HashMap源码分析
2015-12-14 22:06
267 查看
最近看见不少文章提到HashMap 源码, 这里就来具体分析一下HashMap源码
首先HashMap 继承自AbstractMap
当然还有equals方法
接着是HashMap的构造方法
参数很简单,初始容量,和加载因子。初始容量定义了初识数组的大小,加载因子和初始容量的乘积确定了一个阈值。阈值最大是(1<<30) + 1。初始容量一定是2的N次方,而且刚刚比要设置的值大。默认初始容量是16,默认加载因子是0.75。当表中的元素数量大于等于阈值时,数组的容量会翻倍,并重新插入元素到新的数组中,由于数组长度发生了改变,所以元素的位置肯定发生变化 所以HashMap不保证顺序恒久不变。当输入的加载因子小于零或者不是浮点数时会抛出异常(IllegalArgumentException)。
接下来是put操作:
putAll:
putAll 方法里面是调用 putMapEntries 来完成put操作的
可知,上述方法主要是对传入的map进行遍历,在for方法中调用putVal方法来存入数据
putVal():
这个是8.0的代码,貌似在7.0的基础上做了一些修改,首先,如果当前tab是空的话就对它进行初始化
4000
,这里初始化大小用到了resize()方法,可以看出resize()方法在这里不止用于当元素达到阈值的时候双倍当前数组的大小,还兼备了初始化的功能,接下来,如果当前hash值所在的位置如果为空,就新创建一个节点newNode(hash,key,value,null);之后就是正常的处理,如果当前hash所在位置有值,且key值相同,就直接替换,如果key值不相同就在当前节点.next 节点来创建,最后通过判断e是否为空来取得oldValue 还有通过判断 binCount 是否大于阈值
当符合(p instanceof TreeNode)这个条件的时候,把链表变成treemap,这样查找效率从o(n)变成了o(log n) 还有原先resize()方法里的transfer方法也没有了,直接合并到resize方法中去了.
添加Node:
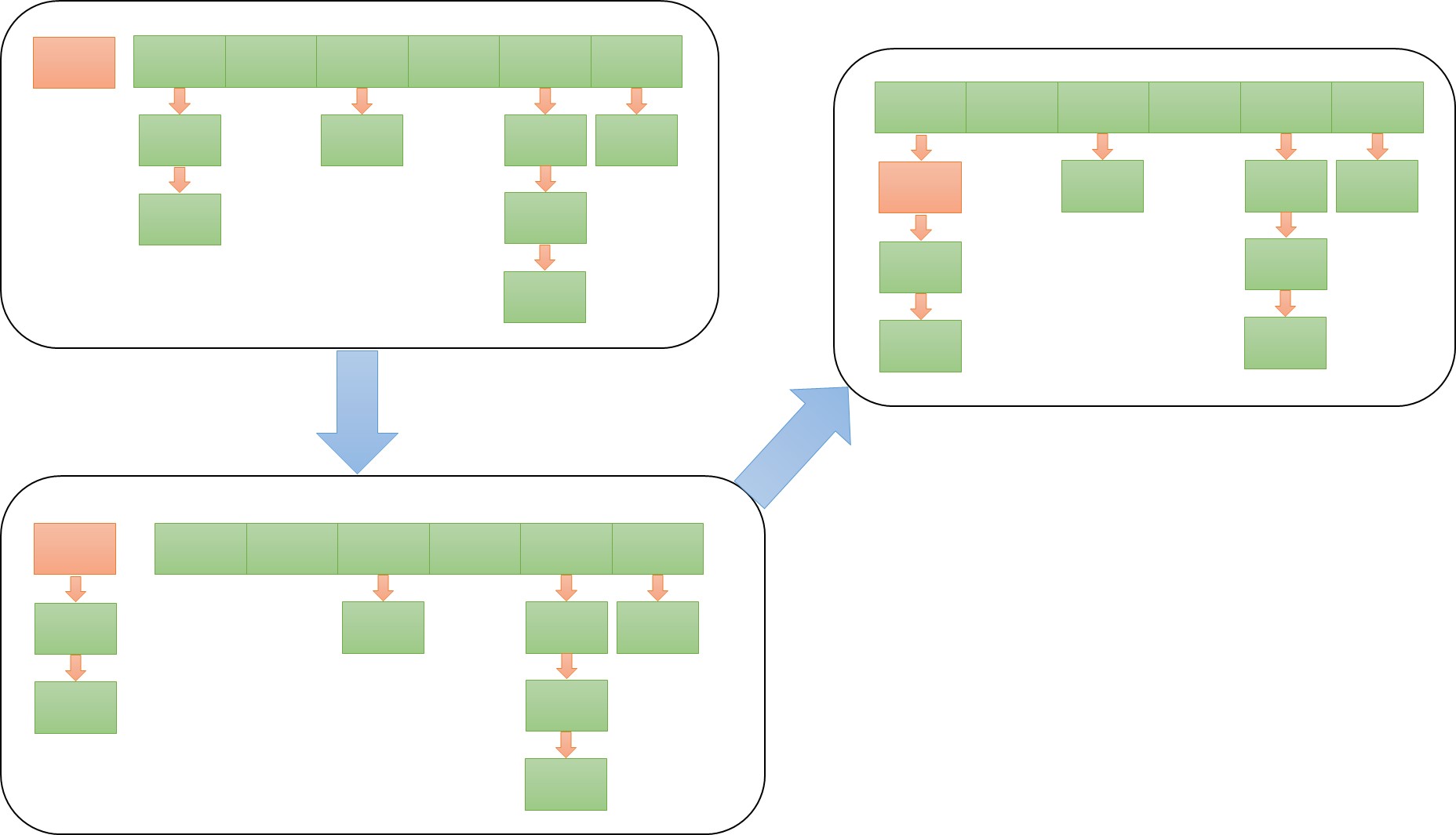
图片来自:http://androidperformance.com/2015/08/05/HashMap.html
containsValue相对来说没有什么变化,都是遍历数组取值比较,remove相对做了removeTreeNode的流程,跟put一样get也与之前差不多,没有进行什么特别的算法优化,
removeNode:
可见 removeNode与PutVal方法结构上十分相近,在这里不赘述
另外
返回集合的方法大体结构都是通过构造内部类的方法来返回的 example: keyset ,values Entrykey
暂时就这样。。。
首先HashMap 继承自AbstractMap
public final int hashCode() {
return Objects.hashCode(key)^Objects.hashCode(value);
}当然还有equals方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}接着是HashMap的构造方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}参数很简单,初始容量,和加载因子。初始容量定义了初识数组的大小,加载因子和初始容量的乘积确定了一个阈值。阈值最大是(1<<30) + 1。初始容量一定是2的N次方,而且刚刚比要设置的值大。默认初始容量是16,默认加载因子是0.75。当表中的元素数量大于等于阈值时,数组的容量会翻倍,并重新插入元素到新的数组中,由于数组长度发生了改变,所以元素的位置肯定发生变化 所以HashMap不保证顺序恒久不变。当输入的加载因子小于零或者不是浮点数时会抛出异常(IllegalArgumentException)。
接下来是put操作:
putAll:
putAll 方法里面是调用 putMapEntries 来完成put操作的
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}可知,上述方法主要是对传入的map进行遍历,在for方法中调用putVal方法来存入数据
putVal():
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这个是8.0的代码,貌似在7.0的基础上做了一些修改,首先,如果当前tab是空的话就对它进行初始化
4000
,这里初始化大小用到了resize()方法,可以看出resize()方法在这里不止用于当元素达到阈值的时候双倍当前数组的大小,还兼备了初始化的功能,接下来,如果当前hash值所在的位置如果为空,就新创建一个节点newNode(hash,key,value,null);之后就是正常的处理,如果当前hash所在位置有值,且key值相同,就直接替换,如果key值不相同就在当前节点.next 节点来创建,最后通过判断e是否为空来取得oldValue 还有通过判断 binCount 是否大于阈值
当符合(p instanceof TreeNode)这个条件的时候,把链表变成treemap,这样查找效率从o(n)变成了o(log n) 还有原先resize()方法里的transfer方法也没有了,直接合并到resize方法中去了.
添加Node:
图片来自:http://androidperformance.com/2015/08/05/HashMap.html
containsValue相对来说没有什么变化,都是遍历数组取值比较,remove相对做了removeTreeNode的流程,跟put一样get也与之前差不多,没有进行什么特别的算法优化,
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}removeNode:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}可见 removeNode与PutVal方法结构上十分相近,在这里不赘述
另外
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
--------
public Collection<V> values() {
Collection<V> vs;
return (vs = values) == null ? (values = new Values()) : vs;
}
final class Values extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<V> iterator() { return new ValueIterator(); }
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
--------
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new EntrySet()) : es;
}
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return new EntrySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}返回集合的方法大体结构都是通过构造内部类的方法来返回的 example: keyset ,values Entrykey
暂时就这样。。。

相关文章推荐
- 从源码安装Mysql/Percona 5.5
- c语言实现hashmap(转载)
- 浅析Ruby的源代码布局及其编程风格
- asp.net 抓取网页源码三种实现方法
- JS小游戏之仙剑翻牌源码详解
- JS小游戏之宇宙战机源码详解
- jQuery源码分析之jQuery中的循环技巧详解
- 本人自用的global.js库源码分享
- java中原码、反码与补码的问题分析
- 解析WeakHashMap与HashMap的区别详解
- hashCode方法的使用讲解
- PHP网页游戏学习之Xnova(ogame)源码解读(六)
- C#获取网页HTML源码实例
- PHP网页游戏学习之Xnova(ogame)源码解读(八)
- PHP网页游戏学习之Xnova(ogame)源码解读(四)
- 基于Java HashMap的死循环的启示详解
- Java中HashMap和Hashtable的区别浅析
- 重载toString实现JS HashMap分析
- JS小游戏之极速快跑源码详解
- JS小游戏之象棋暗棋源码详解