字符串和编码
2015-11-26 17:39
260 查看
ascii:
起始只有ascii编码。用一个字节保存。而一个字节只有8位。范围在-128~127之间。
解释下为什么是-128~127之间:因为首位0表示正数,1表示负数。
故正数最大为01111111=127
按理负数最大11111111=-127。但实际上没有-0这种说法也就是10000000不代表-0,所以10000000=-128。故一个字节是-128~127。
言归正传,故ascii只存了127个字母。包括大小写字母和一些符号。
很显然处理中文是远远不够的,至少需要两个字节。故中国制定了GB2312编码,用来把中文编进去。日本也有Shift_JIS韩国也有Euc-kr。这样太混乱。于是诞生了Unicode。
Unicode:
Unicode把所有语言都统一到一套编码里。用两个字节来表示。如果用到非常偏僻的字符用4个字节。这样的话乱码问题就消失了。但是出现了一个新问题。如果英文字符非常多的话。用Unicode就会比ascii多一倍的空间。Unicode两个字节,而ascii一个字节。为了解决这个问题就诞生了UTF-8。
UTF-8:
UTF-8根据不同数字大小编码成1-6个字节。英文字母是一个字节,常用汉字3个字节。如果你的文本包含大量英文字符,用UTF-8就能节省空间。而且UTF-8是支持ascii编码的。
顺便提一下:GBK是GB2312的扩展。使用了双字节的编码方案。并且与Unicode兼容。
我们再来看一下计算机系统中的字符编码问题:
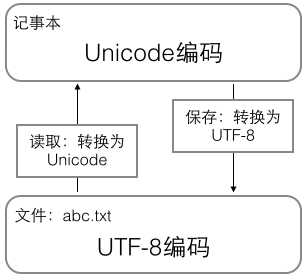
读取文件时,先把UTF-8转换成Unicode放在内存里。保存时再把Unicode转成UTF-8保存到文件里。
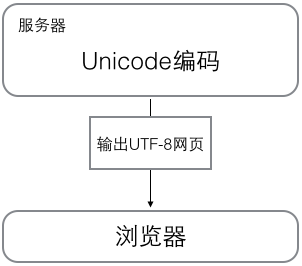
浏览网页时,服务器会把动态生成的Unicode转换成UTF-8再传输到浏览器。
参考:廖雪峰的Python教程。
起始只有ascii编码。用一个字节保存。而一个字节只有8位。范围在-128~127之间。
解释下为什么是-128~127之间:因为首位0表示正数,1表示负数。
故正数最大为01111111=127
按理负数最大11111111=-127。但实际上没有-0这种说法也就是10000000不代表-0,所以10000000=-128。故一个字节是-128~127。
言归正传,故ascii只存了127个字母。包括大小写字母和一些符号。
很显然处理中文是远远不够的,至少需要两个字节。故中国制定了GB2312编码,用来把中文编进去。日本也有Shift_JIS韩国也有Euc-kr。这样太混乱。于是诞生了Unicode。
Unicode:
Unicode把所有语言都统一到一套编码里。用两个字节来表示。如果用到非常偏僻的字符用4个字节。这样的话乱码问题就消失了。但是出现了一个新问题。如果英文字符非常多的话。用Unicode就会比ascii多一倍的空间。Unicode两个字节,而ascii一个字节。为了解决这个问题就诞生了UTF-8。
UTF-8:
UTF-8根据不同数字大小编码成1-6个字节。英文字母是一个字节,常用汉字3个字节。如果你的文本包含大量英文字符,用UTF-8就能节省空间。而且UTF-8是支持ascii编码的。
顺便提一下:GBK是GB2312的扩展。使用了双字节的编码方案。并且与Unicode兼容。
我们再来看一下计算机系统中的字符编码问题:
读取文件时,先把UTF-8转换成Unicode放在内存里。保存时再把Unicode转成UTF-8保存到文件里。
浏览网页时,服务器会把动态生成的Unicode转换成UTF-8再传输到浏览器。
参考:廖雪峰的Python教程。

相关文章推荐
- Linux 与 Windows 对UNICODE 的处理方式
- Unicode详细分析解释
- ASP编码必备的8条原则
- Perl ASCII 字符判断
- vbs中将GB2312转Unicode的代码
- XML指南——XML编码
- C#中字符串编码处理
- ExtJS中文乱码之GBK格式编码解决方案及代码
- 将编码从GB2312转成UTF-8的方法汇总(从前台、程序、数据库)
- 程序员趣味读物 谈谈Unicode编码
- 文本文件编码方式区别
- 与ASCII码相关的C语言字符串操作函数
- C语言安全编码之数值中的sizeof操作符
- C#实现获取文本文件的编码的一个类(区分GB2312和UTF8)
- 常用字符集编码详解(ASCII GB2312 GBK GB18030 unicode UTF-8)
- VC中BASE64编码和解码使用详解
- C#实现Json转Unicode的方法
- 计算机中的字符串编码、乱码、BOM等问题详解
- 深入理解Python字符编码 推荐
- ASCII