ACM_lca
2015-11-21 10:52
411 查看
前言
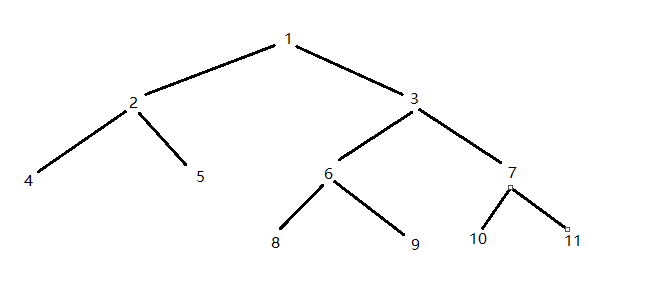
lca(Least Common Ancestors) : 最近公共祖先, 一般题目的是给你一棵树(当然也有些题不会直接给你)题目的解法大多会让你向上找两个点的最近公共祖先, 比如上图的4 和 5的公共祖先是2, 9 和 7 的公共祖先是3, 3 和 8的公共祖先是3, 搭配的可能就还有一些其他的问题, 比如两点间的最短距离(边有权值, 而且边的权值可能会变) 或者搭配树形DP类似的东西
lca的解法我现在了解的有5种:
lca的5种解法
暴力: 复杂度O(n) 适合查询不多的情况比较直接的方法, 它的适用范围在与询问很少的时候, 思想也很简单, 我们需要知道两个东西:
1.每个点的父亲(因为是树, 所以每个点的父亲只有1个)
2 每个点的深度, 就是DFS的时候它的深度, 比如上图中1的深度是0 然后 2和3的深度是1 然后 4, 5, 6, 7的深度是2…….(我是从0开始算的, 当然1也是ok的)
知道这两个东西之后 现在我们查找一对数的lca 只需要把他们先提升到同一深度, 然后2个数一起向上, 直到两个数相等, 那么这个相等的数就是他们的lca
还是这个图
比如我们找8和7的lca(方便描述假如x = 8, y = 7, x, y是变量)
1.找到每个点的父亲和深度
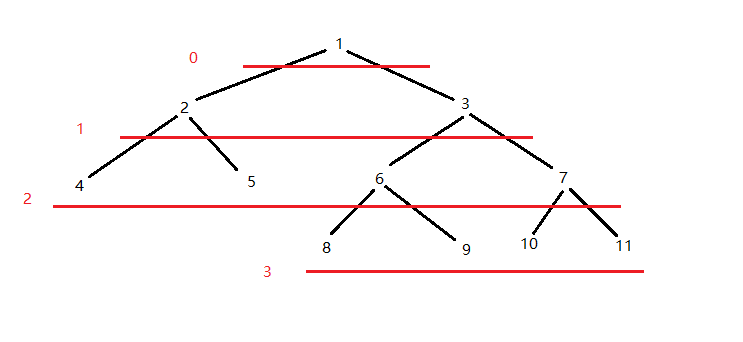
如图
2.把他们提到同一深度
我们发现8的深度更深, 于是把8向上提, x = pa[8] = 6
再检查我们发现x和y的深度一样了(都是2)
3.向上找公共祖先
把他们一起向上提直到x == y
所以操作是x = pa[x] = 3, y = pa[y] = 3;
此时发现x == y了, 好了那么此时的x(也就是3) 就是他们的公共祖先了
大致代码如下:
第一个: 找深度和父亲的DFS:
void dfs(int u, int f, int d) {
dep[u] = d;
for(int i = 0; i < son[u].size(); ++i) {
int v = son[u][i];
if(v == f) continue;
dfs(v, u, d+1);
pa[v] = u;
}
}我这里用的是邻接表存的, 当然也可以用其他方式, 链式前向星其实不错, 貌似更快?
第二个:找lca
int lca(int x, int y) {
if(dep[x] < dep[y]) swap(x, y);
while(dep[x] > dep[y]) x = pa[x];
while(x != y) {
x = pa[x];
y = pa[y];
}
return x;
}如此 只要调用lca(7, 8) 就可以找到7和8的lca了;
由于dfs每个点只访问一次, 找父亲最多找n(点的个数)次, 所以复杂度是O(n)
倍增: 建图的时候复杂度是O(nlongn)查询的时候是O(logn)
倍增就是二分的思想, 和第一种的暴力有很多相似的地方, 不过优化了而已
倍增的变量一般有一下几个: dep[x]表示x的深度, pa[i][x]表示x的向上的第2^i个父亲, 比如pa[1][x]表示的就是x的父亲的父亲(x的爷爷) 它的值就等于pa[0][pa[0][x]]
倍增一般分为以下几步:
1.同样的找到每个点的深度和父亲(这里的父亲指的是pa[0][x])
void dfs(int u, int f, int d) {
dep[u] = d;
for(int i = 0; i < son[u].size(); ++i) {
int v = son[u][i];
if(v == f) continue;
dfs(v, u, d+1);
pa[0][v] = u;
}
}是的没错基本上就是方法一的那种dfs, 其实5种lca基本上都有这一步
void doubling() {
for(int i = 1; i < K; i++) {
for(int j = 1; j <= n; j++) {
if(pa[i-1][j] == 0 || pa[i-1][pa[i-1][j]] == 0) pa[i][j] = 0;
else pa[i][j] = pa[i-1][pa[i-1][j]];
}
}
}32 - __builtin_clz(n)的意义: __builtin_clz(n)的函数是数n的二进制下有多少个前导0 用32 - 这个数就得到i 这样一来2^i >= n;
这个应该不难理解, 就是不停的向上找他的上一辈的上一辈, 如果没有这一辈, 把它设位0
3.查询
int lca(int x, int y) {
if(dep[x] < dep[y]) swap(x, y);
for(int i = K-1; ~i; i--) {
if(dep[pa[i][x]] > dep[y])
x = pa[i][x];
}
if(dep[x] != dep[y]) x = pa[0][x];
for(int i = K-1; ~i; i--) {
if(pa[i][x] != pa[i][y])
x = pa[i][x], y = pa[i][y];
}
if(x != y) x = pa[0][x], y = pa[0][y];
return x;
}这个查找第一步是先把他们找到同一深度
也是就
for(int i = K-1; ~i; i--) {
if(dep[pa[i][x]] > dep[y])
x = pa[i][x];
}
if(dep[x] != dep[y]) x = pa[0][x];
}K = 32 - __builtin_clz(n) 的意义: __builtin_clz(n)的函数是数n的二进制下有多少个前导0 用32 - 这个数就得到i 这样一来2^i >= n;
后面那个if判断是因为他们一进来可能就已经在同一深度了
然后找祖先:
也就是
if(dep[x] != dep[y]) x = pa[0][x];
for(int i = K-1; ~i; i--) {
if(pa[i][x] != pa[i][y])
x = pa[i][x], y = pa[i][y];
}
if(x != y) x = pa[0][x], y = pa[0][y];为什么可以这么找呢? 因为两个数向上找的时候, 只有找到了他们的祖先, 那么这个数的祖先肯定也是这两个数的祖先, 所以这两个数的祖先依次就是(用0代表不是祖先, 1 代表是祖先) 0 0 0 0 0 1 1 1 1 1 1我们不停的向上找那个0最好找到的就正好是最近祖先下面的那个0 再提升一步就可以了(还有一种情况就是x和y已经相等了, 这也就是后面那个if的特判的道理了)
如此一来返回的值就是这两个数的lca了
复杂度因为建立关系的时候每个点都访问了一次, 而且都是二分, 所以建立的时候的复杂度是O(nlongn) 而查询的时候因为都是二分查找, 所以复杂度是O(logn)
PS:感觉倍增比其他的要灵活一点啊, 当然也可能是我算法理解的渣
线段树的rmq找lca: 建立关系的复杂度是O(nlongn), 查找的时候是O(1)
这个是对DFS的一种强大的利用吧 首先看一下DFS是怎么跑这个图的
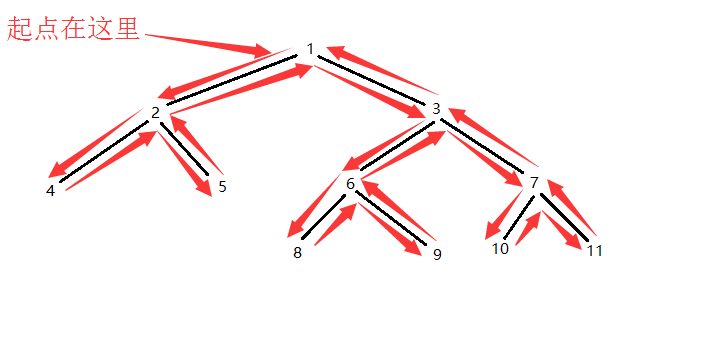
还是之前的那个图, DFS的跑图的顺序按箭头所示方向一次遍历下去, 然后我们发现一个现象 比如4和5的LCA: 我们发现2->4->2->5, 这时候只需要找2->4->2-5的最小深度就OK了, 再来个例子, 注意DFS的跑图顺序, 比如7和8 DFS跑图的时候的顺序是3->6->8->6->9->6->3->7->10->7->8我们只需要找到这一段的最小深度(也就是dep[3])就行了, 这个3就是7和8的LCA了, (在这一段里没有比dep[3]更小的dep了)
所以我们只要按DFS跑的顺序再建一个序列, 求两个数之间的最小dep就OK了
比如我们建立了如下的序列
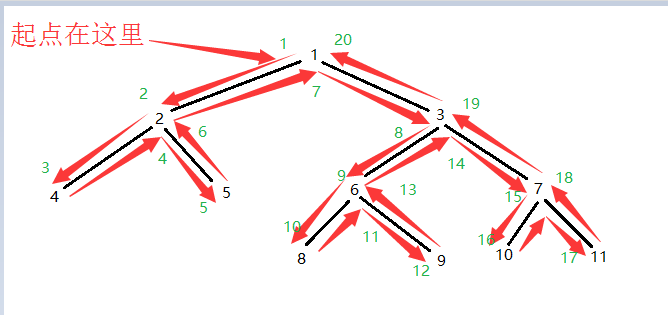
图中绿色的字代表了DFS跑的顺序, 现在我们假如查找7和8的LCA, 只要找到7和8第一次在DFS中的编号, 7的编号是18 8的编号是10, 也就是说, 现在我们只要找到10 到 18 这一段区间的最小的dep所对应的节点就OK了, 这个节点就是7和8的LCA
首先N代表最多的点数
线段数的RMQ 需要的变量稍微就多了一点了:
dfsnum:表示跑DFS的顺序, 对应生成的序列
vs[N << 1]:代表拜访到这个dfsnum的时候对应的节点, 因为我们最好要的是节点不是DFSNUM;
first
: 代表第一次访问到这个节点对应的DFSNUM
dep[N << 1]:代表对应DFSNUM的深度 要根据这个来找LCA
一个sparsetable:下面说
需要的函数如下:
建关系:
void dfs(int u, int d) {
vis[u] = 1;
vs[++dfsnum] = u;
dep[dfsnum] = d;
first[u] = dfsnum;
for(int i = 0; i < son[u].size(); i++) {
if(!vis[v]) {
dfs(v, d+1);
vs[++dfsnum] = u;
dep[dfsnum] = d;
}
}
}对应变量的意义已经给出, 这个只是实现
2.sparsetable: 这个表是用来查找最小的dep所对应的DFSNUM;
int getmin(int x, int y) {
return dep[x] < dep[y]? x : y;
}struct sparsetable {
int dp[20][N << 1];
void init(int n) {
for(int i = 1; i <= n; i++) dp[0][i] = i;
for(int i = 1; (1 << i) <= n; i++)
for(int j = 1; j + (1 << i) - 1 <= n; j++)
dp[i][j] = getmin(dp[i-1][j], dp[i-1][j+(1<<i-1)]);
}
int rmq(int l, int r) {
int k = 31 - __builtin_clz(r-l+1);
return getmin(dp[k][l], dp[k][r-(1<<k)+1]);
}
} st;这个表和上面的getmin配合使用, 因为你要的不是最小dep而是最小dep对应的dfsnum, 所以这个getmin函数非要不可
在sparsetable中的初始化中有几个变量
dp[i][j]代表的是从j开始在[j, j + 2^)这个区间里的最小dep对应的dfsnum(这个区间左闭右开) 不断用之前的更新之后的, 知道更新完整个区间, 比如我要更新dp[1][2] 就用dp[0][2] 和dp[0][1]更新, 对应的区间就是: [2, 4)区间用[2, 3)和[3, 4)区间更新
在rmq里的查询, 不是线段树的那种一层一层的向下查询了而是直接找最小值就OK了 比如我要找[1, 5]的最小值 那么我只要找[1, 5)和[2, 6)的最小值就OK了(注意区间开闭) 那个k代表的意义就是把区间切成两块对应的2^x k就等于这个x 具体手算一下就OK了
最后一个函数 lca
int lca(int x, int y) {
if(first[x] > first[y]) swap(x, y);
int idx = st.rmq(first[x], first[y]);
return vs[idx];
}直接从first[x], first[y]里面得到第一次访问的dfsnum 然后在sparsetable用rmq找到对应的最小dep的dfsnum, 而vs里面记录了dfsnum和节点的对应关系, 返回就OK了;
复杂度, 由于建关系的时候每个点都访问了一次, 每个区间都是二分倍增(主要在sparsetable结构体里)所以复杂度是O(nlongn) 查询的时候由于直接找两个区间就OK了 所以复杂度是O(1)
Tarjan求lca:还不是很清楚, 只知道个大概, 估计也说不对, 下次再来吧
树链剖分, 好像是很神奇的东西, 看了一下, 下次来…..
关于求距离
如果加入了边权求距离, 只需要在关系中加入dis[i]就可以了, 表示有根到i点的距离, 算x, y的距离 d = dix[x] + dis[y] - 2 * dis[lca(x, y)] 想想就能明白不过倍增发我试过用其他的也可以
线段数的LCA也可以用另外的方式求: 再向下遍历的时候加正边, 回溯的时候加负边,查询两个数对应的dfsnum(也就是first[x], first[y])之间的区间和就OK了, 需要更新边权的时候比较方便吧;
总结
算法简单 题难啊!(好像算法也不是那么简单?) 还是要多练啊, 发现还是有很多题遇见了就变傻逼了具体例题在后面

相关文章推荐
- LCA模板
- 【LCA】SPOJ QTREE2
- poj3728
- hihocoder #1067 LCA
- hihocoder #1069 线段树
- POJ1330 Nearest Common Ancestors 非lca pascal 解题报告
- POJ1986 Distance Queries LCA pascal 解题报告
- LCA
- Lowest Common Ancestor (LCA) of two nodes in graph
- Codevs 2370 小机房的树 LCA 树上倍增
- Codevs 3287 货车运输
- HDU 3078 Network LCA .
- 并查集求最近公共祖先
- 【P1843】货车运输(最大生成树+LCA)
- POJ 1330 LCA入门题(Tarjan)
- LeetCode 236: Lowest Common Ancestor of a Binary Tree
- LeetCode 235: Lowest Common Ancestor of a Binary Search Tree
- POJ 1986 Distance Queries
- SPOJ COT 10628 Count on a tree
- bzoj-3123 森林