初步解析内核函数copy_to_user和copy_from_user
2015-11-24 19:59
609 查看
(转载的一篇好文,自己又稍微整合了一下)
首先解决一个问题:
1. 为什么要划分为内核空间和用户空间?
Linux Kernel是操作系统的核心,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。
对于Kernel这么一个高安全级别的东西,显然是不容许其它的应用程序随便调用或访问的,所以需要对Kernel提供一定的保护机制,这个保护机制用来告诉那些应用程序,你只可以访问某些许可的资源,不许可的资源是拒绝被访问的,于是就把Kernel和上层的应用程序抽像的隔离开,分别称之为Kernel Space和User Space。
2. 用户空间的程序如何对内核空间进行访问?
上面说到用户态和内核态是两个隔离的空间,虽然从逻辑上被抽像的隔离,但无可避免的是,总是会有那么一些用户空间需要访问内核空间的资源,怎么办呢?
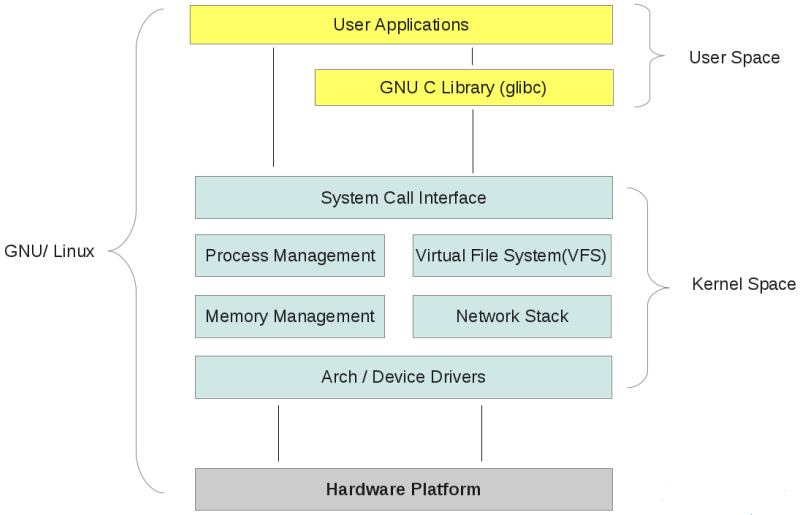
http://blog.csdn.net/ysgjiangsu/article/details/49995229
从上图结构中可以看出,Kernel Space层从下至上包括:
Arch:对应Kernel里arch目录,含有诸如x86, ia64, arm, s390等体系结构的支持;
Device Driver:对应Kernel里drivers目录,含有block, char, net, usb等不同硬件驱动的支持;
在Arch和Driver之上,是对内存,进程,文件系统,网络协议栈等的支持;
最上一层是System Call Interface,系统调用接口,正如其名,这层就是用户空间与内核空间的桥梁,用户空间的应用程序通过System Call这个统一入口来访问系统中的硬件资源,通过此接口,所有的资源访问都是在内核的控制下执行,以免导致对用户程序对系统资源的越权访问,从而保障了系统的安全和稳定。
3.copy_to_user()在内核定义如下:
其功能是将内核空间的内容复制到用户空间,所复制的内容是从from来,到to去,复制n个位。 其中又牵扯到两个函数:access_ok()和__copy_to_user(),好我们继续往下深入,先来看看第一个函数access_ok()的源码:
其功能是检查用户空间是否合法,它的第一个参数:type,有两种 类型:VERIFY_READ 和VERIFY_WRITE,前者为可读,后者可写,注意:如果标志为可写(VERIFY_WRITE)时,必然可读!因为可写是可读的超集 (%VERIFY_WRITE is a superset of %VERIFY_READ)。
检查过程如下:addr为起始地址,size为所要复制的大小,那么从addr到addr+size则是所要检查的空间,如果它的范围在memory_start和memory_end之间的话,则返回真。至于memory_start详细信息,我没有读。
到此为止,如果检查合法,那么OK,我们来实现真正的复制功能:__copy_to_user(),其源码定义如下:
又遇到一个函数:__copy_user(),这个函数才真正在做底层的复制工作
__copy_user
宏__copy_user在include/asm-i386/uaccess.h中定义,是作为从用户空间和内核空间进行内存复制的关键。这个宏扩展为汇编后如下:
这段代码的主要操作就是004-007行,它的主要功能是将from处长度为size的数据复制到to处。
看这段代码之前,先看看它的约束条件:
017 : “=&c”(size), “=&D” (__d0), “=&S” (__d1)
018 : “r”(size & 3), “0”(size / 4), “1”(to), “2”(from)
019 : “memory”);
017是输出部,根据描述可知size保存在ecx中,__d0保存在DI中,__d1保存在SI中。
018是输入部,根据描述可知size/4(即size除以4后的整数部分)保存在ecx中,size&3(即size除以4的余数部分)随便保存在某一个寄存器中,to保存在DI中,from保存在SI中。
然后再反过头来看004-007行,就明白了:
004行:将size/4个4字节从from复制到to。为了提高速度,这里使用的是movsl,所以对size也要处理一下。
005行:将size&3,即size/4后余下的余数,复制到ecx中。
006行:根据ecx中的数量,从from复制数据到to,这里使用的是
b06a
movsb。
007行:代码结束。
到这里,复制就结束了。
但是实际上没有这么简单,因为还可能发生复制不成功的现象,所以008-016行的代码都是进行此类处理的。
内核提供了一个意外表,它的每一项的结构是(x,y),即如果在地址x上发生了错误,那么就跳转到地址y处,这里行012-015就是利用了这个机制在编译时声明了两个表项。将这几行代码说明如下:
012行:声明以下内容属于段__ex_table。
013行:声明此处内容4字节对齐。
014行:声明第一个意外表项,即如果在标志0处出错,就跳转到标志3处(.section .fixup段中)。
015行:声明第二个意外表项,即如果在标志1处出错,就跳转到标志2处(.section .text段中)。
上面之所以要在标志后面加上b,是因为引用之前的代码,如果要引用之后的代码就加f。
这里对size的操作约定是:如果复制失败,则size中保留的是还没有复制完的数据字节数。
由于复制数据的代码只有4行,其中可能出现问题的就是004和006行。从上面的异常表可以看出,内核的处理策略是:
(1) 如果在0处出错,那么这时没有复制完的字节数就是ecx中剩余的数字乘以4加上先前size除以4以后的那个余数。009行代码即完成此任务,“lea 0(%3,%0,4),%0”即计算“%ecx = (size % 4) + %ecx * 4”,并将这个数值赋值给返回C代码的size中。
(2)如果在1处出现错误,那么由于之前ecx中的size/4个字节都已经复制成功了,所以只需要将保存在任意一个寄存器中的size/4的余数赋值给size返回。
从汇编代码中可以看到,009行的异常处理代码被编译到一个叫做fixup的段中。
可见这段代码的本质就是从from复制数据到to,并对两处可能出现错误的地方进行简单的异常处理——返回未复制的字节数。
注意:
(1).section .fixup,”ax”;.section __ex_table,”a”;
将这两个.section和.previous中间的代码汇编到各自定义的段中,然后跳回去,将这之后的的代码汇编到.text段中,也就是自定义段之前的段。.section和.previous必须配套使用。
(2)例子中__ex_table异常表的安排在用户空间是不会得到执行的,它只在内核中有效。
(3) 将.fixup段和.text段独立开来的目的是为了提高CPU流水线的利用率。熟悉体系结构的读者应该知道,当前的CPU引入了流水线技术来加快指令的 执行,即在执行当前指令的同时,要将下面的一条甚至多条指令预取到流水线中。这种技术在面对程序执行分支的时候遇到了问题:如果预取的指令并不是程序下一 步要执行的分支,那么流水线中的所有指令都要被排空,这对系统的性能会产生一定的影响。在我们的这个程序中,如果将.fixup段的指令安排在正常执行 的.text段中,当程序执行到前面的指令时,这几条很少执行的指令会被预取到流水线中,正常的执行必然会引起流水线的排空操作,这显然会降低整个系统的 性能。
首先解决一个问题:
1. 为什么要划分为内核空间和用户空间?
Linux Kernel是操作系统的核心,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。
对于Kernel这么一个高安全级别的东西,显然是不容许其它的应用程序随便调用或访问的,所以需要对Kernel提供一定的保护机制,这个保护机制用来告诉那些应用程序,你只可以访问某些许可的资源,不许可的资源是拒绝被访问的,于是就把Kernel和上层的应用程序抽像的隔离开,分别称之为Kernel Space和User Space。
2. 用户空间的程序如何对内核空间进行访问?
上面说到用户态和内核态是两个隔离的空间,虽然从逻辑上被抽像的隔离,但无可避免的是,总是会有那么一些用户空间需要访问内核空间的资源,怎么办呢?
http://blog.csdn.net/ysgjiangsu/article/details/49995229
从上图结构中可以看出,Kernel Space层从下至上包括:
Arch:对应Kernel里arch目录,含有诸如x86, ia64, arm, s390等体系结构的支持;
Device Driver:对应Kernel里drivers目录,含有block, char, net, usb等不同硬件驱动的支持;
在Arch和Driver之上,是对内存,进程,文件系统,网络协议栈等的支持;
最上一层是System Call Interface,系统调用接口,正如其名,这层就是用户空间与内核空间的桥梁,用户空间的应用程序通过System Call这个统一入口来访问系统中的硬件资源,通过此接口,所有的资源访问都是在内核的控制下执行,以免导致对用户程序对系统资源的越权访问,从而保障了系统的安全和稳定。
3.copy_to_user()在内核定义如下:
/**
* copy_to_user: - Copy a block of data into user space.
* @to: Destination address, in user space.
* @from: Source address, in kernel space.
* @n: Number of bytes to copy.
*
* Context: User context only. This function may sleep.
*
* Copy data from kernel space to user space.
*
* Returns number of bytes that could not be copied.
* On success, this will be zero.
*/
unsigned long
copy_to_user(void __user *to, const void *from, unsigned long n)
{
if (access_ok(VERIFY_WRITE, to, n))
n = __copy_to_user(to, from, n);
return n;
}其功能是将内核空间的内容复制到用户空间,所复制的内容是从from来,到to去,复制n个位。 其中又牵扯到两个函数:access_ok()和__copy_to_user(),好我们继续往下深入,先来看看第一个函数access_ok()的源码:
/* access_ok: - Checks if a user space pointer is valid
* @type: Type of access: %VERIFY_READ or %VERIFY_WRITE. Note that
* %VERIFY_WRITE is a superset of %VERIFY_READ - if it is safe
* to write to a block, it is always safe to read from it.
* @addr: User space pointer to start of block to check
* @size: Size of block to check
*
* Context: User context only. This function may sleep.
*
* Checks if a pointer to a block of memory in user space is valid.
*
* Returns true (nonzero) if the memory block may be valid, false (zero)
* if it is definitely invalid.
*
* Note that, depending on architecture, this function probably just
* checks that the pointer is in the user space range - after calling
* this function, memory access functions may still return -EFAULT.
*/
#ifdef CONFIG_MMU
#define access_ok(type,addr,size) (likely(__range_ok(addr,size) == 0))
#else
static inline int access_ok(int type, const void *addr, unsigned long size)
{
extern unsigned long memory_start, memory_end;
unsigned long val = (unsigned long)addr;
return ((val >= memory_start) && ((val + size) < memory_end));
}
#endif /* CONFIG_MMU */其功能是检查用户空间是否合法,它的第一个参数:type,有两种 类型:VERIFY_READ 和VERIFY_WRITE,前者为可读,后者可写,注意:如果标志为可写(VERIFY_WRITE)时,必然可读!因为可写是可读的超集 (%VERIFY_WRITE is a superset of %VERIFY_READ)。
检查过程如下:addr为起始地址,size为所要复制的大小,那么从addr到addr+size则是所要检查的空间,如果它的范围在memory_start和memory_end之间的话,则返回真。至于memory_start详细信息,我没有读。
到此为止,如果检查合法,那么OK,我们来实现真正的复制功能:__copy_to_user(),其源码定义如下:
static inline __kernel_size_t __copy_to_user(void __user *to, const void *from,
__kernel_size_t n)
{
return __copy_user((void __force *)to, from, n);
}又遇到一个函数:__copy_user(),这个函数才真正在做底层的复制工作
__copy_user
宏__copy_user在include/asm-i386/uaccess.h中定义,是作为从用户空间和内核空间进行内存复制的关键。这个宏扩展为汇编后如下:
000 #define __copy_user(to,from,size)
001 do {
002 int __d0, __d1;
003 __asm__ __volatile__(
004 "0: rep; movsl\n"
005 " movl %3,%0\n"
006 "1: rep; movsb\n"
007 "2:\n"
008 ".section .fixup,\"ax\"\n"
009 "3: lea 0(%3,%0,4),%0\n"
010 " jmp 2b\n"
011 ".previous\n"
012 ".section __ex_table,\"a\"\n"
013 " .align 4\n"
014 " .long 0b,3b\n"
015 " .long 1b,2b\n"
016 ".previous"
017 : "=&c"(size), "=&D" (__d0), "=&S" (__d1)
018 : "r"(size & 3), "0"(size / 4), "1"(to), "2"(from)
019 : "memory");
020 } while (0)这段代码的主要操作就是004-007行,它的主要功能是将from处长度为size的数据复制到to处。
看这段代码之前,先看看它的约束条件:
017 : “=&c”(size), “=&D” (__d0), “=&S” (__d1)
018 : “r”(size & 3), “0”(size / 4), “1”(to), “2”(from)
019 : “memory”);
017是输出部,根据描述可知size保存在ecx中,__d0保存在DI中,__d1保存在SI中。
018是输入部,根据描述可知size/4(即size除以4后的整数部分)保存在ecx中,size&3(即size除以4的余数部分)随便保存在某一个寄存器中,to保存在DI中,from保存在SI中。
然后再反过头来看004-007行,就明白了:
004行:将size/4个4字节从from复制到to。为了提高速度,这里使用的是movsl,所以对size也要处理一下。
005行:将size&3,即size/4后余下的余数,复制到ecx中。
006行:根据ecx中的数量,从from复制数据到to,这里使用的是
b06a
movsb。
007行:代码结束。
到这里,复制就结束了。
但是实际上没有这么简单,因为还可能发生复制不成功的现象,所以008-016行的代码都是进行此类处理的。
内核提供了一个意外表,它的每一项的结构是(x,y),即如果在地址x上发生了错误,那么就跳转到地址y处,这里行012-015就是利用了这个机制在编译时声明了两个表项。将这几行代码说明如下:
012行:声明以下内容属于段__ex_table。
013行:声明此处内容4字节对齐。
014行:声明第一个意外表项,即如果在标志0处出错,就跳转到标志3处(.section .fixup段中)。
015行:声明第二个意外表项,即如果在标志1处出错,就跳转到标志2处(.section .text段中)。
上面之所以要在标志后面加上b,是因为引用之前的代码,如果要引用之后的代码就加f。
这里对size的操作约定是:如果复制失败,则size中保留的是还没有复制完的数据字节数。
由于复制数据的代码只有4行,其中可能出现问题的就是004和006行。从上面的异常表可以看出,内核的处理策略是:
(1) 如果在0处出错,那么这时没有复制完的字节数就是ecx中剩余的数字乘以4加上先前size除以4以后的那个余数。009行代码即完成此任务,“lea 0(%3,%0,4),%0”即计算“%ecx = (size % 4) + %ecx * 4”,并将这个数值赋值给返回C代码的size中。
(2)如果在1处出现错误,那么由于之前ecx中的size/4个字节都已经复制成功了,所以只需要将保存在任意一个寄存器中的size/4的余数赋值给size返回。
从汇编代码中可以看到,009行的异常处理代码被编译到一个叫做fixup的段中。
可见这段代码的本质就是从from复制数据到to,并对两处可能出现错误的地方进行简单的异常处理——返回未复制的字节数。
注意:
(1).section .fixup,”ax”;.section __ex_table,”a”;
将这两个.section和.previous中间的代码汇编到各自定义的段中,然后跳回去,将这之后的的代码汇编到.text段中,也就是自定义段之前的段。.section和.previous必须配套使用。
(2)例子中__ex_table异常表的安排在用户空间是不会得到执行的,它只在内核中有效。
(3) 将.fixup段和.text段独立开来的目的是为了提高CPU流水线的利用率。熟悉体系结构的读者应该知道,当前的CPU引入了流水线技术来加快指令的 执行,即在执行当前指令的同时,要将下面的一条甚至多条指令预取到流水线中。这种技术在面对程序执行分支的时候遇到了问题:如果预取的指令并不是程序下一 步要执行的分支,那么流水线中的所有指令都要被排空,这对系统的性能会产生一定的影响。在我们的这个程序中,如果将.fixup段的指令安排在正常执行 的.text段中,当程序执行到前面的指令时,这几条很少执行的指令会被预取到流水线中,正常的执行必然会引起流水线的排空操作,这显然会降低整个系统的 性能。

相关文章推荐
- bzoj:1621 [Usaco2008 Open]Roads Around The Farm分岔路口
- 自定义Linux 内核驱动模块的编译
- Nginx模块管理和进程管理
- Linux ldconfig命令
- linux 进线程间通信
- 在linux的环境下 连接深澜校园网的方法
- 如何确定LDA的topic个数
- Linux学习 - Ubuntu 14.04配置Opencv环境
- nginx正则
- IDEA tomcat内存溢出
- Linux进程调度策略
- OpenJudge_P1776 木材加工
- Laravel 5.1 超级大坑 CentOS 7 文件路径大小写敏感造成的Migrate异常
- 【学神-RHEL6.5】1-17 shell基础及if表达式
- python 从shell读取指定文件以及写入指定文件
- Deep learning:四十一(Dropout简单理解)
- 为tomcat 创建定时 任务 关闭 重启
- xmppframework在openfire下总是密码验证不通过
- linux socket
- tomcat内部运行原理浅析--转载