Django 数据导入
2015-12-05 21:58
561 查看
原文地址:http://www.ziqiangxuetang.com/django/django-import-data.html
以下操作符合 Django版本为 1.6 ,兼顾 Django 1.7, Django 1.8 版本,理论上Django 1.4, 1.5 也没有问题,没有提到的都是默认值
建议先不要看源码,按教程一步步做下去,遇到问题再试试源代码,直接复制粘贴,很快就会忘掉,自己动手打一遍
我们新建一个项目 mysite, 再新建一个 app,名称为blog
把 blog 中的 models.py 更改为以下内容
不要忘了把 blog 加入到 settings.py 中的 INSTALLED_APPS 中。
python manage.py syncdb
Django 1.6以下版本会看到:
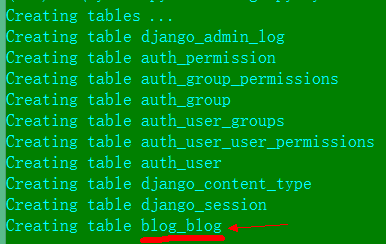
Django 创建了一些默认的表,注意后面那个红色标记的blog_blog是appname_classname的样式,这个表是我们自己写的Blog类创建的
Django 1.7.6及以上的版本会看到:(第六行即为创建了对应的blog_blog表)
进入该项目的django环境的终端(windows如何进入对应目录?看 Django环境搭建 的 3.2 部分)
先说如何用命令新增一篇文章:
这样就新增了一篇博文,我们查看一下
还有两种方法(这两种差不多):
后面两种方法也很重要,尤其是用在修改数据的时候,要记得最后要保存一下 blog.save(),第一种Blog.objects.create()是自动保存的。
三、批量导入
比如我们要导入一个文本,里面是标题和内容,中间用四个*隔开的,示例(oldblog.txt):
在终端导入有时候有些不方便,我们在mysite目录下写一个脚本,叫 txt2db.py,把oldblog.txt也放在mysite下
好了,我们在终端运行它
运行完毕后会打出一个 "Done!", 数据已经全部导入!
四、导入数据重复 解决办法
如果你导入数据过多,导入时出错了,或者你手动停止了,导入了一部分,还有一部分没有导入。或者你再次运行上面的命令,你会发现数据重复了,怎么办呢?
django.db.models 中还有一个函数叫 get_or_create() 有就获取过来,没有就创建,用它可以避免重复,但是速度可以会慢些,因为要先尝试获取,看看有没有
只要把上面的
Blog.objects.create(title=title,content=content)
换成下面的就不会重复导入数据了
Blog.objects.get_or_create(title=title,content=content)
返回值是(BlogObject, True/False) 新建时返回 True, 已经存在时返回 False。
更多数据库API的知识请参见官网文档:QuerySet API
最常见的fixture文件就是用python manage.py dumpdata 导出的文件,示例如下:
你也可以根据自己的models,创建这样的json文件,然后用 python manage.py loaddata fixture.json 导入
详见:https://docs.djangoproject.com/en/dev/howto/initial-data/
可以写一个脚本,把要导入的数据转化成 json 文件,这样导入也会更快些!
由于Blog.objects.create()每保存一条就执行一次SQL,而bulk_create()是执行一条SQL存入多条数据,做会快很多!当然用列表解析代替 for 循环会更快!!
以下操作符合 Django版本为 1.6 ,兼顾 Django 1.7, Django 1.8 版本,理论上Django 1.4, 1.5 也没有问题,没有提到的都是默认值
建议先不要看源码,按教程一步步做下去,遇到问题再试试源代码,直接复制粘贴,很快就会忘掉,自己动手打一遍
我们新建一个项目 mysite, 再新建一个 app,名称为blog
把 blog 中的 models.py 更改为以下内容
不要忘了把 blog 加入到 settings.py 中的 INSTALLED_APPS 中。
一、同步数据库,创建相应的表
python manage.py syncdbDjango 1.6以下版本会看到:
Django 创建了一些默认的表,注意后面那个红色标记的blog_blog是appname_classname的样式,这个表是我们自己写的Blog类创建的
Django 1.7.6及以上的版本会看到:(第六行即为创建了对应的blog_blog表)
二、输入 python manage.py shell
进入该项目的django环境的终端(windows如何进入对应目录?看 Django环境搭建 的 3.2 部分)先说如何用命令新增一篇文章:
这样就新增了一篇博文,我们查看一下
还有两种方法(这两种差不多):
后面两种方法也很重要,尤其是用在修改数据的时候,要记得最后要保存一下 blog.save(),第一种Blog.objects.create()是自动保存的。
三、批量导入
比如我们要导入一个文本,里面是标题和内容,中间用四个*隔开的,示例(oldblog.txt):
在终端导入有时候有些不方便,我们在mysite目录下写一个脚本,叫 txt2db.py,把oldblog.txt也放在mysite下
好了,我们在终端运行它
运行完毕后会打出一个 "Done!", 数据已经全部导入!
四、导入数据重复 解决办法
如果你导入数据过多,导入时出错了,或者你手动停止了,导入了一部分,还有一部分没有导入。或者你再次运行上面的命令,你会发现数据重复了,怎么办呢?
django.db.models 中还有一个函数叫 get_or_create() 有就获取过来,没有就创建,用它可以避免重复,但是速度可以会慢些,因为要先尝试获取,看看有没有
只要把上面的
Blog.objects.create(title=title,content=content)
换成下面的就不会重复导入数据了
Blog.objects.get_or_create(title=title,content=content)
返回值是(BlogObject, True/False) 新建时返回 True, 已经存在时返回 False。
更多数据库API的知识请参见官网文档:QuerySet API
五、用fixture导入(更快)
最常见的fixture文件就是用python manage.py dumpdata 导出的文件,示例如下:你也可以根据自己的models,创建这样的json文件,然后用 python manage.py loaddata fixture.json 导入
详见:https://docs.djangoproject.com/en/dev/howto/initial-data/
可以写一个脚本,把要导入的数据转化成 json 文件,这样导入也会更快些!
六、Model.objects.bulk_create() 更快更方便
由于Blog.objects.create()每保存一条就执行一次SQL,而bulk_create()是执行一条SQL存入多条数据,做会快很多!当然用列表解析代替 for 循环会更快!!

相关文章推荐
- POJ 2007 Scrambled Polygon (凸包输出点路径)
- django第一个项目
- Scrambled Polygon(斜率排序)
- Django 配置settings.py
- iGraph的配置,An In-depth Comparison of Subgraph Isomorphism Algorithms in Graph Databases
- Django创建超级管理员
- Day 29:编写你的第一个 Google Chrome 扩展程序
- solr整合mongo实现搜索
- poj--2007--Scrambled Polygon(数学几何基础)
- poj--2007--Scrambled Polygon(数学几何基础)
- Django学习笔记 — 自定义User模型
- Django models获取对象有以下方法:
- Google_FaceDetetor CameraHal 实现
- golang标准库学习——buffio包
- [读书笔记] The.Way.To.Go
- hdu 3966 Aragorn's Story 树链剖分
- [Medical Image Processing] 2. GrayScale Histogram and Threshold-【Isodata Algorithm】
- Go语言分析
- Google 推出最新图像识别工具
- Pycharm 安装 , Git 插件安装,django环境配置