keepalived高级应用
2015-12-03 18:01
423 查看
上篇博客学习了vrrp协议和keepalived的基本应用,现在就来学习keepalived的高级应用
一、keepalived+lvs实现httpd高可用负载均衡集群
1、环境
192.168.100.179 lvs(dr模型)+keepalived
192.168.100.180 lvs(dr模型)+keepalived
192.168.100.173 httpd1
192.168.100.175 httpd2
OS:CentOS-6.5-x86_64
vip:192.168.100.11
拓扑简单就不画了
集群各节点时间同步
2、后端主机的配置
为了方便使用,我们写一个脚本,配置后端主机的内核参数和vip
179节点:
测试:从浏览器访问192.168.100.11
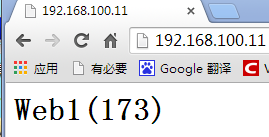

刷新能够实现轮询173和175。
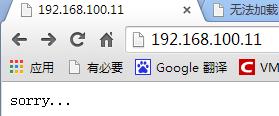
再测试当173和175都挂了时:
4、自定义邮件通知
如何在keepalived故障时或主备切换时(默认只有在后端主机故障才会发邮件通知),发送自定义的警告邮件给指定的管理员?
在keepalived配置文件vrrp_instance(虚拟路由)段中添加指定脚本的路径
notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup " notify_fault "/etc/keepalived/notify.sh fault -"
直接使用上面的环境把lvs改成haproxy就可以了
我们知道keepalived在后端主机故障时只能对ip做漂移,并不能像其它高可用方案一样高可用某服务,这里就要使用脚本达到后端主机故障启用某服务。
1、haproxy的配置
简单修改下haproxy的配置:
当179和180两个节点,哪个节点是主节点时,应该启动haproxy服务,备用时关闭haproxy(一直运行着也可以咯)还要有检测haproxy服务是否正常运行的脚本,故障时就切换。
haproxy的切换脚本:
做双主模式就是在加一个虚拟路由就可以了,就不再演示了,不清楚的可以看上篇博文。
一、keepalived+lvs实现httpd高可用负载均衡集群
1、环境
192.168.100.179 lvs(dr模型)+keepalived
192.168.100.180 lvs(dr模型)+keepalived
192.168.100.173 httpd1
192.168.100.175 httpd2
OS:CentOS-6.5-x86_64
vip:192.168.100.11
拓扑简单就不画了
集群各节点时间同步
2、后端主机的配置
为了方便使用,我们写一个脚本,配置后端主机的内核参数和vip
[root@BAIYU_173 ~]# cat lvs_dr.sh
#/bin/bash
#
vip="192.168.100.11"
start() {
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
ifconfig lo:0 $vip netmask 255.255.255.255 broadcast $vip
route add -host $vip dev lo:0
}
stop() {
echo 0> /proc/sys/net/ipv4/conf/all/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
echo 0 > /proc/sys/net/ipv4/conf/lo/arp_announce
ifconfig lo:0 down
}
case $1 in
start)
start
;;
stop)
stop
;;
*)
echo "Usage:$(basename $0) {start|stop}"
exit 1
esac
[root@BAIYU_173 ~]# bash lvs_dr.sh start
[root@BAIYU_173 ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:6A:DC:8D
inet addr:192.168.100.173 Bcast:192.168.100.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:67549 errors:0 dropped:0 overruns:0 frame:0
TX packets:23518 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:4583906 (4.3 MiB) TX bytes:2019642 (1.9 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:618 errors:0 dropped:0 overruns:0 frame:0
TX packets:618 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:54373 (53.0 KiB) TX bytes:54373 (53.0 KiB)
lo:0 Link encap:Local Loopback
inet addr:192.168.100.11 Mask:255.255.255.255
UP LOOPBACK RUNNING MTU:65536 Metric:1
[root@BAIYU_173 ~]# scp lvs_dr.sh 192.168.100.175:~ #复制到httpd2上并执行3、keepalived配置179节点:
[root@BAIYU_179 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@loalhost
}
notification_email_from xiexiaojun
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_mt_down {
script "[ -f /etc/keepalived/down ] && exit 1 || exit 0"
interval 1
weight -5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass vi111
}
virtual_ipaddress {
192.168.100.11
}
track_script {
chk_mt_down
}
}
virtual_server 192.168.100.11 80 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
# persistence_timeout 50
protocol TCP
real_server 192.168.100.173 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.100.175 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
sorry_server 127.0.0.1 80 备用服务器,在集群中如果所有real server全部宕机了,客户端访问时就会出现错误页面,这样是很不友好的,我们提供一个维护页面来提醒用户什么时间段正在维护。
}180节点:[root@BAIYU_180 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from xiexiaojun
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_mt_down {
script "[ -f /etc/keepalived/down ] && exit 1 || exit 0"
interval 1
weight -5
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass vi111
}
virtual_ipaddress {
192.168.100.11
}
track_script {
chk_mt_down
}
}
virtual_server 192.168.100.11 80 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
# persistence_timeout 50
protocol TCP
real_server 192.168.100.173 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.100.175 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
sorry_server 127.0.0.1 80 #备用服务器,在集群中如果所有real server全部宕机了,客户端访问时就会出现错误页面,这样是很不友好的,我们提供一个维护页面来提醒用户什么时间段正在维护。
}查看179节点:[root@BAIYU_179 keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:53:f6:29 brd ff:ff:ff:ff:ff:ff inet 192.168.100.179/24 brd 192.168.100.255 scope global eth0 inet 192.168.100.11/32 scope global eth0 inet6 fe80::20c:29ff:fe53:f629/64 scope link valid_lft forever preferred_lft forever [root@BAIYU_179 keepalived]# ipvsadm IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn ^C [root@BAIYU_179 keepalived]# ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.100.11:80 rr -> 192.168.100.173:80 Route 1 0 1 -> 192.168.100.175:80 Route 1 0 0可以看到keepalived根据配置文件自动生成了lvs规则,
测试:从浏览器访问192.168.100.11
刷新能够实现轮询173和175。
再测试当173和175都挂了时:
[root@BAIYU_179 html]# ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 192.168.100.11:80 rr -> 127.0.0.1:80 Local 1 0 8从浏览器访问192.168.100.11:
4、自定义邮件通知
如何在keepalived故障时或主备切换时(默认只有在后端主机故障才会发邮件通知),发送自定义的警告邮件给指定的管理员?
在keepalived配置文件vrrp_instance(虚拟路由)段中添加指定脚本的路径
notify_master "/etc/keepalived/notify.sh master" notify_backup "/etc/keepalived/notify.sh backup " notify_fault "/etc/keepalived/notify.sh fault -"
[root@BAIYU_179 keepalived]# cat notify.sh
#!/bin/bash
# Author: MageEdu <linuxedu@foxmail.com>
# description: An example of notify script
#
vip=172.16.100.11
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac
[root@BAIYU_179 keepalived]# chmod +x notify.sh
[root@BAIYU_179 keepalived]# scp notify.sh 192.168.100.180:/etc/keepalived/
notify.sh 100% 618 0.6KB/s 00:00二、keepalived+haproxy实现httpd高可用负载均衡集群直接使用上面的环境把lvs改成haproxy就可以了
我们知道keepalived在后端主机故障时只能对ip做漂移,并不能像其它高可用方案一样高可用某服务,这里就要使用脚本达到后端主机故障启用某服务。
1、haproxy的配置
简单修改下haproxy的配置:
frontend main *:80 64 # acl url_static path_beg -i /static /images /javascript /stylesheets 65 # acl url_static path_end -i .jpg .gif .png .css .js 66 67 # use_backend static if url_static 68 default_backend app 69 70 #--------------------------------------------------------------------- 71 # static backend for serving up images, stylesheets and such 72 #--------------------------------------------------------------------- 73 #backend static 74 balance roundrobin 75 server static 127.0.0.1:80 check 76 77 #--------------------------------------------------------------------- 78 # round robin balancing between the various backends 79 #--------------------------------------------------------------------- 80 backend app 81 balance roundrobin 82 server app1 192.168.100.173:80 check 83 server app2 192.168.100.175:80 check 84 # server app3 127.0.0.1:5003 check 85 # server app4 127.0.0.1:5004 check [root@BAIYU_179 haproxy]# scp haproxy.cfg 192.168.100.180:/etc/haproxy/ haproxy.cfg 100% 3351 3.3KB/s 00:00为了避免之前配置的lvs影响,在后端主机上运行之前lvs.sh脚本关闭之前的配置
[root@BAIYU_175 ~]# bash lvs_dr.sh stop [root@BAIYU_173 ~]# bash lvs_dr.sh stop2、[b]keepalived的配置[/b]
当179和180两个节点,哪个节点是主节点时,应该启动haproxy服务,备用时关闭haproxy(一直运行着也可以咯)还要有检测haproxy服务是否正常运行的脚本,故障时就切换。
haproxy的切换脚本:
[root@BAIYU_180 keepalived]# cat notify.sh
#!/bin/bash
# Author: MageEdu <linuxedu@foxmail.com>
# description: An example of notify script
#
vip=172.16.100.11
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
/etc/rc.d/init.d/haproxy start
exit 0
;;
backup)
notify backup
/etc/rc.d/init.d/haproxy restart #注意:如果这里为stop,那么主haproxy down时,权重-5,
而备haproxy因为haproxy stop 权重也-5,此时ip不会转移。
exit 0
;;
fault)
notify fault
/etc/rc.d/init.d/haproxy stop
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac179节点:[root@BAIYU_179 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from xiexiaojun
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_mt_down {
script "[ -f /etc/keepalived/down ] && exit 1 || exit 0"
interval 1
weight -5
}
vrrp_script chk_haproxy {
script "killall -0 haproxy &>/dev/null"
interval 1
weight -5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass vi111
}
virtual_ipaddress {
192.168.100.11
}
track_script {
chk_mt_down
chk_haproxy
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.100.11 80 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
# persistence_timeout 50
protocol TCP
real_server 192.168.100.173 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.100.175 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
sorry_server 127.0.0.1 80
}180节点:[root@BAIYU_180 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from xiexiaojun
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_mt_down {
script "[ -f /etc/keepalived/down ] && exit 1 || exit 0"
interval 1
weight -5
}
vrrp_script chk_haproxy {
script "killall -0 haproxy &>/dev/null"
interval 1
weight -5
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass vi111
}
virtual_ipaddress {
192.168.100.11
}
track_script {
chk_mt_down #检测2两个脚本,有一个执行失败就检测失败
chk_haproxy
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.100.11 80 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
# persistence_timeout 50
protocol TCP
real_server 192.168.100.173 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.100.175 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
sorry_server 127.0.0.1 80
}测试:做双主模式就是在加一个虚拟路由就可以了,就不再演示了,不清楚的可以看上篇博文。

相关文章推荐
- cryptico.js使用技巧
- QT 控件基础
- How can I install mySQL on CentOS without being root/su?
- 杭电1257 最少拦截系统
- Android 检测 手机硬件状态 的Utils
- 转----详解IOS开发应用之并发Dispatch Queues
- js基础篇——encodeURI 和encodeURIComponent
- Handling unhandled exceptions and signals
- 使用dos指令快速导出手机文件
- ios开发之block的使用,及注意事项
- 1024 杭电 max plus
- 点击tableView时触发事件,比如隐藏键盘
- Unity局部高效实时阴影的思考和实现
- 头疼:为什么chrome不能访问本地文件(带--disable-web-security --allow-file-access-from-files )
- Linux学习之创建子进程
- 动态级联 省、市、区
- 创建自己的CA机构 - openssl cert 双向认证
- chrome开发者工具功能拾遗:Elements面板篇
- light oj1116 - Ekka Dokka 【简单数学】
- java跳出多重嵌套循环