《神经网络和深度学习》系列文章十五:反向传播算法
2015-11-26 13:41
363 查看
出处: Michael Nielsen的《Neural Network and Deep Learning》,点击末尾“阅读原文”即可查看英文原文。
本节译者:哈工大SCIR本科生 王宇轩
声明:如需转载请联系wechat_editors@ir.hit.edu.cn,未经授权不得转载。
使用神经网络识别手写数字
反向传播算法是如何工作的
热身:一个基于矩阵的快速计算神经网络输出的方法
关于损失函数的两个假设
Hadamard积
反向传播背后的四个基本等式
四个基本等式的证明(选读)
反向传播算法
反向传播算法代码
为什么说反向传播算法很高效
反向传播:整体描述
改进神经网络的学习方法
神经网络能够计算任意函数的视觉证明
为什么深度神经网络的训练是困难的
深度学习
反向传播等式为我们提供了一个计算代价函数梯度的方法。下面让我们明确地写出该算法:
输入
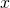
:计算输入层相应的激活函数值
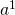
。
正向传播:对每个
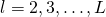
,计算
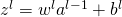
和
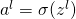
。
输出误差
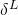
:计算向量
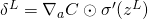
。
将误差反向传播:对每个
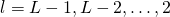
计算
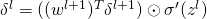
输出:代价函数的梯度为
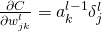
和
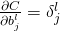
通过以上算法就能看出它为什么叫反向传播算法。我们从最后一层开始,反向计算错误向量
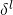
。在神经网络中反向计算误差可能看起来比较奇怪。但如果回忆反向传播的证明过程,会发现反向传播的过程起因于代价函数是关于神经网络输出值的函数。为了了解代价函数是如何随着前面的权重和偏移改变的,我们必须不断重复应用链式法则,通过反向的计算得到有用的表达式。
假设我们修改了正向传播网络中的一个神经元,使得该神经元的输出为
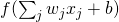
,其中
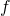
是一个非sigmoid函数的函数。在这种情况下我们应该怎样修改反向传播算法?
线性神经元的反向传播
假设我们在整个神经网络中用
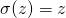
代替常用的非线性方程
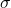
。重新写出这种情况下的反向传播算法。
正如我在上文中已经说过的,反向传播算法对每个训练样本
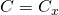
计算代价函数的梯度。在实际情况中,经常将反向传播算法与诸如随机梯度下降的学习算法共同使用,在随机梯度下降算法中,我们需要计算一批训练样本的梯度。给定一小批(mini-batch)
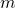
个训练样本,下面的算法给出了基于这些训练样本的梯度下降学习步骤:
输入一组训练样本
对每个训练样本
:设定相应的输入激活值
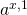
并执行以下步骤:
正向传播:对于每个
,计算
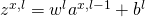
和
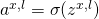
。
输出误差
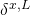
:计算向量
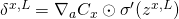
。
将误差反向传播:对每个
,计算
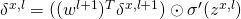
。
梯度下降:对每个
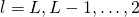
,分别根据法则
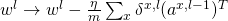
和
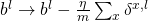
更新权重和偏移。
当然,为了在实际应用时实现随机梯度下降,你还需要一个用于生成小批(mini-batches)训练样本的外部循环和一个用于逐步计算每一轮迭代的外部循环。为了简洁,这些都被省略了。
下一节我们将介绍“反向传播算法代码”,敬请关注!
“哈工大SCIR”公众号
编辑部:郭江,李家琦,徐俊,李忠阳,俞霖霖
本期编辑:李忠阳
本节译者:哈工大SCIR本科生 王宇轩
声明:如需转载请联系wechat_editors@ir.hit.edu.cn,未经授权不得转载。
使用神经网络识别手写数字
反向传播算法是如何工作的
热身:一个基于矩阵的快速计算神经网络输出的方法
关于损失函数的两个假设
Hadamard积
反向传播背后的四个基本等式
四个基本等式的证明(选读)
反向传播算法
反向传播算法代码
为什么说反向传播算法很高效
反向传播:整体描述
改进神经网络的学习方法
神经网络能够计算任意函数的视觉证明
为什么深度神经网络的训练是困难的
深度学习
反向传播等式为我们提供了一个计算代价函数梯度的方法。下面让我们明确地写出该算法:
输入
:计算输入层相应的激活函数值
。
正向传播:对每个
,计算
和
。
输出误差
:计算向量
。
将误差反向传播:对每个
计算
输出:代价函数的梯度为
和
通过以上算法就能看出它为什么叫反向传播算法。我们从最后一层开始,反向计算错误向量
。在神经网络中反向计算误差可能看起来比较奇怪。但如果回忆反向传播的证明过程,会发现反向传播的过程起因于代价函数是关于神经网络输出值的函数。为了了解代价函数是如何随着前面的权重和偏移改变的,我们必须不断重复应用链式法则,通过反向的计算得到有用的表达式。
练习
修改一个神经元后的反向传播假设我们修改了正向传播网络中的一个神经元,使得该神经元的输出为
,其中
是一个非sigmoid函数的函数。在这种情况下我们应该怎样修改反向传播算法?
线性神经元的反向传播
假设我们在整个神经网络中用
代替常用的非线性方程
。重新写出这种情况下的反向传播算法。
正如我在上文中已经说过的,反向传播算法对每个训练样本
计算代价函数的梯度。在实际情况中,经常将反向传播算法与诸如随机梯度下降的学习算法共同使用,在随机梯度下降算法中,我们需要计算一批训练样本的梯度。给定一小批(mini-batch)
个训练样本,下面的算法给出了基于这些训练样本的梯度下降学习步骤:
输入一组训练样本
对每个训练样本
:设定相应的输入激活值
并执行以下步骤:
正向传播:对于每个
,计算
和
。
输出误差
:计算向量
。
将误差反向传播:对每个
,计算
。
梯度下降:对每个
,分别根据法则
和
更新权重和偏移。
当然,为了在实际应用时实现随机梯度下降,你还需要一个用于生成小批(mini-batches)训练样本的外部循环和一个用于逐步计算每一轮迭代的外部循环。为了简洁,这些都被省略了。
下一节我们将介绍“反向传播算法代码”,敬请关注!
“哈工大SCIR”公众号
编辑部:郭江,李家琦,徐俊,李忠阳,俞霖霖
本期编辑:李忠阳

相关文章推荐
- iOS开发网络篇—监测网络状态
- 用Java实现基于SOAP的XML文档网络传输及远程过程调用(RPC)
- kvm配置网络
- 【读书笔记】:哈工大软件学院计算机网络期末复习概要
- 未能从程序集“System.ServiceModel”中加载类型“System.ServiceModel.Activation.HttpModule”。
- 未能从程序集“System.ServiceModel”中加载类型“System.ServiceModel.Activation.HttpModule”。
- 浅谈单片机以太网接入方案
- [IIS] 不能加载类型System.ServiceModel.Activation.HttpModule
- WebService SOAP、Restful和HTTP(post/get)请求区别
- Android连接服务器请求架包之 Async-http-client
- 《读书笔记》系列2:TCP/IP详解
- Http通讯
- HttpClient调用第三方接口 底层代码的封装 方便以后使用
- ios 机型检测和网络检测
- 网络舆情分析技术 读书笔记2
- kali攻防第4章 内网称霸之HTTP信息截取
- C# 之httpwatch 缩减HttpWatch成可以进行二次开发的代码
- java基础之网络(UDP-Socket)
- 我的HttpClients工具
- Xcode7 HTTP无法获取数据的解决办法(不能用HTTP要用HTTPS的解决办法)