安装veloeclipse问题
- TweenMax参数说明
- 关于使用base36的技巧 生成 优惠券兑换码的相关讨论
- iOS开发中善用日志记录工具
- CSS高级选择器:nth-child()应用大全
- JavaScriptc创建对象的几种模式
- 一些简单的硬件知识
- 杭电ACM1564(奇偶规律)
- 【重拾】nodeJS模块查找