黑马程序员-Java的集合类(java中类的容器)和算法
2015-12-13 15:08
585 查看
-----------android培训、java培训、java学习型技术博客、期待与您交流!------------
Java的集合类(java中类的容器)和算法
一、集合
1、集合只用于存储对象,集合的长度是可变的,集合可以存储不同类型的对象;
2、java的数据结构:每一个容器对数据的存储方式不同,所以具有多种多样的容器;
3、集合中的分类和常用接口、类
|--Collection集合接口:一组单独的元素存储
|--List列表接口:元素是有序的(存入和取出的顺序一致),元素都有索引(角标),元素允许重复。
|--ArrayList:底层数据结构是数组,查询速度快,增删操作较慢,线程不同步
|--LinkedList:底层数据结构是链表,查询效率较低,增删操作快,线程不同步
|--Vector:底层是数组数据结构。线程同步。被ArrayList替代了。因为效率低。
|--Set集接口:元素是无序的(存入和取出的顺序不一定一致),元素不允许重复,底层用到了Map
|--HashSet:底层数据结构是哈希表,存储的对象最好复写hashCode和equals方法,保证元素不会重复。线程不同步。
|--TreeSet:底层数据结构是二叉树,可以对Set集合中的元素按自然顺序进行排序,线程是不同步的。
存储的对象具备比较性。
|--Map映射接口:数据是以键值对的形式存储的,有的元素存在映射关系就可以使用该集合,元素不允许重复
|--HashTable:底层数据结构是哈希表,线程同步。不允许有null键或值。jdk1.0效率低;
|--HashMap:底层数据结构也是哈希表,线程不同步。允许有null键或值。将hashtable替代,jdk1.2效率高。
|--TreeMap:底层数据结构是二叉树(红-黑树)。线程不同步。可通过比较器用于给Map集合中键进行排序。
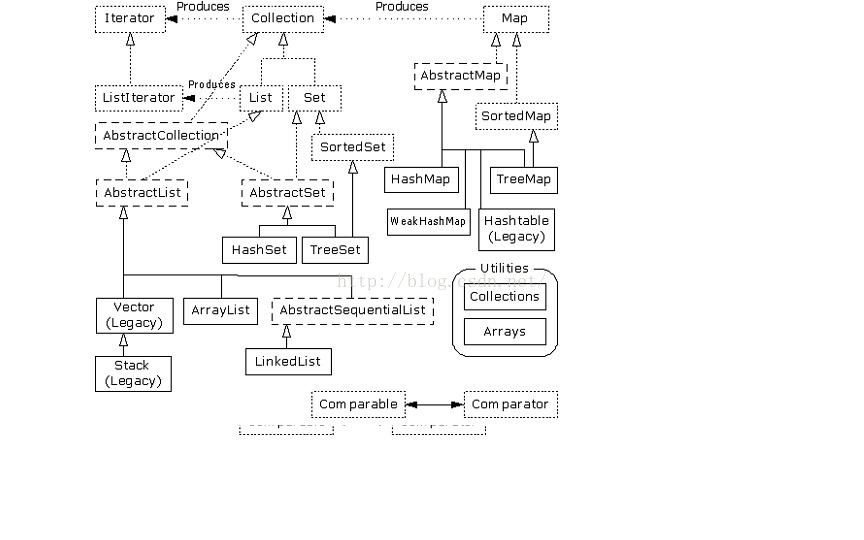
3、集合关系图
4、集合的特点
a、集合中存储的都是对象的引用(地址)。
b、add方法的参数类型是Object。以便于接收任意类型对象。
二、Collection集合接口
1、Collection定义了集合框架的共性功能。
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。
一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。
2、Collection的常见方法:
a、添加:
boolean add(Object obj);
boolean addAll(Collection coll);
b、删除:
boolean remove(Object obj);
boolean removeAll(Collection coll);
void clear();
c、判断:
boolean contains(Object obj);
boolean containsAll(Collection coll);
boolean isEmpty();判断集合中是否有元素。
d、获取:
int size();
iterator();
e、其他:
boolean removeAll(Collection<?> c);取差集
boolean retainAll(Collection coll);取交集
Object toArray();将集合转成数组
三、迭代器:
1、集合是继承了public interface Iterable<T>接口的Iterator<T> iterator()方法。
2、迭代器是集合的取出元素方式,会直接访问集合中的元素,所以将迭代器通过内部类的形式来进行描述。
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同,所以该迭代器对象是在容器中进行
内部实现的,也就是iterator方法在每个容器中的实现方式是不同的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator方法。
3、Iterator接口
Iterator iterator();
a、Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
通过容器的iterator()方法获取该内部类的对象。
b、操作方法
boolean hasNext();
E next();
void remove();
注:在迭代循环中next()一次,就必须hasNext()判断一次;连续两次调用next()可能发生错误。
4、ListIterator类
a、ListIterator是Iterator的子接口。
在迭代操作时,不可以又通过集合对象的方法操作集合中的元素,因为会发生ConcurrentModificationException异常。
所以,在迭代器时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,
如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。该接口只能通过List集合的listIterator方法获取。
b、系列表迭代器,允许程序员按任一方向遍历列表、迭代期间修改列表,并获得迭代器在列表中的当前位置。
只能用于List及其子类型。
c、操作方法
void add(E e);
boolean hasNext();
E next();//覆盖了Iterator接口的方法
void remove();
//逆向遍历,从集合的最后一个元素读取,判断前面有没有元素
boolean hasPrevious();//第一次使用的是时候为假,如果接着previous,就会发生NoSuchElementException违例,
//所以要先判断,再使用previous();
E previous();
四、List列表接口及其相关类
1、List的共性方法:特有的常见方法,有一个共性特点就是都可以操作角标。
a、添加(插入)
void add(int index,E element);
boolean addAll(int index,Collection<? extends E> c);
b、删除
E remove(int index);
boolean remove(Object o);
c、修改
E set(int index,E element);
d、获取:
E get(int index);
int indexOf(Object o);
int lastIndexOf(Object o);//获取指定元素的位置。
List<E> subList(int fromIndex,int toIndex);
ListIterator listIterator();
2、ArrayList类*
(1)动态数组的数据结构,默认长度为10,当超过时50%延长,而Vector是100%延长。
(2)ArrayList类与List接口中方法基本一致。
(3)ArrayList和LinkedList的大致区别:
a、ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
b、对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
c、对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
3、LinkedList类*
特有方法:
a、增加:
public void addFirst(E e);
public void addLast(E e);
在JDK1.6出现了替代方法:
public boolean offerFirst(E e);//与addFirst方法没有区别
public boolean offerLast(E e);//与addLast方法没有区别
b、获取
public E getFirst();
public E getLast();
注:获取元素,但不删除元素。如果集合中没有元素,会出现NoSuchElementException
在JDK1.6出现了替代方法:
public E peekFirst();
public E peekLast();
注:获取元素,但不删除元素。如果集合中没有元素,会返回null。
c、获取删除
public E removeFirst();
public E removeLast();
注:获取元素,但是元素被删除。如果集合中没有元素,会出现NoSuchElementException
在JDK1.6出现了替代方法:
public E pollFirst();
public E pollLast();
注:获取元素,但是元素被删除。如果集合中没有元素,会返回null。
注:这里不能定义成List的引用,因为这些方法在List接口中都没有,是LinkedList类的特有方法。
4、List集合中用contians()判断元素是否相同,依据是元素的equals方法。
remove方法底层也是依赖于元素的equals方法。
五、Set集接口及其相关类
1、Set的共性方法
Set接口中的方法和Collection基本一致。
2、HashSet类*
HashSet保证元素唯一性:通过元素的两个方法,hashCode()和equals()方法来完成。
如果元素的hashCode值相同,才会判断equals是否为true。
如果元素的hashcode值不同,不会调用equals。
注意:(1)对于自定义类的存放到HashSet中元素,需要覆盖hashCode和equals方法。
(2)对于判断元素是否存在,以及删除等操作,依赖的方法是先通过hashCode()比较元素的hashcode值是否相同,
如果相同,再继续判断元素的equals方法,是否为true。
3、TreeSet类
a、在TreeSet集合中存储的对象对应的类必须继承Comparable接口,告诉它排序的方法;否则没有办法存储,编译不能通过。
b、TreeSet判断元素唯一性的依据:
在集合初始化时,就有了比较方式。就是根据比较compareTo方法的返回结果是否是0,是0,就是相同元素,不存储。
c、TreeSet集合的底层是二叉树进行排序的
TreeSet排序的第一种方式:让元素自身具备比较性。元素需要实现Comparable接口,覆盖compareTo方法(当主要条件相同时,需要比较次要条件)。
也种方式也成为元素的自然顺序,或者叫做默认顺序。
TreeSet的第二种排序方式:当元素自身不具备比较性时,或者具备的比较性不是所需要的。这时就需要让集合自身具备比较性。
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
定义了比较器,将比较器对象作为参数传递给TreeSet集合的构造函数。
当两种排序都存在时,以比较器为主。定义一个类,实现Comparator接口,覆盖compare方法。
如果自定义类实现了Comparable接口,并且TreeSet的构造函数中也传入了比较器,那么将以比较器
的比较规则为准。
注:不管是在覆盖compareTo方法时,还是覆盖compare方法;当主要条件相同时,需要比较次要条件。
七、Map映射接口及其相关类
1、Map<K,V>集合:
(1) 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
该集合存储键值对。一对一对往里存。而且要保证键的唯一性。
例如:地图上,经纬度和图片地点之间就是典型的Map关系。
(2)Map的键是一个HashSet的集合。
注:Map和Set很像,其实Set底层就是使用了Map集合。
2、Map的共性方法
a、添加:如果添加元素时,出现相同的键。那么后添加的值会覆盖原有键对应值,并put方法会返回被覆盖的值。
V put(K key,V value);
void putAll(Map<? extends K,? extends V> m);
b、删除
void clear();
V remove(Object key);
c、判断
boolean containsKey(Object key);
boolean containsValue(Object value);
boolean isEmpty();
d、获取
int size();
V get(Object key);//可以通过get方法的返回值来判断一个键是否存在。通过返回null来判断。
Collection<V> values(); //获取map集合中所有的值。
Set<K> keySet();
Set<Map.Entry<K,V>> entrySet();
3、map集合的两种取出方式:
(1)Set<k> keySet():将map中所有的键存入到Set集合。因为set具备迭代器。
所有可以迭代方式取出所有的键,在根据get方法。获取每一个键对应的值。
Map集合的取出原理:将map集合转成set集合。在通过迭代器取出。
(2)Set<Map.Entry<k,v>> entrySet()方法:
a、将map集合中的映射关系存入到了set集合中,即Map.Entry对象。
b、而这个关系的数据类型就是:Map.Entry。Entry其实就是Map中的一个static内部接口。
定义在内部因为只有有了Map集合,有了键值对,才会有键值的映射关系。关系属于Map集合中的一个内部事物。
而且该事物在直接访问Map集合中的元素。
c、Map.Entry内部类有方法
K getKey();
V getValue();
其实Entry也是一个接口,它是Map接口中的一个内部接口(封闭接口)
interface Map{
public static interface Entry{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map{
class Hahs implements Map.Entry{
public Object getKey(){}
public Object getValue(){}
}
}
注:可以看做在HashMap和TreeMap类内部实现了Entry类,把Key和Value合并成一个特殊形式的字符串,加以保存。
4、HashMap类*
5、TreeMap类
(1)public TreeMap(Comparator<? super K> comparator);
(2)当数据之间存在这映射关系时,就要先想map集合。
6、Map扩展:把集合作为元素存储到Map中
八、比较
1、比较器:Comparator接口
(1)对象数组:对应自定义类的比较器需要继承Comparator接口,和覆盖 int compare(T o1,T o2)方法;
(2)对象集合:对应自定义类的比较器需要继承Comparator接口,和覆盖 int compare(T o1,T o2)方法;
并通过集合的构造函数把比较器传入。
2、自然比较方式:Comparable接口
自定义类需要需要继承Comparable接口,和覆盖 int compareTo(T o)方法;
九、包装器
1、Collections
(1)Collections:集合框架的工具类。里面定义的都是静态方法。
(2)Collections和Collection区别:
Collection是集合框架中的一个顶层接口,它里面定义了单列集合的共性方法。它有两个常用的子接口,
List:对元素都有定义索引。有序的。可以重复元素。
Set:不可以重复元素。无序。
Collections是集合框架中的一个工具类。该类中的方法都是静态的。
提供的方法中有可以对list集合进行排序,二分查找等方法。
通常常用的集合都是线程不安全的。因为要提高效率。
如果多线程操作这些集合时,可以通过该工具类中的同步方法,将线程不安全的集合,转换成安全的。
(3)常用算法
a、排序
public static <T> void sort(List<T> list,Comparator<? super T> c);
public static <T extends Comparable<? super T>> void sort(List<T> list);//针对List接口中的对象对应的类。
b、最大值
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll);
public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp);
c、查找
public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key);
public static <T> int binarySearch(List<? extends T> list, T key,Comparator<? super T> c);
d、替换
public static <T> void fill(List<? super T> list,T obj);
public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal);
public static void swap(List<?> list,int i,int j);
e、反转和反转规则
public static void reverse(List<?> list);
public static <T> Comparator<T> reverseOrder();
public static <T> Comparator<T> reverseOrder(Comparator<T> cmp);
f、多线程同步
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> List<T> synchronizedList(List<T> list);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
2、集合变数组:Collection接口中的toArray方法。
(1)指定类型的数组要定义长度:
当指定类型的数组长度小于了集合的size,那么该方法内部会创建一个新的数组。长度为集合的size。
当指定类型的数组长度大于了集合的size,就不会新创建了数组。而是使用传递进来的数组,就会有null值存入多出来的部分。
所以利用size()方法创建一个刚刚好的数组最优。
(2)将集合变数组目的:
为了限定对元素的操作。不需要进行增删了。
3、Arrays类
(1)Arrays:用于操作数组的工具类。里面都是静态方法。
public static <T> void sort(T[] a, Comparator<? super T> c);
public static void sort(Object[] a);//针对数组,任何元素组成的,包括自定义类组成的。
public static <T> int binarySearch(T[] a,T key,Comparator<? super T> c);
(2)将数组变成list集合:asList()
a、把数组变成list集合好处:可以使用集合的思想和方法来操作数组中的元素。
b、将数组变成集合,不可以使用集合的增删方法。因为数组的长度是固定。只能使用:
contains();
get();
indexOf();
subList();
如果你增删。那么会反生UnsupportedOperationException,
c、如果数组中的元素都是对象。那么变成集合时,数组中的元素就直接转成集合中的元素。
如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
Java的集合类(java中类的容器)和算法
一、集合
1、集合只用于存储对象,集合的长度是可变的,集合可以存储不同类型的对象;
2、java的数据结构:每一个容器对数据的存储方式不同,所以具有多种多样的容器;
3、集合中的分类和常用接口、类
|--Collection集合接口:一组单独的元素存储
|--List列表接口:元素是有序的(存入和取出的顺序一致),元素都有索引(角标),元素允许重复。
|--ArrayList:底层数据结构是数组,查询速度快,增删操作较慢,线程不同步
|--LinkedList:底层数据结构是链表,查询效率较低,增删操作快,线程不同步
|--Vector:底层是数组数据结构。线程同步。被ArrayList替代了。因为效率低。
|--Set集接口:元素是无序的(存入和取出的顺序不一定一致),元素不允许重复,底层用到了Map
|--HashSet:底层数据结构是哈希表,存储的对象最好复写hashCode和equals方法,保证元素不会重复。线程不同步。
|--TreeSet:底层数据结构是二叉树,可以对Set集合中的元素按自然顺序进行排序,线程是不同步的。
存储的对象具备比较性。
|--Map映射接口:数据是以键值对的形式存储的,有的元素存在映射关系就可以使用该集合,元素不允许重复
|--HashTable:底层数据结构是哈希表,线程同步。不允许有null键或值。jdk1.0效率低;
|--HashMap:底层数据结构也是哈希表,线程不同步。允许有null键或值。将hashtable替代,jdk1.2效率高。
|--TreeMap:底层数据结构是二叉树(红-黑树)。线程不同步。可通过比较器用于给Map集合中键进行排序。
3、集合关系图
4、集合的特点
a、集合中存储的都是对象的引用(地址)。
b、add方法的参数类型是Object。以便于接收任意类型对象。
二、Collection集合接口
1、Collection定义了集合框架的共性功能。
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。
一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。
2、Collection的常见方法:
a、添加:
boolean add(Object obj);
boolean addAll(Collection coll);
b、删除:
boolean remove(Object obj);
boolean removeAll(Collection coll);
void clear();
c、判断:
boolean contains(Object obj);
boolean containsAll(Collection coll);
boolean isEmpty();判断集合中是否有元素。
d、获取:
int size();
iterator();
e、其他:
boolean removeAll(Collection<?> c);取差集
boolean retainAll(Collection coll);取交集
Object toArray();将集合转成数组
三、迭代器:
1、集合是继承了public interface Iterable<T>接口的Iterator<T> iterator()方法。
2、迭代器是集合的取出元素方式,会直接访问集合中的元素,所以将迭代器通过内部类的形式来进行描述。
该对象必须依赖于具体容器,因为每一个容器的数据结构都不同,所以该迭代器对象是在容器中进行
内部实现的,也就是iterator方法在每个容器中的实现方式是不同的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器的对象即可,也就是iterator方法。
3、Iterator接口
Iterator iterator();
a、Iterator接口就是对所有的Collection容器进行元素取出的公共接口。
通过容器的iterator()方法获取该内部类的对象。
b、操作方法
boolean hasNext();
E next();
void remove();
注:在迭代循环中next()一次,就必须hasNext()判断一次;连续两次调用next()可能发生错误。
import java.util.*;
class CollectionDemo {
public static void collectionBaseOperater(){
Collection a = new ArrayList();
//增加
a.add("java 01");
a.add("java 02");
a.add("java 03");
a.add("java 04");
//删除
a.remove("java 03");
//a.clear();
//长度
sop("a.size():"+a.size());
//是否为空
sop("a.contains:"+a.contains("java 03"));
sop("a.isEmpty:"+a.isEmpty());
//打印
sop(a);
sop("\r\n------------------------------\r\n");
//集合操作
Collection a1 = new ArrayList();
a1.add("java 01");
a1.add("java 02");
a1.add("java 03");
a1.add("java 04");
Collection a2 = new ArrayList();
a2.add("java 01");
a2.add("java 02");
a2.add("java 05");
a2.add("java 06");
//a1.retainAll(a2);//取交集
a1.removeAll(a2);//取差集
sop(a1);
sop(a2);
}
public static void printf(Collection c){
/*
Iterator it = al.iterator();//获取迭代器,用于取出集合中的元素。
while(it.hasNext())
{
sop(it.next());
}
*/
//采用for循环,使it成为局部变量,用完就可以清除出内存,同时对象垃圾也可以回收。
for(Iterator it = c.iterator();it.hasNext();){
System.out.print(it.next()+" ");
}
System.out.println();
}
public static void main(String[] args) {
//collectionBaseOperater();
String[] strArr = {"This","is ","a","java","test."};
Collection a = new ArrayList();
for(int i=0;i<strArr.length;i++){
a.add(strArr[i]);
}
printf(a);
}
public static void sop(Object obj){
System.out.println(obj);
}
}4、ListIterator类
a、ListIterator是Iterator的子接口。
在迭代操作时,不可以又通过集合对象的方法操作集合中的元素,因为会发生ConcurrentModificationException异常。
所以,在迭代器时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,
如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。该接口只能通过List集合的listIterator方法获取。
b、系列表迭代器,允许程序员按任一方向遍历列表、迭代期间修改列表,并获得迭代器在列表中的当前位置。
只能用于List及其子类型。
c、操作方法
void add(E e);
boolean hasNext();
E next();//覆盖了Iterator接口的方法
void remove();
//逆向遍历,从集合的最后一个元素读取,判断前面有没有元素
boolean hasPrevious();//第一次使用的是时候为假,如果接着previous,就会发生NoSuchElementException违例,
//所以要先判断,再使用previous();
E previous();
四、List列表接口及其相关类
1、List的共性方法:特有的常见方法,有一个共性特点就是都可以操作角标。
a、添加(插入)
void add(int index,E element);
boolean addAll(int index,Collection<? extends E> c);
b、删除
E remove(int index);
boolean remove(Object o);
c、修改
E set(int index,E element);
d、获取:
E get(int index);
int indexOf(Object o);
int lastIndexOf(Object o);//获取指定元素的位置。
List<E> subList(int fromIndex,int toIndex);
ListIterator listIterator();
2、ArrayList类*
(1)动态数组的数据结构,默认长度为10,当超过时50%延长,而Vector是100%延长。
(2)ArrayList类与List接口中方法基本一致。
(3)ArrayList和LinkedList的大致区别:
a、ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
b、对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
c、对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
import java.util.*;
class ListDemo {
public static void sop(Object obj){
System.out.println(obj);
}
public static void printf(Collection c){
for(Iterator it = c.iterator();it.hasNext();){
System.out.print(it.next()+" ");
}
System.out.println();
}
public static void listBaseOperator(List ls){
ls.add(2,"abc6");
sop(ls);
//ls.remove(2);
//sop(ls);
ls.set(2,"abc8");
sop(ls);
for(int i=0;i<ls.size();i++){
System.out.println("ls["+i+"]="+ls.get(i));
}
printf(ls);
ls.add(3,"abc6");
ls.add(2,"abc2");
printf(ls);
int index1 = ls.indexOf("abc2");
int index2 = ls.lastIndexOf("abc2");
System.out.println("index1="+index1+","+"index2="+index2);
List subLs = ls.subList(1,3);
printf(subLs);
}
public static void listIteratorOperator(List ls){
/*
Iterator it = al.iterator();
while(it.hasNext())
{
Object obj = it.next();
if(obj.equals("java02"))
//al.add("java008");//在迭代过程中,准备添加或者删除元素,发生错误;迭代操作时,不能同时进行集合方法的操作。
it.remove();//将java02的引用从集合中删除了。
sop("obj="+obj);
}
sop(al);
*/
ListIterator li = ls.listIterator();
sop("hasPrevious():"+li.hasPrevious());//hasPrevious():false
//sop("pre::"+li.previous());//Exception in thread "main" java.util.NoSuchElementException
while(li.hasNext())
{
Object obj = li.next();
if(obj.equals("abc2"))
//li.add("java009");
li.set("abc6");
}
while(li.hasPrevious())
{
sop("pre::"+li.previous());
}
/*
结果:
pre::abc6
pre::abc1
pre::abc0
*/
sop("hasNext():"+li.hasNext());//hasNext():false,取到了最后,指针后面没有元素了。
sop("hasPrevious():"+li.hasPrevious());//hasPrevious():true
sop(ls);
}
public static void main(String[] args) {
String[] strArr = {"abc0","abc1","abc2"};
List ls = new ArrayList();
for(int i=0;i<strArr.length;i++){
ls.add(strArr[i]);
}
sop(ls);
//listBaseOperator(ls);
listIteratorOperator(ls);
}
}import java.util.*;
class ArrayListTest1 {
public static void sop(Object obj){
System.out.println(obj);
}
public static List removeRepeatElement(List li){
List newArr = new ArrayList();
//for(int i =0;i<li.size();i++){
//Object obj = li.get(i);
//if(!newArr.contains(obj)){
//newArr.add(obj);
//}
//}
for(Iterator it = li.iterator();it.hasNext();){
Object obj = it.next();
if(!newArr.contains(obj)){//调用存储对象的equals()方法判断。
newArr.add(obj);
}
}
return newArr;
}
public static void main(String[] args) {
List li = new ArrayList();
li.add("abc0");
li.add("abc1");
li.add("abc2");
li.add("abc3");
li.add("abc1");
sop(li);
sop(removeRepeatElement(li));
}
}3、LinkedList类*
特有方法:
a、增加:
public void addFirst(E e);
public void addLast(E e);
在JDK1.6出现了替代方法:
public boolean offerFirst(E e);//与addFirst方法没有区别
public boolean offerLast(E e);//与addLast方法没有区别
b、获取
public E getFirst();
public E getLast();
注:获取元素,但不删除元素。如果集合中没有元素,会出现NoSuchElementException
在JDK1.6出现了替代方法:
public E peekFirst();
public E peekLast();
注:获取元素,但不删除元素。如果集合中没有元素,会返回null。
c、获取删除
public E removeFirst();
public E removeLast();
注:获取元素,但是元素被删除。如果集合中没有元素,会出现NoSuchElementException
在JDK1.6出现了替代方法:
public E pollFirst();
public E pollLast();
注:获取元素,但是元素被删除。如果集合中没有元素,会返回null。
注:这里不能定义成List的引用,因为这些方法在List接口中都没有,是LinkedList类的特有方法。
import java.util.*;
class LinkedListDemo {
public static void sop(Object obj){
System.out.println(obj);
}
public static void printf(Collection c){
for(Iterator it = c.iterator();it.hasNext();){
System.out.print(it.next()+" ");
}
System.out.println();
}
public static void main(String[] args) {
LinkedList link = new LinkedList();//这里不能定义成List的引用,因为这些方法在List接口中都没有,是LinkedList类的特有方法
link.offerFirst("abc0");
link.offerFirst("abc1");
link.offerFirst("abc2");
link.offerFirst("abc3");
sop(link);
//sop(link.peekFirst());
//sop(link);
//sop(link.peekFirst());
//sop(link);
//sop(link.pollFirst());
//sop(link);
//sop(link.pollFirst());
//sop(link);
//sop(link.peekLast());
//sop(link);
//sop(link.pollLast());
//sop(link);
printf(link);
while(!link.isEmpty()){
sop(link.pollLast());
}
printf(link);
}
}/*
需求:使用LinkedList模拟一个堆栈或者队列数据结构。
分析:
堆栈:先进后出
队列:先进先出
*/
import java.util.*;
class MyStack{
private LinkedList link;
MyStack(){
link = new LinkedList();
}
public void setData(Object o){
link.offerFirst(o);
}
public Object getData(){
return link.pollFirst();
}
public boolean isNotData(){
return link.isEmpty();
}
}
class MyQueue{
private LinkedList link;
MyQueue(){
link = new LinkedList();
}
public void setData(Object o){
link.offerFirst(o);
}
public Object getData(){
return link.pollLast();
}
public boolean isNotData(){
return link.isEmpty();
}
}
class LinkedListTest{
public static void sop(Object obj){
System.out.println(obj);
}
public static void main(String[] args) {
MyQueue mq = new MyQueue();
mq.setData("abc01");
mq.setData("abc02");
mq.setData("abc03");
sop(mq.getData());
MyStack ms = new MyStack();
ms.setData("def01");
ms.setData("def02");
ms.setData("def03");
sop(ms.getData());
}
}4、List集合中用contians()判断元素是否相同,依据是元素的equals方法。
remove方法底层也是依赖于元素的equals方法。
/*
将自定义对象作为元素存到ArrayList集合中,并去除重复元素。
比如:存人对象。同姓名同年龄,视为同一个人。为重复元素。
思路:
1,对人描述,将数据封装进人对象。
2,定义容器,将人存入。
3,取出。
结论:List集合判断元素是否相同,依据是元素的equals方法;
remove方法底层也是依赖于元素的equals方法。
*/
import java.util.*;
class Person{
private String name;
private int age;
Person(String name,int age){
this.name = name;
this.age = age;
}
public boolean equals(Object obj){
if(!(obj instanceof Person))
return false;
Person p = (Person)obj;
//System.out.println(this.name+"....."+p.name);
return ((this.name.equals(p.name))&&(this.age == p.age));
}
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
}
class ArrayListTest2 {
public static void sop(Object obj)
{
System.out.println(obj);
}
public static ArrayList singleElement(ArrayList al)
{
ArrayList newArr = new ArrayList();
Iterator it = al.iterator();
while(it.hasNext())
{
Object obj = it.next();
if(!newArr.contains(obj))
newArr.add(obj);
}
return newArr;
}
public static void main(String[] args)
{
ArrayList al = new ArrayList();
al.add(new Person("lisi01",30));//al.add(Object obj);//Object obj = new Person("lisi01",30);
//al.add(new Person("lisi02",32));
al.add(new Person("lisi02",32));
al.add(new Person("lisi04",35));
al.add(new Person("lisi03",33));
//al.add(new Person("lisi04",35));
//al = singleElement(al);
sop("remove 03 :"+al.remove(new Person("lisi03",33)));。
Iterator it = al.iterator();
while(it.hasNext())
{
Person p = (Person)it.next();
sop(p.getName()+"::"+p.getAge());
}
}
}五、Set集接口及其相关类
1、Set的共性方法
Set接口中的方法和Collection基本一致。
2、HashSet类*
HashSet保证元素唯一性:通过元素的两个方法,hashCode()和equals()方法来完成。
如果元素的hashCode值相同,才会判断equals是否为true。
如果元素的hashcode值不同,不会调用equals。
注意:(1)对于自定义类的存放到HashSet中元素,需要覆盖hashCode和equals方法。
(2)对于判断元素是否存在,以及删除等操作,依赖的方法是先通过hashCode()比较元素的hashcode值是否相同,
如果相同,再继续判断元素的equals方法,是否为true。
import java.util.*;
class Person
{
private String name;
private int age;
Person(String name,int age)
{
this.name = name;
this.age = age;
}
public int hashCode()
{
System.out.println(this.name+"....hashCode");
return name.hashCode()+age*37;//37是处理name和age不同,但是相加值相同的情况
}
public boolean equals(Object obj)
{
if(!(obj instanceof Person))
return false;
Person p = (Person)obj;
System.out.println(this.name+"...equals.."+p.name);
return this.name.equals(p.name) && this.age == p.age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
}
class HashSetTest {
public static void sop(Object obj){
System.out.println(obj);
}
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(new Person("a1",11));
hs.add(new Person("a2",12));
hs.add(new Person("a3",13));
//hs.add(new Person("a2",12));
//sop("a1:"+hs.contains(new Person("a2",12)));
hs.remove(new Person("a2",12));
for(Iterator it = hs.iterator();it.hasNext();)
{
Person p = (Person)it.next();
sop(p.getName()+"::"+p.getAge());
}
}
}3、TreeSet类
a、在TreeSet集合中存储的对象对应的类必须继承Comparable接口,告诉它排序的方法;否则没有办法存储,编译不能通过。
b、TreeSet判断元素唯一性的依据:
在集合初始化时,就有了比较方式。就是根据比较compareTo方法的返回结果是否是0,是0,就是相同元素,不存储。
c、TreeSet集合的底层是二叉树进行排序的
TreeSet排序的第一种方式:让元素自身具备比较性。元素需要实现Comparable接口,覆盖compareTo方法(当主要条件相同时,需要比较次要条件)。
也种方式也成为元素的自然顺序,或者叫做默认顺序。
import java.util.*;
class Student implements Comparable{//该接口强制让学生具备比较性
private String name;
private int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public int compareTo(Object obj){
//return 0; 在集合初始化时,就有了比较方式。就是根据比较compareTo方法的返回结果是否是0,是0,就是相同元素,不存储。
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
//System.out.println(this.name+"....compareto....."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)
{
return this.name.compareTo(s.name);//排序时,当主要条件相同时,一定判断一下次要条件。
}
return -1;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
}
class TreeSetDemo {
public static void main(String[] args){
TreeSet ts = new TreeSet();
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi09",19));
ts.add(new Student("lisi08",19));
//ts.add(new Student("lisi007",20));
for(Iterator it = ts.iterator();it.hasNext();){
Student stu = (Student)it.next();
System.out.println(stu.getName()+"..."+stu.getAge());
}
}
}TreeSet的第二种排序方式:当元素自身不具备比较性时,或者具备的比较性不是所需要的。这时就需要让集合自身具备比较性。
让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
定义了比较器,将比较器对象作为参数传递给TreeSet集合的构造函数。
当两种排序都存在时,以比较器为主。定义一个类,实现Comparator接口,覆盖compare方法。
如果自定义类实现了Comparable接口,并且TreeSet的构造函数中也传入了比较器,那么将以比较器
的比较规则为准。
import java.util.*;
class Student implements Comparable{
private String name;
private int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public int compareTo(Object obj){
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
//System.out.println(this.name+"....compareto....."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)
{
return this.name.compareTo(s.name);
return -1;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
}
class TreeSetDemo2 {
public static void main(String[] args){
TreeSet ts = new TreeSet(new MyComparator());
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi09",19));
ts.add(new Student("lisi08",19));
ts.add(new Student("lisi007",23));
for(Iterator it = ts.iterator();it.hasNext();){
Student stu = (Student)it.next();
System.out.println(stu.getName()+"..."+stu.getAge());
}
}
}
class MyComparator implements Comparator{
public int compare(Object o1,Object o2){
Student s1 = (Student)o1;
Student s2 = (Student)o2;
int num = s1.getName().compareTo(s2.getName());
if(num ==0){//排序时,当主要条件相同时,一定判断一下次要条件。
}
return (new Integer(s1.getAge()).compareTo(new Integer(s2.getAge())));
//if(s1.getAge()>s2.getAge()){
//return 1;
//}
//if(s1.getAge()==s2.getAge()){
//return 0;
//}
//return -1;
}
return num;
}
}注:不管是在覆盖compareTo方法时,还是覆盖compare方法;当主要条件相同时,需要比较次要条件。
/*
需求:按照字符串长度排序。
*/
import java.util.*;
class TreeSetTest {
public static void main(String[] args){
TreeSet ts = new TreeSet(new MyComparator());
ts.add("abcde");
ts.add("cd");
ts.add("bc");
ts.add("dte");
ts.add("iop");
for(Iterator it = ts.iterator();it.hasNext();){
System.out.println(it.next());
}
}
}
class MyComparator implements Comparator{
public int compare(Object o1,Object o2){
String s1 = (String)o1;
String s2 = (String)o2;
int num = new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num ==0){//排序时,当主要条件相同时,一定判断一下次要条件。
return s1.compareTo(s2);
}
return num;
}
}七、Map映射接口及其相关类
1、Map<K,V>集合:
(1) 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
该集合存储键值对。一对一对往里存。而且要保证键的唯一性。
例如:地图上,经纬度和图片地点之间就是典型的Map关系。
(2)Map的键是一个HashSet的集合。
注:Map和Set很像,其实Set底层就是使用了Map集合。
2、Map的共性方法
a、添加:如果添加元素时,出现相同的键。那么后添加的值会覆盖原有键对应值,并put方法会返回被覆盖的值。
V put(K key,V value);
void putAll(Map<? extends K,? extends V> m);
b、删除
void clear();
V remove(Object key);
c、判断
boolean containsKey(Object key);
boolean containsValue(Object value);
boolean isEmpty();
d、获取
int size();
V get(Object key);//可以通过get方法的返回值来判断一个键是否存在。通过返回null来判断。
Collection<V> values(); //获取map集合中所有的值。
Set<K> keySet();
Set<Map.Entry<K,V>> entrySet();
import java.util.*;
class MapDemo{
public static void main(String[] args) {
Map<String,String> map = new HashMap<String,String>();
System.out.println(map.put("100","abc00"));
map.put("101","abc0");
map.put("102","abc1");
map.put("103","abc2");
map.put("104","abc3");
map.put("105","abc4");
System.out.println(map.put("105","abc5"));
System.out.println("map.containKey:"+map.containsKey("102"));
//System.out.println("map.remove:"+map.remove("102"));
map.put(null,"abc6");
System.out.println("get(null):"+map.get(null));
map.put("106",null);
System.out.println("get:"+map.get("106"));
Collection<String> cl = map.values();
System.out.println(cl);
System.out.println(map);
}
}3、map集合的两种取出方式:
(1)Set<k> keySet():将map中所有的键存入到Set集合。因为set具备迭代器。
所有可以迭代方式取出所有的键,在根据get方法。获取每一个键对应的值。
Map集合的取出原理:将map集合转成set集合。在通过迭代器取出。
(2)Set<Map.Entry<k,v>> entrySet()方法:
a、将map集合中的映射关系存入到了set集合中,即Map.Entry对象。
b、而这个关系的数据类型就是:Map.Entry。Entry其实就是Map中的一个static内部接口。
定义在内部因为只有有了Map集合,有了键值对,才会有键值的映射关系。关系属于Map集合中的一个内部事物。
而且该事物在直接访问Map集合中的元素。
c、Map.Entry内部类有方法
K getKey();
V getValue();
其实Entry也是一个接口,它是Map接口中的一个内部接口(封闭接口)
interface Map{
public static interface Entry{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map{
class Hahs implements Map.Entry{
public Object getKey(){}
public Object getValue(){}
}
}
注:可以看做在HashMap和TreeMap类内部实现了Entry类,把Key和Value合并成一个特殊形式的字符串,加以保存。
import java.util.*;
class MapDemo2{
public static void readMethodByKey(Map map){
Set<String> set = map.keySet();
for(Iterator<String> it = set.iterator();it.hasNext();){
String key = it.next();
String values = (String)map.get(key);
System.out.println("key= "+key+"->"+"values= "+values);
}
}
public static void readMethodByEntry(Map map){
Set<Map.Entry<String,String>> entry = map.entrySet();
//for(Iterator it = entry.iterator();it.hasNext();){
//Map.Entry<String,String> mapEntry = (Map.Entry<String,String>)it.next();
for(Iterator<Map.Entry<String,String>> it = entry.iterator();it.hasNext();){
Map.Entry<String,String> mapEntry = it.next();
String key = mapEntry.getKey();
String values = mapEntry.getValue();
System.out.println("key= "+key+"->"+"values= "+values);
}
}
public static void main(String[] args) {
Map<String,String> map = new HashMap<String,String>();
map.put("101","abc0");
map.put("102","abc1");
map.put("103","abc2");
map.put("104","abc3");
map.put("105","abc4");
readMethodByKey(map);
//readMethodByEntry(map);
System.out.println(map);
}
}4、HashMap类*
/*
需求:每一个学生都有对应的归属地。
学生Student,地址String。
学生属性:姓名,年龄。
注意:姓名和年龄相同的视为同一个学生,保证学生的唯一性。
分析:
1、描述学生。
2、定义map容器。将学生作为键,地址作为值。存入。
3、获取map集合中的元素。
*/
import java.util.*;
class Student implements Comparable<Student>{//使类具有自然的比较顺序,为了存入TreeSet;以及广泛使用。
private String name;
private int age;
Student(String name,int age){
this.name = name;
this.age = age;
}
public int compareTo(Student stu){//指定了类型
int num = new Integer(this.age).compareTo(new Integer(stu.age));
if(num ==0)
return this.name.compareTo(stu.name);
return num;
}
public int hashCode(){
return name.hashCode()+age*37;//37是处理name和age不同,但是相加值相同的情况
}
public boolean equals(Object obj){
if(!(obj instanceof Student))
//return false;
throw new ClassCastException("Type mismatch!");
Student p = (Student)obj;
return this.name.equals(p.name) && this.age == p.age;
}
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public int getAge(){
return age;
}
public String toString(){
return (this.name+":"+this.age);
}
}
class MapTest{
public static void readMethodByKey(Map map){
Set<Student> set = map.keySet();
for(Iterator<Student> it = set.iterator();it.hasNext();){
Student key = it.next();
String values = (String)map.get(key);
System.out.println("key= "+key+"->"+"values= "+values);
}
}
public static void readMethodByEntry(Map map){
Set<Map.Entry<Student,String>> entry = map.entrySet();
for(Iterator<Map.Entry<Student,String>> it = entry.iterator();it.hasNext();){
Map.Entry<Student,String> mapEntry = it.next();
Student key = mapEntry.getKey();
String values = mapEntry.getValue();
System.out.println("key= "+key+"->"+"values= "+values);
}
}
public static void main(String[] args) {
Map<Student,String> map = new HashMap<Student,String>();
map.put(new Student("java01",20),"abc0");
map.put(new Student("java02",22),"abc1");
map.put(new Student("java03",25),"abc2");
map.put(new Student("java04",30),"abc3");
map.put(new Student("java05",21),"abc4");
readMethodByKey(map);
//readMethodByEntry(map);
System.out.println(map);
}
}5、TreeMap类
(1)public TreeMap(Comparator<? super K> comparator);
import java.util.*;
class nameComparator implements Comparator<Student>{
public int compare(Student s1,Student s2){
int value = s1.getName().compareTo(s2.getName());
if(value ==0){
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
}
return value;
}
}
class MapTest2 {
public static void main(String[] args)
{
Map<Student,String> map = new TreeMap(new nameComparator());
map.put(new Student("java01",20),"abc0");
map.put(new Student("java02",22),"abc1");
map.put(new Student("java03",25),"abc2");
map.put(new Student("java04",30),"abc3");
map.put(new Student("java04",30),"abc5");
map.put(new Student("java05",21),"abc4");
Set<Map.Entry<Student,String>> entryset = map.entrySet();
for(Iterator<Map.Entry<Student,String>> it = entryset.iterator();it.hasNext();){
Map.Entry<Student,String> me = it.next();
Student stu = me.getKey();
String addr = me.getValue();
System.out.println(stu+"::"+addr);
}
}
}(2)当数据之间存在这映射关系时,就要先想map集合。
/*
练习:
"sdfgzxcvasdfxcvdf"获取该字符串中的字母出现的次数。
希望打印结果:a(1)c(2).....
思路1:
1、字母->次数 :Map映射关系;
字母为键值,次数为值
2、处理字符串,存入到Map中,计算次数;
a、把字符串处理成char[];
b、for-for循环处理;
c、记录每个字母次数;
d、把字母和次数存入Map集合。
3、打印Map映射。
思路2:
1、将字符串转换成字符数组。因为要对每一个字母进行操作。
2、定义一个map集合,因为打印结果的字母有顺序,所以使用treemap集合。
3、遍历字符数组。
将每一个字母作为键去查map集合。
如果返回null,将该字母和1存入到map集合中。
如果返回不是null,说明该字母在map集合已经存在并有对应次数。
那么就获取该次数并进行自增。,然后将该字母和自增后的次数存入到map集合中。覆盖调用原理键所对应的值。
4、将map集合中的数据变成指定的字符串形式返回。
*/
import java.util.*;
class MapTest3 {
public static String charCount(String str){
Map<Character,Integer> map = new TreeMap<Character,Integer>();
/*
char[] arr = str.toCharArray();
for(int i =0;i<arr.length;i++){
int count =0;
char s = arr[i];
for(int j=0;j<arr.length;j++){
if(arr[i]==arr[j])
count++;
}
map.put(new Character(arr[i]),new Integer(count));
}
*/
//char[] arr = str.toCharArray();
//for(int i =0;i<arr.length;i++){
//Integer value = map.get(arr[i]);
//if(value == null){
//map.put(arr[i],1);
//}
//else{
//map.put(arr[i],(value+1));
//}
//}
char[] arr = str.toCharArray();
int count =0;
for(int i =0;i<arr.length;i++){
if((arr[i]>='a'&&arr[i]<='z')||(arr[i]>='A'&&arr[i]<='Z')){
count =0;
Integer value = map.get(arr[i]);
if(value != null)
count = value;
count++;
map.put(arr[i],count);
}
}
StringBuilder sb = new StringBuilder();
Set<Map.Entry<Character,Integer>> entryset = map.entrySet();
for(Iterator<Map.Entry<Character,Integer>> it = entryset.iterator();it.hasNext();){
Map.Entry<Character,Integer> me = it.next();
Character charc = me.getKey();
Integer num = me.getValue();
sb.append(charc+"("+num+")");
}
return sb.toString();
}
public static void main(String[] args){
String str = "sdf-gzxcvasdfx-cvdf";
String s = charCount(str);
System.out.println(s);
}
}6、Map扩展:把集合作为元素存储到Map中
/*
需求:用Map描述一个公司的结构。
销售部:工号 姓名
开发部:工号 姓名
*/
import java.util.*;
class Employee{
private String workNumber;
private String name;
Employee(String workNumber,String name){
this.workNumber = workNumber;
this.name = name;
}
public String toString(){
return (workNumber+"::"+name);
}
}
class MapDemo3{
public static void methodOne(){
HashMap<String,List<Employee>> company = new HashMap<String,List<Employee>>();
List<Employee> develop = new ArrayList<Employee>();
List<Employee> sale = new ArrayList<Employee>();
company.put("sale",sale);
company.put("develop",develop);
sale.add(new Employee("101","abc0"));
sale.add(new Employee("102","abc1"));
develop.add(new Employee("103","abc2"));
develop.add(new Employee("104","abc3"));
Iterator<String> it = company.keySet().iterator();
while(it.hasNext()){
String department = it.next();
List<Employee> departmentName = company.get(department);
System.out.println(department);
Iterator<Employee> its = departmentName.iterator();
while(its.hasNext()){
Employee employee = its.next();
System.out.println(employee);
}
}
}
public static void methodTwo(){
HashMap<String,HashMap<String,String>> company = new HashMap<String,HashMap<String,String>> ();
HashMap<String,String> develop = new HashMap<String,String>();
HashMap<String,String> sale = new HashMap<String,String>();
company.put("sale",sale);
company.put("develop",develop);
sale.put("101","abc0");
sale.put("102","abc1");
develop.put("103","abc2");
develop.put("104","abc3");
Iterator<String> it = company.keySet().iterator();
while(it.hasNext()){
String department = it.next();
HashMap<String,String> departmentName = company.get(department);
System.out.println(department);
Iterator<String> its = departmentName.keySet().iterator();
while(its.hasNext()){
String workNumber = its.next();
String name = departmentName.get(workNumber);
System.out.println(workNumber+"::"+name);
}
}
}
public static void main(String[] args)
{
methodOne();
//methodTwo();
}
}八、比较
1、比较器:Comparator接口
(1)对象数组:对应自定义类的比较器需要继承Comparator接口,和覆盖 int compare(T o1,T o2)方法;
(2)对象集合:对应自定义类的比较器需要继承Comparator接口,和覆盖 int compare(T o1,T o2)方法;
并通过集合的构造函数把比较器传入。
2、自然比较方式:Comparable接口
自定义类需要需要继承Comparable接口,和覆盖 int compareTo(T o)方法;
/*
需求:按照字符串长度排序。
*/
import java.util.*;
class TreeSetTest {
public static void main(String[] args){
TreeSet ts = new TreeSet(new MyComparator());
ts.add("abcde");
ts.add("cd");
ts.add("bc");
ts.add("dte");
ts.add("iop");
for(Iterator it = ts.iterator();it.hasNext();){
System.out.println(it.next());
}
}
}
class MyComparator implements Comparator{
public int compare(Object o1,Object o2){
String s1 = (String)o1;
String s2 = (String)o2;
int num = new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num ==0){//排序时,当主要条件相同时,一定判断一下次要条件。
return s1.compareTo(s2);
}
return num;
}
}九、包装器
1、Collections
(1)Collections:集合框架的工具类。里面定义的都是静态方法。
(2)Collections和Collection区别:
Collection是集合框架中的一个顶层接口,它里面定义了单列集合的共性方法。它有两个常用的子接口,
List:对元素都有定义索引。有序的。可以重复元素。
Set:不可以重复元素。无序。
Collections是集合框架中的一个工具类。该类中的方法都是静态的。
提供的方法中有可以对list集合进行排序,二分查找等方法。
通常常用的集合都是线程不安全的。因为要提高效率。
如果多线程操作这些集合时,可以通过该工具类中的同步方法,将线程不安全的集合,转换成安全的。
(3)常用算法
a、排序
public static <T> void sort(List<T> list,Comparator<? super T> c);
public static <T extends Comparable<? super T>> void sort(List<T> list);//针对List接口中的对象对应的类。
b、最大值
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll);
public static <T> T max(Collection<? extends T> coll,Comparator<? super T> comp);
c、查找
public static <T> int binarySearch(List<? extends Comparable<? super T>> list,T key);
public static <T> int binarySearch(List<? extends T> list, T key,Comparator<? super T> c);
import java.util.*;
class StrLenComparator implements Comparator<String>{
public int compare(String s1,String s2){
int num = new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num ==0)
return s1.compareTo(s2);
return num;
}
}
class CollectionsDemo{
public static void main(String[] args) {
//sortDemo();
//maxDemo();
binarySearchDemo();
}
public static void binarySearchDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
//Collections.sort(list);
Collections.sort(list,new StrLenComparator());
sop(list);
//int index = Collections.binarySearch(list,"aaaa");
//int index = halfSearch(list,"cc");
int index = halfSearch2(list,"aaa",new StrLenComparator());
sop("index="+index);
}
//binarySearch()方法内部的实现
public static int halfSearch(List<String> list,String key){
int max,min,mid;
max = list.size()-1;
min = 0;
while(min<=max)
{
mid = (max+min)>>1;// /2;
String str = list.get(mid);
int num = str.compareTo(key);
if(num>0)
max = mid -1;
else if(num<0)
min = mid + 1;
else
return mid;
}
return -min-1;//
}
public static int halfSearch2(List<String> list,String key,Comparator<String> cmp){
int max,min,mid;
max = list.size()-1;
min = 0;
while(min<=max)
{
mid = (max+min)>>1;// /2;
String str = list.get(mid);
int num = cmp.compare(str,key);//自定义的比较器的比较方法
if(num>0)
max = mid -1;
else if(num<0)
min = mid + 1;
else
return mid;
}
return -min-1;
}
//binarySearch()方法内部的实现
public static void maxDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
list.add("bbbbb");
Collections.sort(list);
sop(list);
//String max = Collections.max(list);
String max = Collections.max(list,new StrLenComparator());
sop("max="+max);
}
public static void sortDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
sop(list);
Collections.sort(list);
//Collections.sort(list,new StrLenComparator());
sop(list);
}
public static void sop(Object obj){
System.out.println(obj);
}
}d、替换
public static <T> void fill(List<? super T> list,T obj);
public static <T> boolean replaceAll(List<T> list,T oldVal,T newVal);
public static void swap(List<?> list,int i,int j);
e、反转和反转规则
public static void reverse(List<?> list);
public static <T> Comparator<T> reverseOrder();
public static <T> Comparator<T> reverseOrder(Comparator<T> cmp);
import java.util.*;
//反向
class StrComparator implements Comparator<String>
{
public int compare(String s1,String s2)
{
/*
int num = s1.compareTo(s2);
if(num>0)
return -1;
if( num<0)
return 1;
return num;
*/
return s2.compareTo(s1);
}
}
class StrLenComparator implements Comparator<String>{
public int compare(String s1,String s2){
int num = new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num ==0)
return s1.compareTo(s2);
return num;
}
}
class CollectionsDemo2{
public static void main(String[] args) {
//replaceDemo();
//reverseDemo();
//reverseorderDemo();
shuffleDemo();
}
public static void shuffleDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
sop(list);
Collections.shuffle(list);
sop(list);
}
public static void reverseorderDemo(){
//TreeSet<String> ts = new TreeSet<String>(Collections.reverseOrder());
TreeSet<String> ts = new TreeSet<String>(Collections.reverseOrder(new StrLenComparator()));
ts.add("abcde");
ts.add("aaa");
ts.add("k");
ts.add("cc");
for(String s:ts)
{
System.out.println(s);
}
}
public static void reverseDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
sop(list);
Collections.reverse(list);
sop(list);
}
public static void replaceDemo(){
List<String> list = new ArrayList<String>();
list.add("abcd");
list.add("aaa");
list.add("zz");
list.add("kkkkk");
list.add("qq");
list.add("z");
sop(list);
//Collections.fill(list,"pp");
//sop(list);
//fillPrcessList(list,2,4);
//sop(list);
Collections.swap(list,1,4);
sop(list);
}
public static void fillPrcessList(List<String> list,int start,int end){
List<String> temp = list.subList(start,end+1);
Collections.fill(temp,"pp");
for(int i=start,j=0;i<=end;i++,j++){
Collections.replaceAll(list,list.get(i),temp.get(j));
}
}
public static void sop(Object obj){
System.out.println(obj);
}
}f、多线程同步
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> List<T> synchronizedList(List<T> list);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
2、集合变数组:Collection接口中的toArray方法。
(1)指定类型的数组要定义长度:
当指定类型的数组长度小于了集合的size,那么该方法内部会创建一个新的数组。长度为集合的size。
当指定类型的数组长度大于了集合的size,就不会新创建了数组。而是使用传递进来的数组,就会有null值存入多出来的部分。
所以利用size()方法创建一个刚刚好的数组最优。
(2)将集合变数组目的:
为了限定对元素的操作。不需要进行增删了。
import java.util.*;
class CollectionsToArray{
public static void main(String[] args) {
ArrayList<String> al = new ArrayList<String>();
al.add("abc1");
al.add("abc2");
al.add("abc3");
//String[] arr = al.toArray(new String[0]);//[abc1, abc2, abc3]
//String[] arr = al.toArray(new String[5]);//[abc1, abc2, abc3, null, null]
String[] arr = al.toArray(new String[al.size()]);
System.out.println(Arrays.toString(arr));
}
}3、Arrays类
(1)Arrays:用于操作数组的工具类。里面都是静态方法。
public static <T> void sort(T[] a, Comparator<? super T> c);
public static void sort(Object[] a);//针对数组,任何元素组成的,包括自定义类组成的。
public static <T> int binarySearch(T[] a,T key,Comparator<? super T> c);
(2)将数组变成list集合:asList()
a、把数组变成list集合好处:可以使用集合的思想和方法来操作数组中的元素。
b、将数组变成集合,不可以使用集合的增删方法。因为数组的长度是固定。只能使用:
contains();
get();
indexOf();
subList();
如果你增删。那么会反生UnsupportedOperationException,
c、如果数组中的元素都是对象。那么变成集合时,数组中的元素就直接转成集合中的元素。
如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在。
import java.util.*;
class ArraysDemo{
public static void main(String[] args) {
//int[] arr = {2,4,5};
//System.out.println(Arrays.toString(arr));
//String[] arr = {"abc","cc","kkkk"};
//List<String> list = Arrays.asList(arr);
//sop("contains:"+list.contains("cc"));
////list.add("qq");//UnsupportedOperationException,
//sop(list);
int[] nums = {2,4,5};
List li = Arrays.asList(nums);//[[I@1db9742] 等价于 List<int[]> li = Arrays.asList(nums);
sop(li);
Integer[] num = {2,4,5};
List<Integer> lis = Arrays.asList(num);
sop(lis);
}
public static boolean myContains(String[] arr,String key){
for(int x=0;x<arr.length; x++){
if(arr[x].equals(key))
return true;
}
return false;
}
public static void sop(Object obj){
System.out.println(obj);
}
}
相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树
- [原创]java局域网聊天系统