How is deep learning different from multilayer perceptron?
2015-12-14 21:08
375 查看
转载至quora
I’m going to try to keep this answer simple - hopefully I don’t leave out too much detail in doing so. To me, the answer is all about the initialization and training process - and this was perhaps the first major breakthrough in deep learning. Like others have said, MLP is not really different than deep learning, but arguably just one type of deep learning.
Back-propagation (which has existed for decades) theoretically allows you to train a network with many layers. But before the advent of deep learning, researchers did not have widespread success training neural networks with more than 2 layers.
This was mostly because of vanishing and/or exploding gradients. Prior to deep learning MLPs were typically initialized using random numbers. Like today, MLPs used the gradient of the network’s parameters w.r.t. to the network’s error to adjust the parameters to better values in each training iteration. In back propagation, to evaluate this gradient involves the chain rule and you must multiply each layer’s parameters and gradients together across all the layers. This is a lot of multiplication, especially for networks with more than 2 layers. If most of the weights across many layers are less than 1 and they are multiplied many times then eventually the gradient just vanishes into a machine-zero and training stops. If most of the parameters across many layers are greater than 1 and they are multiplied many times then eventually the gradient explodes into a huge number and the training process becomes intractable.
Deep learning proposed a new initialization strategy: use a series of single layer networks - which do not suffer from vanishing/exploding gradients - to find the initial parameters for a deep MLP. The pictures below attempt to illustrate this process:
1.) A single layer autoencoder network is used to find initial parameters for the first layer of a deep MLP.
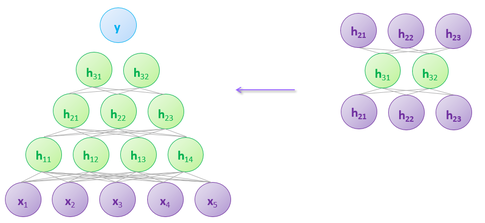
2.) A single layer autoencoder network is used to find initial parameters for the second layer of a deep MLP.
3.) A single layer autoencoder network is used to find initial parameters for the third layer of a deep MLP.
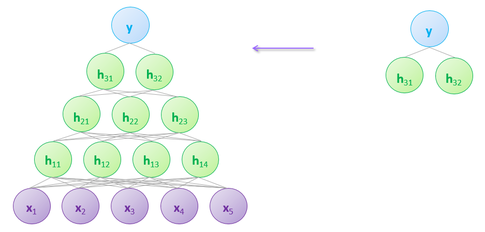
4.) A softmax classifier (logistic regression) is used to find initial parameters for the output layer of a deep MLP.
Now that all the layers have been initialized through this pre-training process to values that are more suitable for the data, you can usually train the deep MLP using gradient descent techniques without the problem of vanishing/exploding gradients.
Of course the field of deep learning has moved forward since this initial breakthrough, and many researchers now argue pre-training is not necessary. But even without pre-training, reliably training a deep MLP requires some additional sophistication, either in the initialization or training process beyond the older MLP training approaches of random initialization followed by standard gradient descent.
Nowadays Deep Learning has become a synonym for what have been known for many years as Neural Networks, including such applications as Word2Vec, which is actually just a 3-layer network, the minimum for doing anything beyond what can be computed with the original Perceptron architecture and not really “deep” at all. Other than Word2Vec, most of the networks that have gotten a lot of attention recently are in fact deep, in that they have far more layers than would have been practical until the last few years. For the most part these are at their core Convolutional Neural Networks (CNNs), an architecture based on the Neocognitron, described by Fukushima in 1980. One key feature of CNNs is that units share weights, which greatly reduces the amount of computation required for training.
In addition to the sheer amount of computation required in training a large network, as Patrick Hall mentions, networks with many layers using sigmoidal activation functions suffer from the vanishing/exploding gradient problem. In addition to the strategies he mentions, rectified linear units (ReLUs) do not exhibit the problem, though other strategies are required to compensate for the fact that the activation of ReLUs is not fully differentiable due to the singularity at zero, so the standard backpropagation algorithm, which is basically an application of the chain rule of calculus, does not apply in the obvious way (see here for discussion).
Current networks also tend to have heterogeneous architectures, combining aspects of feedforward, convolutional, and recurrent networks–so they’re actually complex in more ways than just the number of layers.
I’m going to try to keep this answer simple - hopefully I don’t leave out too much detail in doing so. To me, the answer is all about the initialization and training process - and this was perhaps the first major breakthrough in deep learning. Like others have said, MLP is not really different than deep learning, but arguably just one type of deep learning.
Back-propagation (which has existed for decades) theoretically allows you to train a network with many layers. But before the advent of deep learning, researchers did not have widespread success training neural networks with more than 2 layers.
This was mostly because of vanishing and/or exploding gradients. Prior to deep learning MLPs were typically initialized using random numbers. Like today, MLPs used the gradient of the network’s parameters w.r.t. to the network’s error to adjust the parameters to better values in each training iteration. In back propagation, to evaluate this gradient involves the chain rule and you must multiply each layer’s parameters and gradients together across all the layers. This is a lot of multiplication, especially for networks with more than 2 layers. If most of the weights across many layers are less than 1 and they are multiplied many times then eventually the gradient just vanishes into a machine-zero and training stops. If most of the parameters across many layers are greater than 1 and they are multiplied many times then eventually the gradient explodes into a huge number and the training process becomes intractable.
Deep learning proposed a new initialization strategy: use a series of single layer networks - which do not suffer from vanishing/exploding gradients - to find the initial parameters for a deep MLP. The pictures below attempt to illustrate this process:
1.) A single layer autoencoder network is used to find initial parameters for the first layer of a deep MLP.
2.) A single layer autoencoder network is used to find initial parameters for the second layer of a deep MLP.
3.) A single layer autoencoder network is used to find initial parameters for the third layer of a deep MLP.
4.) A softmax classifier (logistic regression) is used to find initial parameters for the output layer of a deep MLP.
Now that all the layers have been initialized through this pre-training process to values that are more suitable for the data, you can usually train the deep MLP using gradient descent techniques without the problem of vanishing/exploding gradients.
Of course the field of deep learning has moved forward since this initial breakthrough, and many researchers now argue pre-training is not necessary. But even without pre-training, reliably training a deep MLP requires some additional sophistication, either in the initialization or training process beyond the older MLP training approaches of random initialization followed by standard gradient descent.
Nowadays Deep Learning has become a synonym for what have been known for many years as Neural Networks, including such applications as Word2Vec, which is actually just a 3-layer network, the minimum for doing anything beyond what can be computed with the original Perceptron architecture and not really “deep” at all. Other than Word2Vec, most of the networks that have gotten a lot of attention recently are in fact deep, in that they have far more layers than would have been practical until the last few years. For the most part these are at their core Convolutional Neural Networks (CNNs), an architecture based on the Neocognitron, described by Fukushima in 1980. One key feature of CNNs is that units share weights, which greatly reduces the amount of computation required for training.
In addition to the sheer amount of computation required in training a large network, as Patrick Hall mentions, networks with many layers using sigmoidal activation functions suffer from the vanishing/exploding gradient problem. In addition to the strategies he mentions, rectified linear units (ReLUs) do not exhibit the problem, though other strategies are required to compensate for the fact that the activation of ReLUs is not fully differentiable due to the singularity at zero, so the standard backpropagation algorithm, which is basically an application of the chain rule of calculus, does not apply in the obvious way (see here for discussion).
Current networks also tend to have heterogeneous architectures, combining aspects of feedforward, convolutional, and recurrent networks–so they’re actually complex in more ways than just the number of layers.

相关文章推荐
- 稀疏自动编码器 (Sparse Autoencoder)
- 白化(Whitening):PCA vs. ZCA
- softmax回归
- 图像识别和图像搜索
- 卷积神经网络
- 深度学习札记
- 图像智能打标签‘神器’-AlchemyVision API
- ubuntu theano 安装成功,windows theano安装失败
- 【Deep learning vs BPL】思考:complex => simple => rich
- 卷积神经网络知识要点
- 1.linear Regression
- 1.linear Regression
- SURF项目总结 - deepdream
- Deep learning: autoencoders and sparsity
- Windows7+Anaconda+Theano+Pylearn2深度学习环境搭建
- 2015年12月5日
- 开设博客初衷
- 关于神经网络的学习
- deep learning 个人理解及其实现工具